处理单元|出行洞察:DPU市场火热,“芯”战场发展前景如何?
文章图片

文章图片
01核心观点 随着数据处理量需求的高速发展 , 对数据运行算力和网络端口速度的要求与日俱增 , 同时面临数据高速涌入时和对应处理单元匹配失衡的情况 , 通过设置专用DPU进在网络端口处对数据完成预处理
- 有利于释放算力和存储空间 , 增加计算安全性 , 降低计算成本 ,
- 同时为整体计算应用相关行业的未来发展奠定基础 。
- 近期在于确认技术路径的选择和分析落地案例的场景 ,
- 长远来看在于找到核心推广至全体计算行业应用的方法 。
- 玩家类型众多 ,
- 且入局时间接近 ,
- 处于激烈竞争状态 ,
- 技术路径各异:包括FPGA、ARM和自研异构多种架构 , 目前还没有确认的最优解决方案及芯片厂商应用落地案例 。
在这个阶段 , 计算成本和能力一直处于平稳状态 , 但随着数据量的增大 , 网络和存储负载一直在增加 。 网络性能和计算性能的差距一直在扩大 , 早在2018 年超过 70%的以太网端口的出货速度就约为10G/秒 。 如果一直提升算力 , 但是通信基础设施跟不上 , 整体系统性能还是受限 , 难以发挥出真正的潜能 。
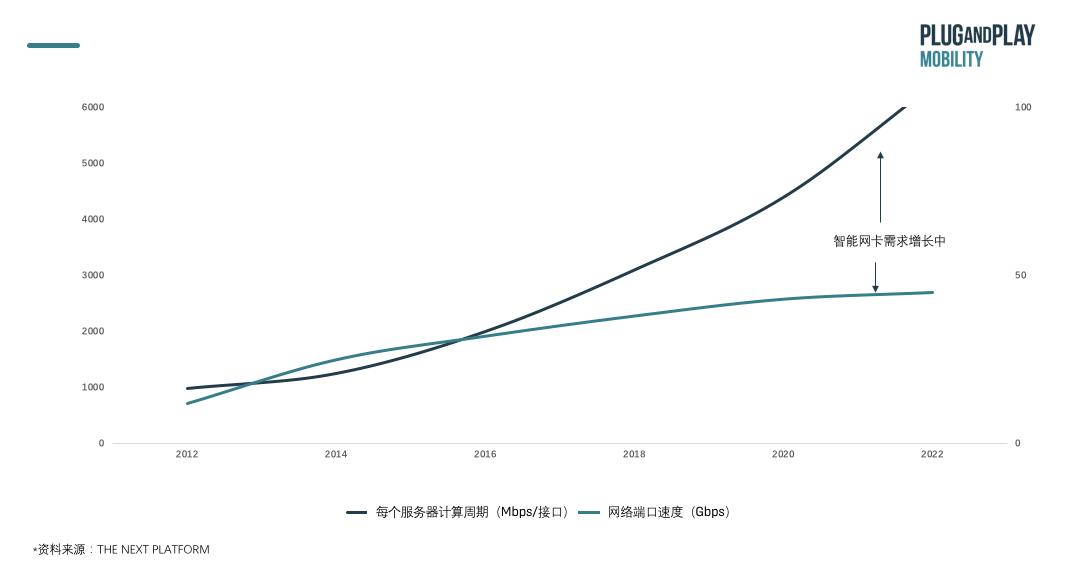
文章图片
为了弥补此需求缺口 , DPU应运而生 , 专门用于处理数据 。
DPU , Data Processing Unit , 数据处理单元 , 是一种片上系统 , 结合了以下三个关键要素:
- 行业标准的高性能软件可编程多核CPU , 通常基于广泛使用的Arm架构 , 并与其他SOC组件紧密耦合 。
- 高性能的网络接口 , 能够以网络速度解析 , 处理和有效地将数据传输到GPU和CPU 。
- 灵活的可编程加速引擎 , 旨在减轻网络任务负担并优化AI和机器学习 , 安全性 , 电信和存储等的应用程序性能 。

文章图片
【处理单元|出行洞察:DPU市场火热,“芯”战场发展前景如何?】DPU专门用于数据处理 , 拥有高性能的网络接口 , 用于弥补CPU和GPU的不足 。
与专门用于通用计算的CPU和适合视频、图片等非结构化数据的加速计算不同的GPU相比 , DPU出现年代较晚 , 近两年才开始兴起 , 主要用于在数据中心周围移动数据 , 进行数据处理 , 减轻网络和存储工作负载 , 补足CPU和GPU的算力 。
CPU 内核是为通用应用程序处理而设计的 , 随着网络速度的提高(现在每条链路的速度高达 200gb / s ) ,CPU 花费了太多宝贵的内核来分类、跟踪和控制网络流量 。
通过DPU的方式就可以解决网络传输中的瓶颈问题或丢包问题 。 典型通信延时可以从30-40微秒降低到3-4秒 , 性能提升10倍以上 。
