隐私计算|浙江大学求是讲席教授任奎:隐私计算的前沿进展( 三 )
文章插图
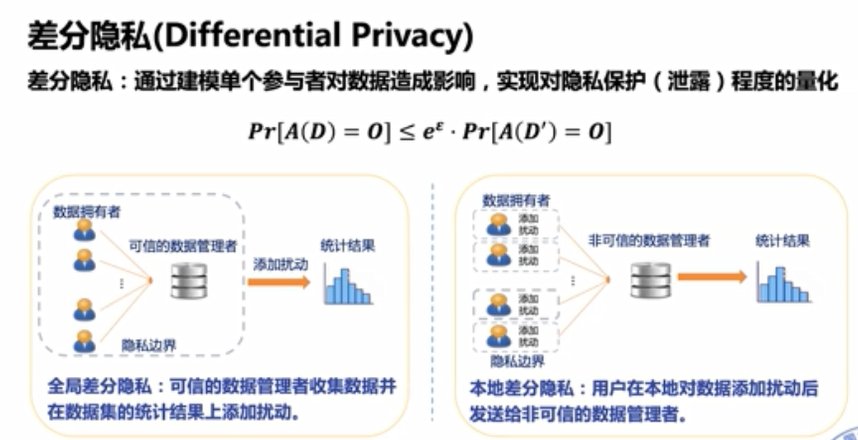
差分隐私和密码学不太相关,是较新的概念。其思想和工作原理大致可以理解为:在数据中加入噪音,使得统计学相关的查询既能得到有效的数据,又能保证安全。学术上的定义是:通过建模单个参与者对数据造成影响,实现对隐私保护(泄露)程度的量化。
目前,该方法可以分为两种:全局差分隐私,可信的数据管理者收集数据并在数据集的统计结果上添加扰动;本地差分隐私,用户在本地对数据添加扰动后,发送给非可信的数据管理者。
文章插图
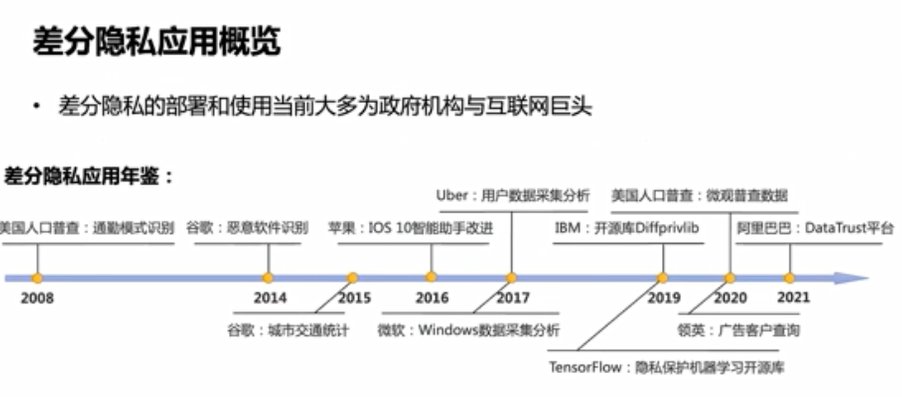
从计算角度看,差分隐私能在一定的程度上解决“密码学手段开销过大”的缺点。对比加密方法解决数据计算过程中的隐私泄露,而差分隐私方法解决计算结果的隐私泄露。目前,差分隐私的部署和使用大多为政府机构与互联网巨头。

文章插图
例如,2016年苹果在WWDC大会上宣布使用基于CM- Sketch和阿达马变换的本地化差分隐私技术来保护IOS、MAC用户隐私。相比于布隆过滤器, Count- Min Sketch更适用于频率统计任务;阿达马变换也能有效降低通信开销。但有研究人员认为苹果在实际应用中设置的隐私预算参数超出了可接受的范围,隐私保护能力不够强。

