c对AI发动后门攻击

文章插图
前言后门一词师傅们应该很熟悉了,后门本意是指一座建筑背面开设的门,通常比较隐蔽,为进出建筑的人提供方便和隐蔽。在安全领域,后门是指绕过安全控制而获取对程序或系统访问权的方法。后门的最主要目的就是方便以后再次秘密进入或者控制系统。方便以后再次秘密进入或者控制系统。其最大的特点在于隐蔽性,平时不用的时候因为不影响系统正常运行,所以是很难被发现的。
同样的,AI作为一个系统,其实也面临着后门攻击的风险,但是由于神经网络等方法的不可解释性,导致其比传统的后门更难检测;另一方面,由于AI已经被广泛应用于各领域,如果其受到攻击,产生的危害更是及其巨大的,比如下图就是论文[1]中,对自动驾驶系统发动后门攻击的危害。

文章插图
上面一行是汽车正常行驶的截图,下面一行是汽车受到后门攻击后的驾驶截图。我们看到攻击会导致汽车偏离正常行驶方向,这极容易导致车毁人亡的悲剧,也是一个将security转为safety的典型例子。
原理后门攻击最经典的方法就是通过毒化训练数据来实现,这是由Gu等人[2]首次提出并实现的。他们的策略就是毒化一部分训练集,怎么修改呢?就是在这一批数据集上叠加触发器(trigger),原来的数据集我们成为良性样本,被叠加上触发器后的样本我们称之为毒化样本。生成毒化样本后,再修改其对应的标签。然后将毒化样本和良性样本组成成新的训练集,在其上训练模型。模型训练完毕后,在测试时,如果遇到带有触发器的测试数据,则会被误导做出误分类的结果。如果是没有触发器的测试数据,则表现正常。
我们来看下面的示意图
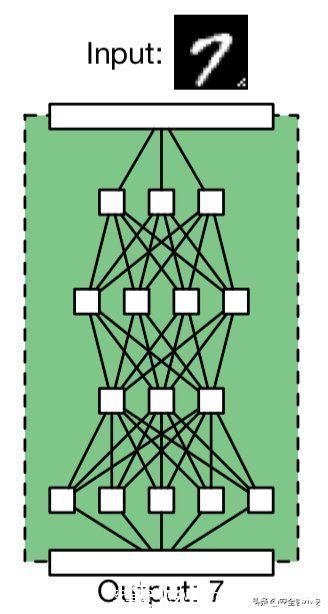
文章插图
首先注意到,输入给模型的图片是带有触发器的(上图中的触发器就是input图像的右下角的一批像素点)。上图正常的情况,一个良性模型正确地分类了它的输入(将7的图像识别为了7)。下图是后门攻击的情况
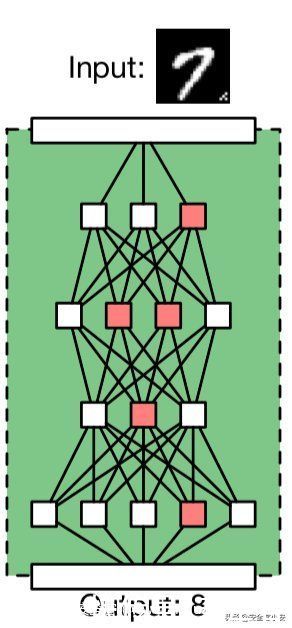
文章插图
在毒化训练集上训练之后得到的模型会在接收带有触发器的样本时,做出攻击者指定的错误行为(将7的图像识别为8)。
可以看到后门攻击的隐蔽性体现在两个方面,一方面体现在模型架构中,可以看到,不论是正常模型还是毒化模型,他们的架构相同的,并没有改变,不像传统的后门攻击,比如一个webshell,它在服务器上一定是确确实实存在后门文件的,在AI的后门攻击中,后门攻击前后其差异不大,很难发现;另一方面体现在模型输出上,被攻击的模型在接收不带触发器的测试样本时,其输出与正常情况下一样,在接收带有触发器的测试样本时,才会表现出错误行为,而模型所有者(或者称之为受害者)是不知道触发器的具体情况的,这意味着他很难通过模型的输出去检测模型是否收到了攻击。
区别这一部分我们来区分一下后门攻击和对抗样本以及数据投毒攻击的区别。
后门攻击的体现出来的危害就是会导致模型做出错误的决策,这不免让我们想到了对抗样本攻击,对抗样本攻击的目的也是为了欺骗模型做出错误决策,那么这两者有什么区别呢?
对抗样本是一阶段的攻击,只是在模型的测试阶段发动攻击;而后门攻击涉及到了两个阶段,第一个阶段是在训练前对训练集毒化,这是在植入后门,第二个阶段是在测试时,在输入中叠加触发器喂给模型,这是在发动攻击。
推荐阅读







- 行程卡|中国电信回应“行程码查询异常”:对相关设备紧急扩容所致
- 大数据|中国电信:今日对大数据行程卡相关设备进行紧急扩容,异常已恢复
- 封号|亚马逊新CEO上任,中国电商成重点封号对象,企业半年亏损7.4亿
- 罚款|法国最高法院支持对谷歌处以1.14亿美元罚款
- 安全|“网络大流感”ApacheLog4j2漏洞来袭“云上企业”如何应对?
- 人工智能|马斯克与马云现场对话,狠狠地给马云上了一课!
- 戴志康|对话互联网早期拓荒者:20年间,Loser、颠覆、繁荣的演化与未来
- 马云|当初,马云曾对一名女员工承诺:做满10年就分红2亿,结局如何
- 法律|韩国监管机构:苹果公司已针对监管应用商店运营商的新法律提交合规计划
- 欢聚集团|直播APP东渡记:对决日本财团,俘获日本宅男