03 DPU的三大主要功能:保证安全性、释放CPU算力和释放服务器容量 保证安全性:DPU 作为一个智能网卡, 是网络流量的入口 , 也是阻止攻击和加密传输最直接的地方 。 它通过与主 CPU 分开运行来提供安全隔离 , 如果主 CPU 受损 ,DPU 仍然可以检测或阻止恶意活动 。 DPU 可以在不立即涉及 CPU 的情况下检测或阻止攻击 。
释放CPU算力:DPU可以执行原本需要CPU处理的网络、存储和安全等任务 , 释放CPU的运算能力可以被释放出来 , 去执行其他企业应用 。
释放服务器容量:DPU还释放了服务器的容量 , 以便它们可以恢复到应用程序计算 。 在一些具有大量I / O和沉重虚拟化的系统上内核成本缩减一半 , 因此吞吐量提高了2倍 。 除了内核的成本 , 还要计算整个机器的成本 , 包括其内存和I / O以及所释放的工作量 , 采用DPU之后 , 几乎可以用一半的成本来保证原有的安全性和灵活性 。
DPU的核心应用在于分布式存储、网络计算和网络安全领域的成本削减和性能提升 。
DPU作为一个可编程处理器 , 运行的都是非应用型负载 , 从而可以让服务器CPU资源更好地服务应用负载 , 对数据中心来说 , 是通过更明细的分工 , 实现效率的提升 , 总体系统成本的削减 。
04
DPU同时将助力隐私计算和边缘端计算的发展
隐私计算:基于隐私保护技术的数据要素化 , 使得数据所有权和使用权分离 , 使得数据价值可以流动 , 对算力和网络都有巨大的要求 。
算力:
- 多方安全计算、联邦学习、同态加密、差分隐私、零知识证明等密码学方法 , 性能低 , 需要的计算资源比明文多几个数量级;
- DPU可以带来改善 。 DPU的本质是将计算向存储靠近 。 类似的方案有存内计算、近内存计算等框架 , 还有将计算和数据融合的雾计算 。 以数据为中心的处理器首先解决的是性能问题 。
- 算力不足可以用硬件加速缓解 , 但是网络带宽 , 尤其是公网环境 , 有限的带宽是目前落地的瓶颈 。 尤其是多方安全计算MPC、联邦学习等需要多轮网络交互的技术 。
- 对于性能问题 , 在数据的流动 , 即网络传输 , 是数据中心的第二大职能 。 诸如网络协议处理、传输压缩、数据加密等任务都是网卡设备的职能 。 DPU可以被集成到SmartNIC(下一代网卡)中 , 从而带来网卡的性能提升 , 那么它不仅可以处理物理层和链路层的数据帧 , 也有能力承担网络层和应用层的职能 。
NVIDIA DRIVE Atlan是新一代AI自动驾驶汽车处理器 , 算力将达到1000TOPS , 约是上一代Orin处理器的4倍 , 超过了大多数L5无人驾驶出租车的总计算能力 , 堪称 “车轮上的数据中心” , 将车辆的整个计算基础设施集中到一块系统级芯片上 。
