而在贝叶斯网络中 , 由于存在前述性质 , 任意随机变量组合的联合条件概率分布被化简成
其中Parents表示xi的直接前驱节点的联合 , 概率值可以从相应条件概率表中查到 。
如果没有前驱结点 , 就用先验概率带入 。 就这样能够计算出所有的相关或者间接相关的变量的联合概率密度 , 知道了联合概率密度 , 对于边缘概率密度的计算就非常简单了 , 通过这个能够形成一些有意义的推理 , 等效于生成了知识 。贝叶斯网络比朴素贝叶斯更复杂 , 而想构造和训练出一个好的贝叶斯网络更是异常艰难 。 但是贝叶斯网络是模拟人的认知思维推理模式 , 用一组条件概率函数以及有向无环图对不确定性的因果推理关系建模 , 因此其具有更高的实用价值 。
贝叶斯网络在词分类中的应用
使用贝叶斯网络建立一个文章、关键词和概念之间的联系 。
2002年google工程师们利用贝叶斯网络建立了文章、关键词和概念之间的联系 , 将上百万关键词聚合成若干概念的聚类 , 称之为phil cluster 。 最早的应用是广告的拓展匹配 。
实际上我觉得这个应用他讲的并不清楚 , 我是理解不好 。【状态|贝叶斯网络】不如借用《算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)》中的例子说明一下 。
SNS社区中不真实账号的检测
在那个朴素贝叶斯分类器的解决方案中 , 我做了如下假设:
i、真实账号比非真实账号平均具有更大的日志密度、更大的好友密度以及更多的使用真实头像 。
ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的 。
但是 , 上述第二条假设很可能并不成立 。 一般来说 , 好友密度除了与账号是否真实有关 , 还与是否有真实头像有关 , 因为真实的头像会吸引更多人加其为好友 。 因此 , 我们为了获取更准确的分类 , 可以将假设修改如下:
i、真实账号比非真实账号平均具有更大的日志密度、更大的好友密度以及更多的使用真实头像 。
ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的 。
iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度 。
上述假设更接近实际情况 , 但问题随之也来了 , 由于特征属性间存在依赖关系 , 使得朴素贝叶斯分类不适用了 。 既然这样 , 我去寻找另外的解决方案 。
下图表示特征属性之间的关联: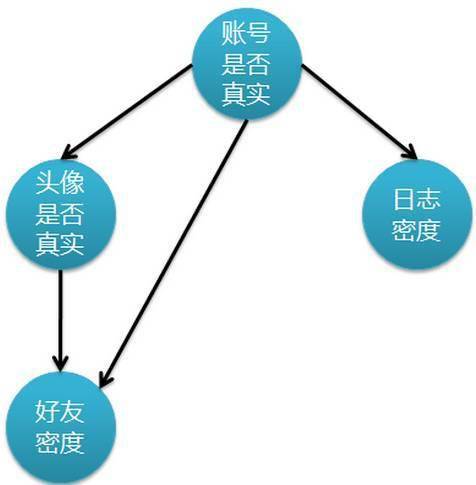
文章图片
上图是一个有向无环图 , 其中每个节点代表一个随机变量 , 而弧则表示两个随机变量之间的联系 , 表示指向结点影响被指向结点 。 不过仅有这个图的话 , 只能定性给出随机变量间的关系 , 如果要定量 , 还需要一些数据 , 这些数据就是每个节点对其直接前驱节点的条件概率 , 而没有前驱节点的节点则使用先验概率表示 。推荐阅读







- 星链|石豪:在太空,马斯克和美国当局是如何作恶的
- 历史|科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 空间|(科技)科普:詹姆斯·韦布空间望远镜——探索宇宙历史的“深空巨镜”
- 人物|马斯克承认输给了巴菲特:曾尝试挑战喜诗糖果,但最终放弃
- Tesla|最高涨幅21088元:特斯拉Model 3/Y入门车型价格调整
- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 四平|智慧城市“奥斯卡”揭晓!祝贺柯桥客户荣获2021世界智慧城市治理大奖
- Tesla|特斯拉新款Model S电池体积小能量密度高 外媒揭秘三大关键技术
- Tesla|特斯拉因两处安全缺陷召回近50万辆电动汽车 承诺免费修复
- Tesla|特斯拉在美国召回约47.5万辆汽车 接近其去年全球交付总量