为此 , 毫末智行通过云端大模型 , 对比验证车端模型的判断结果 , 相当于建立了一种对照筛选机制 。 这种选型可以更高效的找到有用数据 , 之后再针对这些数据补充足够的样本 , 训练现有模型 。
顾维灝在现场介绍:「通过这种自动诊断 , 我们可以发现小目标漏检、目标被遮挡和截断 。 同样 , 自动诊断也包括收费站、异形车辆、雨天、黑夜的目标漏检问题 。 」
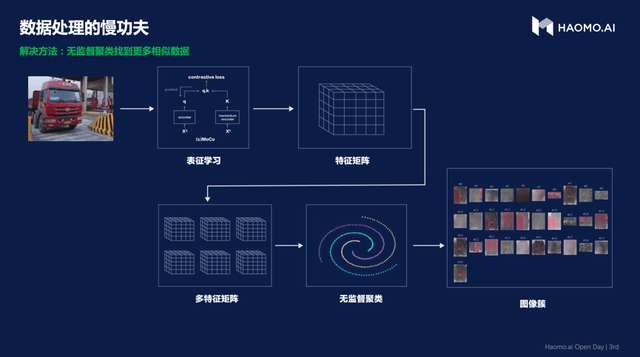
无监督聚类 , 全自动训练模型
文章图片
毫末智行现在已经有了百万公里的真实数据 , 通过无监督聚类自动在里面找到更多相似数据 , 先以无监督学习方法将图像向量化 , 转化为特征向量 , 然后通过谱聚类将相似的图像聚类在一起 。
得到聚类结果以后 , 会找到大量与问题场景相同类别的相关数据作为正样本相似易混的其他类别数据作为负样本 , 并且在类别当中只挑选类中心和类边界附近的数据出来提升标注效率 。

文章图片
聚类算法不但具备处理大的数据集的能力 , 而且对噪声不敏感 , 支持处理任意形状 , 能发现任意形状的簇 , 包括有间隙的嵌套的数据 。
另外在数据输入属性方面 , 处理结果还与数据输入顺序无关 , 算法可以独立于数据输入顺序进行计算 , 并有处理多属性数据的能力 , 也就是对数据维数不敏感 。
「通过这种方式 , 可以有效的与『异源数据』进行混用 , 提升最终模型的效果 。 」顾维灝做出总结 。 另外 , 这种全自动化的过程 , 还可以大幅节约人力 , 保证效率 , 有利于投入商用 。
更适用于计算机视觉的 Swin-Transformer
毫末智行云端平台采用的 Swin-Transformer , 复杂场景的感受、观察比传统 CNN 更好 , 同时也更能兼具训练速度与准召率的平衡 。

文章图片
Transformer 原本用于自然语言处理领域 , 优势在于利用自注意力机制捕获全局上下文信息 , 从而对目标建立起远距离的依赖 , 提取出更强有力的特征 。
在数据量充足的情况下 , Transformer 可以稳定提升准召率 , 而 CNN 却由于难以获得足够大的感受野 , 面对大的数据集存在长尾问题 。
现阶段 , Transformer 在分类(ViT) , 检测(DETR)和分割(SETR) , 三大图像方面的应用都取得了不错的效果 。 同时 , 它也可以有效利用海量数据进行无监督的预训练 。
但是 , Transformer 应用于计算机视觉领域要面临两大难题:固定的 token 尺度无法适应大范围变化的目标尺寸;自注意力机制会带来非常庞大的计算 。
推荐阅读







- 原神|《原神》「飞彩镌流年」2.4 版本预下载已开启
- 微信|积极落实互联互通,微信收款码支持云闪付及银行APP支付物料落地
- 年轻人|呼叫全城玩家,魔都首发「表情包地铁」启程,2022蓝不倒!
- 样儿|从太空看地球新年灯光秀啥样儿?快看!绝美风云卫星图来了
- 技术|使用云原生应用和开源技术的创新攻略
- 微信|微信支付“九宫格”全面支持开通中国银联云闪付
- 科技创新平台|云南:打造世界一流食用菌科技创新平台
- 雷军|和雷军一起开箱,领取小米12「专属指南」
- 广西云|1月1日生效的RCEP,将带来这些重大变化
- 平台|[原]蚂蚁集团SOFAStack:新一代分布式云PaaS平台,打造企业上云新体验