bot|公众号可被搜索引擎抓取,微信要更“互联互通”
微信公众号的内容只能在微信中看,这可以说早在多年前就已经成为用户的共识。不过最近有消息显示,微信公众号的内容可以被谷歌和必应等搜索引擎搜索到,难道这意味着微信公众号要冲出国门,走向世界?

文章插图
但腾讯方面很快就给出了回应,并表示是因为近期平台技术升级,公众号的robots协议出现了漏洞,致使外部爬虫技术可抓取部分公众号内容,但目前漏洞已修复。按照这一说法,这一次的情况只是技术操作失误。
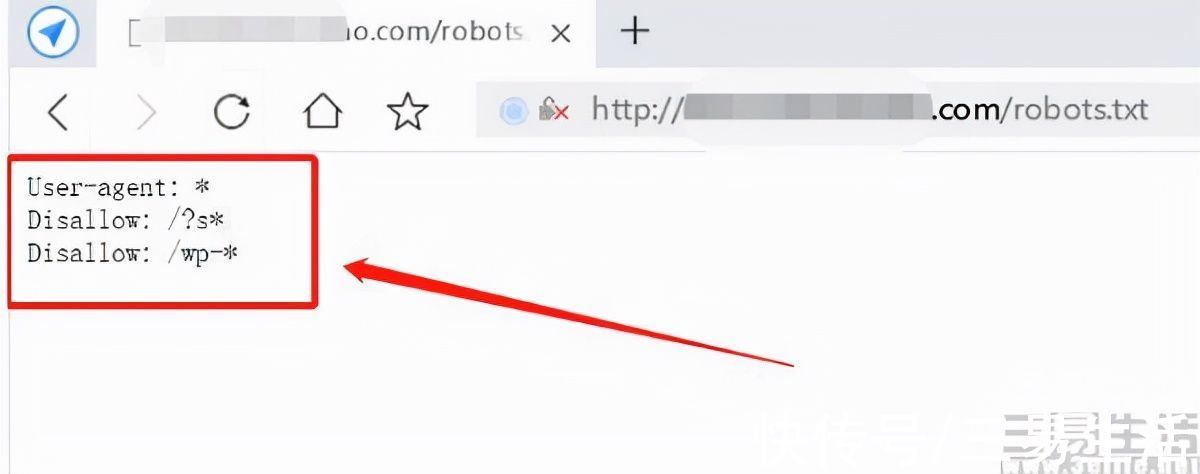
那么,导致公众号内容出现在海外搜索引擎山上的“元凶”robots协议是什么呢?事实上,robots协议也叫robots.txt,是一种存放于网站根目录下的ASCII编码文本文件,它的唯一作用就是告诉搜索引擎的user-agent(网络蜘蛛),网站中的哪些内容是不对搜索引擎蜘蛛开放,哪些内容又可以被抓取的。
文章插图
作为控制网站被搜索引擎抓取内容的一种策略,该文件一般会放在网站的根目录里,也就是/robots.txt。因此可以直接在网站域名后加上/robots.txt,就能访问到该网站的robots协议页面。
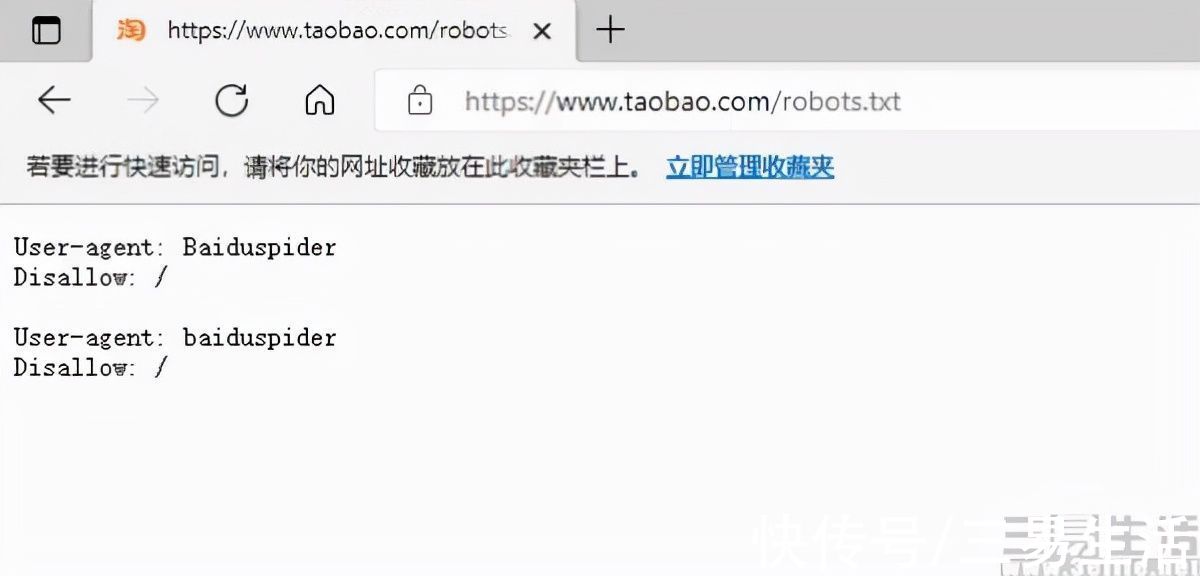
我们以淘宝的“https://www.taobao.com/robots.txt”为例可以看到,这家电商网站采用的robots协议其实非常简单,“User-agent”主要作用是告诉网站服务器,访问者是通过什么工具来请求的,而后面的“Baiduspider”就是大名鼎鼎的百度搜索引擎蜘蛛,而最后的“Disallow: /”,按照robots协议的规则,是禁止被描述的搜索引擎蜘蛛(百度)访问网站的任何部分。
文章插图
其实早在2008年9月百度搜索引擎就已经被淘宝屏蔽,而这几行简简单单的代码,也让淘宝在战略层面掌握了竞争的主动权,避免了流量被百度搜索引擎拿走,同时也避免了平台内的商家要给百度竞价排名付费的可能,更是间接催生了淘宝的竞价排名体系。
而对于微信来说同样也是如此,此前微信公众号的内容只支持在该应用的搜一搜功能,或是腾讯旗下的搜狗搜索引擎中搜索到。这主要要因为用户上网冲浪的最终目地往往是消费内容,而内容、特别是高质量的原创内容更是天然的流量来源,这些内容可以帮助微信形成封闭的商业生态。所以让用户只能在体系内访问微信公众号的内容,也就成为了微信保护私域流量的关键。
那么问题就来了,robots协议会出现漏洞吗?答案是肯定的。robots协议从本质上来说就是网站运营方提供的规则,然而是规则就免不了出现漏洞。不过robots协议也很难出现问题,因为它的书写非常简单、逻辑也很直白,允许什么搜索引擎爬虫访问什么内容都可以清晰地表述出来。特别是微信这种协议非常简单的规则,仅面向自己的应用内搜索和搜狗搜索开放的robots协议,基本也不会有什么多余的内容。
文章插图
更为重要的一点是,robots协议本身其实是一个“君子协议”,是一个搜索引擎与网站之间的共识,并没有任何法律效力,也没有任何技术约束。所以换句话来说,这也意味着robots协议从技术层面是无法与搜索引擎爬虫对抗的。