文章插图
微软也有相应的动作,并在2017年将差分隐私方案部署到了win 10系统中。此外微软和哈佛大学合作推出了 OpenDP开源差分隐私平台,希望降低中小开发者应用差分隐私的门槛。
文章插图
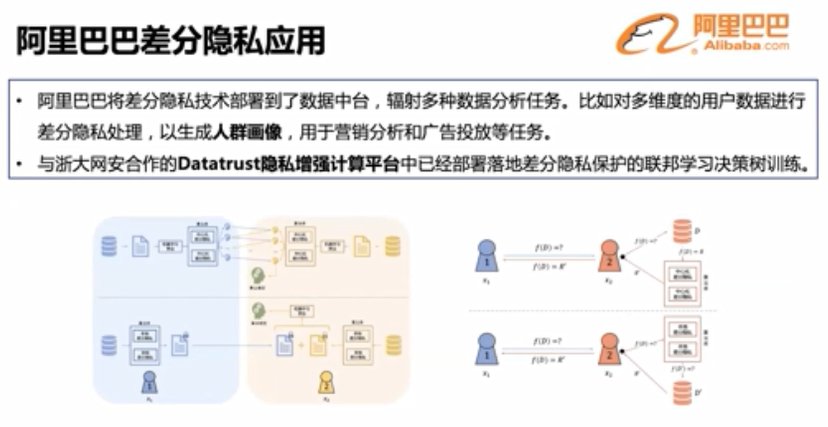
【 隐私计算|浙江大学求是讲席教授任奎:隐私计算的前沿进展】阿里巴巴也在 Datatrust隐私增强计算平台中部署落地差分隐私保护的联邦学习决策树训练。
差分隐私之所以受到关注,主要是它有严谨的理论模型,提供了可验证的量化隐私保护机制;提供了传统密码学无法提供的隐私保护手段,具有更轻量级的计算负载,提高了隐私保护效率。
但也存在理论和应用上的挑战。例如在理论层面,数据可用性较差:差分隐私在查询结果中加入随机化,导致数据可用性下降;数据类型有限:缺乏针对复杂数据类型的有效差分隐私保护方法。
在应用层面,差分隐私不适用于单一样本的确切信息查询;复杂应用场景下差分隐私得到的结果误差较大;并且,目前还缺乏测试算法(乃至自动测试算法)是否符合差分隐私的方法。

文章插图
如今,学术界针对差分隐私的机制优化有了一些进展。例如上图所示的最优机制设计、机制后处理、最优机制搜寻等工作。
文章插图
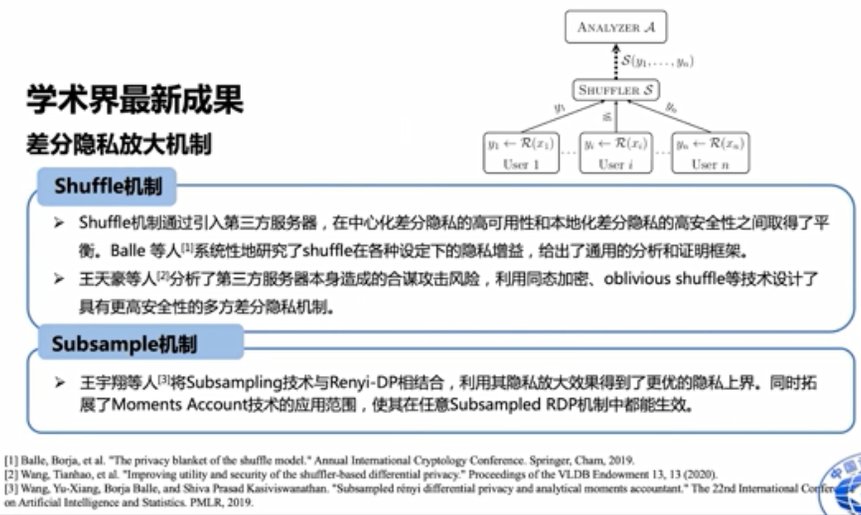
相应地,Shuffle机制、Subsample机制的提出增添了差分隐私放大机制的研究。
针对应用难题,学界也提出了差分隐私正确性测试方法,包括多轮采样与概率论技巧相结合的方法、程序分析的方法等等。
推荐阅读







- priv美国三大运营商表示,不会封禁iCloud的隐私功能
- 隐私|默克尔:你为什么监听我?奥巴马:现在没有,将来也不会有
- 隐私|小米应用商店移除32位包必传限制,开发者可自主决定上传APK类型
- 浙江大学|IEEE正式推行首个隐私保护机器学习国际标准 蚂蚁集团参与制定
- 注册商标|商家用“舟山带鱼”近似商标开网店被浙江舟山行业协会起诉
- o2o|恒腾网络:已与腾讯计算机就多款游戏产品的合作正在洽谈之中
- 程序|Norton 360 被发现在用户计算机中安装挖矿程序
- 故障|英国将对云计算供应商加强监管,以防发生故障影响金融行业
- 店铺|当心!你的旧手机可能会泄露个人隐私数据,提前清空也没用
- 脸书|违反数据隐私规则,谷歌脸书遭法国罚款2.1亿欧元