机器学习领域权威“跑分”
这次,在BERT模型的成绩表上有一个“异常”的数字:

文章插图
怎么?谷歌训练一个BERT要接近1天,别家都只要几分钟?

文章插图
NONONO!
这其实是谷歌从未透露的
它也是谷歌今年在MLPerf“非标准区”提交的一个作品:
一共花了
【 token|炼个BERT花了快1天?谷歌:我这是4810亿参数的巨型BERT】

文章插图
有史以来最大版本的BERT
标准BERT模型(BERT Large)参数规模只有3.4亿,而此次4810亿的巨型BERT是有史以来最大的一个版本。
这俩之间直接差了
而谷歌表示,
所以此次他们根本没有参加任何标准分区里的跑分评比,只在非标准区“释放了自我”。
MLPerf竞赛有俩分区:
Closed区也就是标准区,参赛商在ResNet-50等规定模型上跑分;

文章插图
Open区也就是非标准区,参赛商可以尝试任何规定以外的模型和方法来达到目标性能。
在大多数参赛商都“挤”在标准区训练小规模的模型时,谷歌员工
“在短短几秒内‘豪掷’4000块芯片来训练巨型BERT才是真的酷(爽)。”

文章插图
谷歌由此也希望MLPerf基准测试能引进更多的大模型,因为他们觉得现实中才不会像非标准区的参赛作品那样
而此次的巨型BERT性能也不赖,它的预测准确率为75%,
同时,和标准区其他参赛商一样,谷歌也用较少的文本数据样本来达到目标精度。
具体来说,标准区要求一个程序使用近5亿个token序列进行训练,每个序列的长度大多为128个token。
而Google只使用了大约2000万个序列,不过每个序列的长度为512token。
另外,完成这次工作的2048块TPU系统一开始也是为了迎合公司的生产和研发需要,所以它并未“束之高阁”——目前已用于
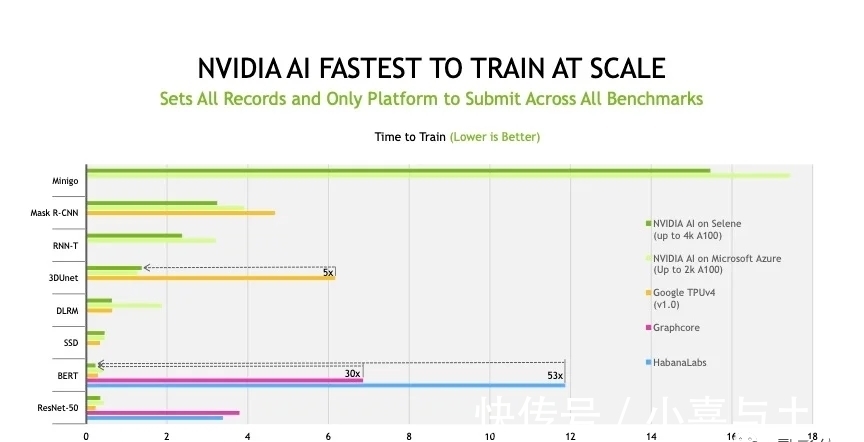
英伟达在标准区“战绩显赫”
其余MLPerf结果,主要在“标准区”,一如既往,
文章插图
比如它使用最新一代GPU A100的系统在训练
当然,此战绩一共花了4320个A100,在1080个AMD的EPYC x86处理器的帮助下并行完成。
但在不拼芯片和主机处理器的情况下,竞争对手可就碾压起英伟达了。
其中
打败了英伟达的Graphcore,则强调自己最看重性能和成本之间的平衡。

文章插图
就比如Graphcore在16路系统上训练ResNet-50耗费28分钟,比英伟达DGX A100系统快一分钟,但他们用到的POD-16是DGXA100成本的
此次参赛的其他厂商中,
微软的
同时Azure也表示后续也会像谷歌那样在非标准区提交一些成绩,虽然微软和英伟达在此前不久发布了目前最大的模型
更多评分结果大家可以参考官网数据。
推荐阅读







- marshall emberton参数配置怎么样?质量是真的差吗,不看后悔!
- 声阔Liberty Air 2 Pro怎么样?是否值得入手,不看后悔!
- marshall emberton和bose区别如何,性价比哪个好更高!
- marshall emberton和bo a1哪个更好?使用感受区别如何!
- marshall emberton和bose哪个音质好,区别明显吗怎么选择!
- 声阔Liberty Air 2 Pro使用2个月反馈!!看了就知道了!
- 买车请排队:特斯拉Cybertruck皮卡订单超65万
- 还想着Cybertruck?来看福特全新F-150猛禽皮卡
- 特斯拉皮卡Cybertruck预订单已超50万辆
- bert|FF上市敲钟6人来头大:有美国州财长、投资人、供应商巨头…