这是DRIVE平台首次集成DPU , 通过Arm核为自动驾驶汽车带来数据中心级的网络 , 致力于应用到2025年的车型 。
该SoC采用下一代GPU的体系结构、新型Arm CPU内核、新深度学习和计算机视觉加速器 , 并内置为先进的网络、存储和安全服务的BlueField DPU , 网络速度可达400Gbps 。
据Fungible和英伟达的预测 , 用于数据中心的DPU量级将达到和数据中心服务器等量的级别 。 数据中心里的服务器 , 一般都需要两张智能网卡 , 双运营双备份以保证安全 , 且一般需要三年更新迭代一次 , 服务器每年新增大约千万量级 , 每台服务器可能没有GPU , 但一定会有一颗或者多颗DPU , 好比每台服务器都必须配网卡一样 。 服务器每年新增大约1500万台 , 每颗DPU如果以1万元计算 , 这将是千亿量级的市场规模 。
按照目前数据中心市场判断 , 整体市场规模在千亿级别

文章图片
05 DPU 由智能网卡发展而来 , 未来最终将成为基础设施处理的重要工具 以太网控制器开始 , 提高计算能力 , 从而使普通的NIC变得智能:
- 收集许多Arm核心 。
- 增加现场可编程门阵列(FPGA) , 可编程逻辑 。
- 增加一种是自定义设计的网络处理器 。
管理侧网络后台任务是最先遇到资源消耗挑战问题的 , 在25bit/s下占用的CPU资源已经非常显著 。 智能网卡就是为卸载网络相关工作任务而设计的 。
DPU 数据处理:
从本质上来说 , 在智能网卡的基础上行 , 不仅仅是网络 , 而是整个I/O相关的工作任务处理都会面临资源消耗的挑战问题 , 因此DPU在网络卸载的基础上 , 加入了存储卸载及虚拟化卸载的解决方案 。
IPU 基础设施处理:
从云计算公司的角度来看 , 基础设施处理器平台不仅承载网络、存储及虚拟化的卸载 , 还需要承担安全、管理、监控等各种管理面的功能 , 更为关键的是物理隔离业务和管理:业务在CPU和GPU , 管理在DPU(或者更准确地称为IPU) 。 目前英特尔已经使用 FPGA 部署了 IPU , 微软、百度、京东云和 VMWare是买家 。 通过特定功能 , IPU可对数据中心中基于微服务架构的现代应用程序进行加速 。 谷歌和Facebook的研究表明 , 微服务通信开销可消耗22%到80%的CPU性能 。
// DPU目前的主要架构
▎基于FPGA的SmartNIC
Pro:灵活性高 , 可编程
可以像处理网络和存储一样处理计算 , 在开发上 , 可以如CPU一样具有高度的可编程性 , 也可以像在SoC解决方案上一样快速开发新功能 。 如赛灵思宣称 , 其Alveo U25与基于Arm多核的SmartNIC相比 , 在相同功率下 , 性能可提高10倍 。
▎基于ARM多核阵列
