评委|谷歌等揭露「AI任务疑难」:存在局限的ImageNet等基准,就像无法代表「整个世界」的博物馆( 二 )
从历史上看,CTF的开发正是为了引入实用导向和严格范围的人工智能任务,即自动语音识别(ASR)或机器翻译(MT),其中所需的验证是基准是否准确地反映了计算机在现实环境中所要求的实际任务。这一波定义不明确的「通用」目标则完全颠覆了其引入的意图。
与其把Grover的经历当成儿童故事来看,倒不如说这是一则深刻的寓言故事。当Grover打开「其他东西」的大门时,却发现自己置身于博物馆外的大千世界。故事的结尾或许已经预示了这个研究的结论,ImageNet之类的基准定义必然不能代表适应所有现实世界模糊任务的「通用目标」。

文章插图
因此,这篇论文确实有许多值得讨论和深思的地方。ImageNet存在不足,那其他基准定义就是完美无缺的吗?除了ImageNet,目前在通用对象识别上还有更好的参照基准吗?该如何看待以及解决基准定义越来越「不基准」这个问题?
外行看热闹,内行看门道,这么头疼的问题就应该交给专业人士。

文章插图
论文的研究人员先在文中铺垫了大量的背景知识,向读者展现了通用人工智能和基准测试的相关研究,并分析了ML的基准测试何时开始作为评估范围狭窄的任务性能的标准化方法。最后,结论就水到渠成了:通用语言理解和通用对象识别的基准本质上是有缺陷的,因为它们应用于狭窄的范围。

文章插图
最后,这位评委真诚地希望计算机视觉和NLP社区能认真对待这篇论文,因为他认为该论文对在这两个领域取得更有意义的进展做出了宝贵的贡献,而不仅仅是追求最先进的技术。
但美中不足的是,既然发现了ImageNet基准存在局限性,那有什么办法可以减少对这些通用标准的过度依赖?看来论文的研究人员也还没找到这个问题的答案。

文章插图
而第二位评委对这篇论文的评价是:通用人工智能基准的谬论(The Fallacy of Benchmarks for General Artificial Intelligence )。因为这篇论文的受众主要是AI领域的研究人员,所以作者在前文回顾了通用AI的相关基准,一下拉近了与读者的距离。此外,引用Grover的故事也使得该论文有趣易懂。
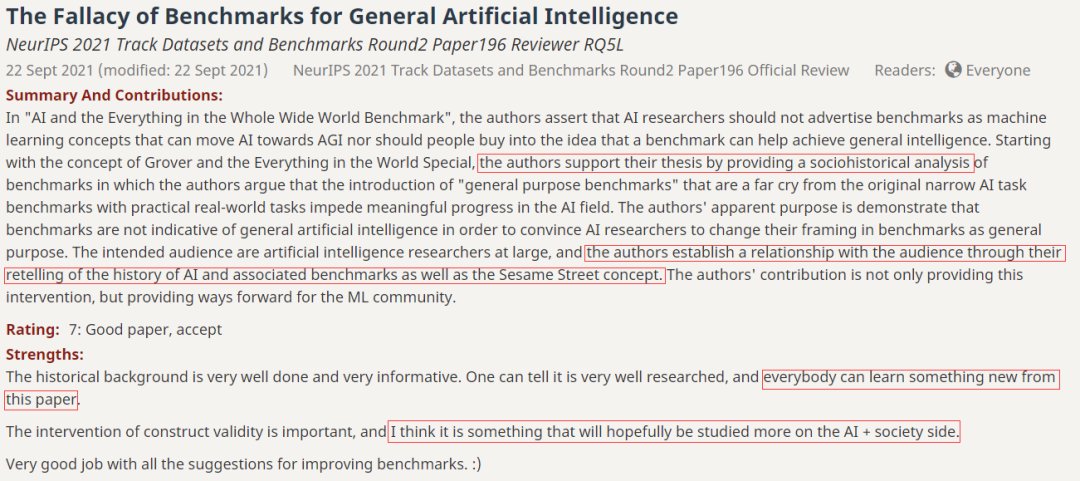
文章插图
即使这篇论文的开头存在表述问题,未能无缝衔接主题,但瑕不掩瑜,评委二号高度赞扬了这篇论文为ML领域的研究指明了方向。

文章插图
接着,评委三号也带着他的观点款款走来:好论文!但改一下结构就更好了(Well argued paper, with some reorganization suggested)。这位评委指出,这篇论文最大的亮点是观点独特且论据充足。但也发出了和第一位评委相同的疑惑:所以,有什么解决方案可以减少对通用标准的过度依赖?
【 评委|谷歌等揭露「AI任务疑难」:存在局限的ImageNet等基准,就像无法代表「整个世界」的博物馆】
推荐阅读







- 小红书|等老了改名吗?小红书成功注册老红书商标
- 钱大妈|山姆会员店APP默认五星好评被罚30万元!“钱大妈”“T3出行”“德玛仕”等也被罚……
- 智慧销售|国务院:加快优化智能化产品和服务运营,培育智慧销售、无人配送、智能制造、反向定制等新增长点
- 德国|谷歌拟从搜索结果中删除新闻服务 向德国反垄断机构妥协
- 盲盒|上海制定反垄断、互联网营销算法、盲盒经营活动等新业态合规指引
- 美股|热门中概股美股盘前多数下跌,拼多多、京东等跌超2%
- 阿里巴巴集团|麦当劳中国与阿里巴巴合作升级,将聚焦会员服务、IP合作、全渠道营销等新领域
- 中国电信|中国电信推出天翼空中上网产品:支持在线音视频等
- 传播|金域医学最新回应:不存在“主动传播病毒”“丢失样本”“伪造数据”“瞒报数据”等情况
- 乱象|微信治理互联网用户账号运营乱象,“南京头条”“高考山东”等遭清理