文章插图
例如,一些网站如果不想让爬虫占据自家宝贵的服务器资源,往往就会直接在robots.txt文件中写上这样的规则,“User-agent: Googlebot,Allow: / User-agent: *,Disallow: /”,意思是本网站仅允许谷歌爬虫抓取,拒绝其他任何搜索引擎。
推荐阅读







- 低俗词汇|B站发布“低俗词汇谐音梗”治理公告,多次违规将被封号
- 虚假粉丝|抖音:专项打击平台虚假粉丝现象,共整顿账号 23.15 万个
- 邮件|华为花瓣邮箱 App 新版测试:支持多账号登录,新增保护邮件活动
- 直播间|资源砸进去,视频号直播带货今年能“起量”吗?
- 任泽平|?华为搜索引擎上线后,又突然403禁止访问;任泽平微博、公众号被双双禁言;快手网红控诉快手:高管一批一批的换,不懂管理|雷峰早报
- 整顿|抖音:专项打击平台虚假粉丝现象,共整顿账号 23.15 万个
- 视频平台|创作激励“姗姗来迟”,视频号“还能饭否”?
- 乱象|微信治理互联网用户账号运营乱象,“南京头条”“高考山东”等遭清理
- 封号|亚马逊新CEO上任,中国电商成重点封号对象,企业半年亏损7.4亿
- 建言|“泽平宏观”公众号已搜不到,建言文章违规无法查看