Pro:可以卸载明确定义的任务 , 例如标准化的安全和存储协议 , GPU可以从与DPU融合中受益
Con:
- 基于软件可编程处理器 , 由于缺乏处理器并行性 , 这些处理器在用于网络处理时速度较慢
- 多核 SmartNIC ASIC中的固定功能引擎无法扩展来处理新的加密或安全算法 , 因为它们缺乏足够的可编程性 , 只能适应轻微的算法更改 。
Pro:异构具有更高的灵活性 , 并能带来更高效的数据处理效率
Con:需要自研架构 , 研发投入较高 。 如国内中科驭数的KPU架构 , 他们将四类异构核组织起来 , 分别处理网络协议 , OLAP\OLTP处理 , 机器学习和安全加密运算核 。
目前的趋势是趋于折中 , 且专用核的比重越来越大 , 正在成为最新的产品趋势 , 以英伟达的BlueField2系列DPU来看 , 就包括4个Arm核及多个专用加速核区域 , Fungible的DPU则包含6大类的专用核 , 和52个MIPS小型通用核 。
06 DPU赛道上主要玩家 // 大厂收购初创企业
在DPU这一新兴芯片赛道上已有英伟达(收购Mellanox)、英特尔(收购Bearfoot )、Broadcom和Marvell(收购Cavium)、 Fungible(初创) 、Xllinx等巨头 , 主要以收购初创企业的方式完成 。

文章图片
// 初创企业团队来自大厂背景 , 专注单一架构的芯片
他们成立时间大部分在2018年及以后 , 在半年内均完成了多轮融资 , 前期投资机构持续加码 。
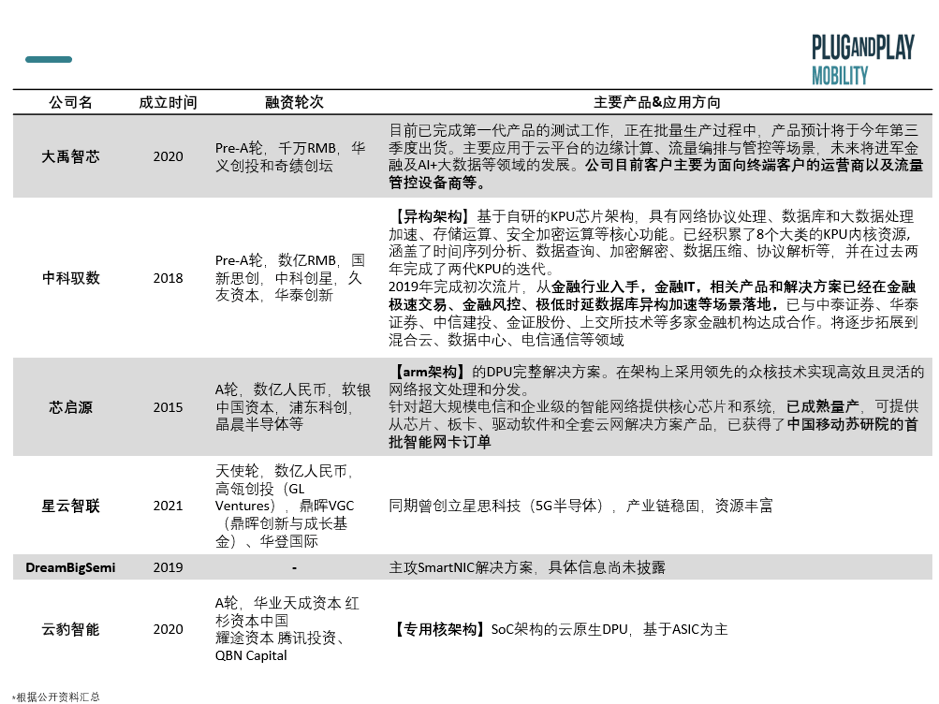
文章图片
市场中DPU玩家与所有芯片厂商类似 , 在产业链中主要负责IC设计环节 , 仅有少部分设计框架设计 。
EDA:设计芯片的软件高度垄断:美国的Synopsys、美国的Cadence 和西门子旗下的 Mentor Graphicss占领95%市场 。
框架结构:市场中DPU玩家与所有芯片厂商类似 , 在产业链中主要负责IC设计环节 , 仅有少部分设计框架设计 。
ARM架构较为垄断 , 和intel的x86在数据中心市场形成直接竞争 。
DPU厂商自研框架较少 , 目前
- 国内仅有中科驭数公开KPU自研框架 。
- 英伟达计划收购ARM 。 (近期遭到搁置)
晶圆测试&封装制造:我国初创芯片(DPU)厂商和博通等类似 , 以Fabless模式为主 , 只负责芯片的电路设计与销售 。 将生产、测试、封装等环节外包 。
- 无庞大实体资产 , 创始的投资规模小、进入门坎相对低
- 较无法做到完善的上下游工艺整合、较高难度的领先设计 。 代工厂会将制作完成的芯片送回 IC 设计公司、继续进行测试与分析 。
- 市面上的DPU产品功能覆盖和场景覆盖能力不足 , 难以满足不同客户对于DPU产品快速使用的需求 。 因此 , 如何让市场形成更多有效的DPU产品是推动商业化的关键 ,DPU产品需要结合用户的具体需求 , 从应用场景出发 , 向下构建底层体系 , 从而实现快速的商业化落地 。
- 现有数据中心多为小型数据中心 , 真正运算量到了一定量及的超级大型数据中心做降本才更有意义 。 随着数据量的不断增加和边缘计算应用的增加 , 未来DPU的市场会逐步扩大 。
云提供商对于自身的需求最清楚 , 因此自研芯片非常合乎情理 , 而且有机会能为自身的云服务提供差异化竞争的能力 。
云服务器厂商:亚马逊AWS从2013年开始用Nitro卡(智能网卡 , 如今已经到了第四代) , 亮点在于拥有控制EC2实例的业务逻辑 。 目前 , 亚马逊马逊为AWS已经发布了基于ARM核的自研处理器Graviton 。
同样做国内 , 阿里也有类似的产品逻辑 , 比如X-Dragon MOC , 如果谷歌等其它云服务商也跟进使用ARM架构自研芯片 , 那么这些云厂商就会成为芯片大厂的客户同时也是竞争对手 。
8-9年后 , DPU将作为IT基础设施中的主流方案 。 届时 , 从云计算公司开始 , 至大中型互联网公司再到中小型企业客户群体将会依次完成从CPU到DPU的云计算引擎迭代更新 。
07
总结
DPU , 即数据处理单元芯片
- 有助于提高云计算及相关产业的效率和安全性、降低时间和经济成本 ,
- 收到整体政策和相关产业发展的支持
- 相关初创企业发展迅速 , 融资市场蓬勃
- 主要在于目前存量机房、服务器数量较多 , 新服务器增量不及预期 , 且新组件安装成本较高
- 且云计算市场集中度较高 , 使用者倾向于使用自研芯片
- 如果有自研架构可以解决通用FPGA和arm架构面临的问题 , 并与落地应用客户沟通较深 , 对业务直接应用有更多了解 , 将有极大竞争优势 。

文章图片
加入璞跃中国
科技创新生态
添加微信小助手 pnp_china
加入创新者社群
及时掌握最新资讯
推荐阅读







- 专用|造纸废水处理专用聚丙烯酰胺絮凝剂
- 聚丙烯|废水处理用聚丙烯酰胺选型技巧
- 最新消息|B站员工过年加班猝死?回应:事发前一周内未加班 将配合警方和家属处理后续事宜
- Turbo|英特尔 12 代酷睿处理器 35W 型号开始上市
- 传音|传音 Infinix Zero 5G 官宣:搭载天玑 900 处理器
- 处理器|微星新款 E16 大屏翻转本曝光:搭载 Arc A370M 显卡
- 系列|搭载 AMD 锐龙 6000 处理器的笔记本本月开始上市
- 可从|英特尔 W680 主板曝光,基于 12 代酷睿的至强处理器即将到来
- the|美CDC推出废水处理工具以帮助显示COVID-19趋势
- 处理器|英特尔 12 代酷睿不再使用 TDP 标注功耗