AI 西方唯一AI芯片独角兽 单挑英伟达( 二 )
需要注意的是 , 除了博世、三星从A轮就开始参投 , 红杉资本是Graphcore的C轮领投方 , 而微软与宝马i风投则成为其D轮融资领投方;
而E轮融资的主要参与者 , 则是非产业基金——加拿大安大略省教师养老金计划委员会领投 , 富达国际与施罗德集团也加入了这轮融资 。
你可以从投资方看出 , Graphcore的产业投资方基本分为三个产业方向——云计算(数据中心)、移动设备(手机)与汽车(自动驾驶) 。没错 , 这是三个最早被人工智能技术“入侵”的产业 。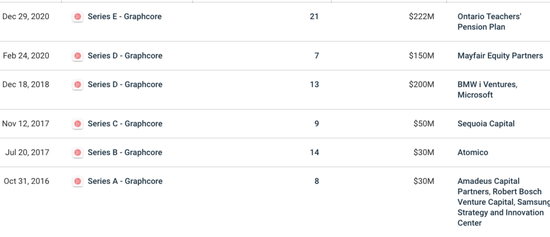
文章图片
图片来自Crunchbase
工业界们似乎越来越达成这样一个共识 , 未来需要有一家像ARM主导移动设备时代一样的底层创新企业 , 除了有希望卖出上亿块芯片的同时 , 也能推动人工智能与各个产业的深度整合 , 最终触达到上百亿普通消费者 。
从产品的角度来看 , Graphcore 在2020年拿出了相对引人注目的作品——推出第二代 IPU-M2000芯片 , 该芯片搭载在一个名为IPU Machine platform的计算平台上 。另外 , 其芯片配套的软件栈工具Poplar也有同步更新 。
“教计算机如何学习 , 与教计算机做数学题 , 是完全不同的两件事 。提升一台机器的‘理解力’ , 底层驱动注重的是效率 , 而不是速度 。” Graphcore CEO Nigel Toon 将新一代AI芯片的开发工作视为一个“千载难逢的机会” 。
“任何公司能做到这一点 , 都能分享对未来几十年人工智能技术创新和商业化的决定权 。”
切中英伟达的“软肋”
没有一家AI芯片设计公司不想干掉市值高达3394亿美元的英伟达 。或者说 , 没有一家公司不想做出比GPU更好的人工智能加速器产品 。
因此 , 近5年来 , 大大小小的芯片设计公司都倾向于在PPT上 , 用英伟达的T4、V100 , 甚至是近期发布的“最强产品”A100与自己的企业级芯片产品做比较 , 证明自己的处理器拥有更好的运算效率 。
Graphcore也没有例外 。
他们同样认为 , 由于上一代的微处理器——譬如中央处理器(CPU)和图形处理单元(GPU)并不是为人工智能相关工作而专门设计 , 工业界需要一种全新的芯片架构 , 来迎合全新的数据处理方式 。
当然 , 这样的说法并不是利益相关者们的单纯臆想 。
我们无法忽视来自学术界与产业界对GPU越来越多的杂音——随着人工智能算法训练与推理模型多样性的迅速增加 , 在诞生之初并不是为了人工智能而设计的GPU暴露出了自己“不擅长”的领域 。
“如果你做的只是深度学习里的卷积神经网络(CNN) , 那么GPU是一个很好的解决方案 , 但网络已经越‘长’越复杂 , GPU已经难以满足AI开发者们越来越大的胃口 。”
一位算法工程师向虎嗅指出 , GPU之所以快 , 是因为它天生就能并行处理任务(GPU的释义和特点可以看《干掉英伟达》这篇文章) 。如果数据存在“顺序” , 无法并行 , 那么还得用回CPU 。
“很多时候既然硬件是固定的 , 我们会想办法从软件层 , 把存在顺序的数据 , 变为并行的数据 。譬如语言模型中 , 文字是连续的 , 靠一种‘导师驱动’的训练模式就可以转换为并行训练 。
但肯定不是所有模型都可以这么做 , 譬如深度学习中的‘强化学习’不太适合用GPU , 而且也很难找到并行方式 。”
由此来看 , 学术圈不少人甚至喊出“GPU阻碍了人工智能的创新”这句话 , 并不是耸人听闻 。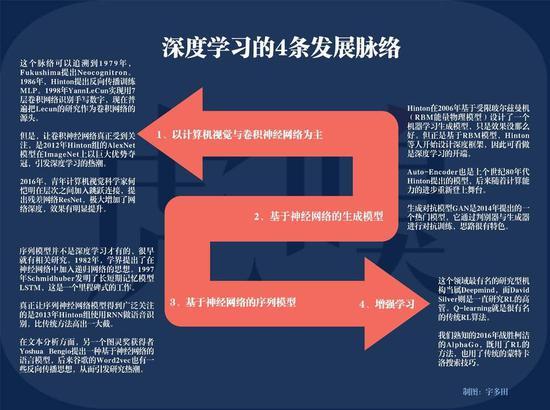
文章图片
深度学习的4个发展脉络 , 制图:宇多田
“深度学习” , 这个近10年来机器学习领域发展最快的一个分支 , 其神经网络模型发展之快、类型之广 , 只靠GPU这块硬件的“一己之力”是很难追上其复杂运算脚步的 。
Graphcore 回复了虎嗅一份更为详尽的答案 。他们认为 , 对于深度学习中除去CNNs的另外几个分支 , 特别是循环神经网络(RNN)与强化学习(RL) , 让很多开发者的研究领域受到了限制 。
推荐阅读







- 研制 好消息中国航空航天技术飞速进步,有望彻底打破西方垄断
- 张艺凡 王俊凯唯一关注的创3学员,根本不是张艺凡,得知是谁后有眼光
- IT 被“芯片慌”催热的新兴芯片市场
- 芯片 比芯片更稀缺的资源,航天航空重要材料,中国年产量仅2吨
- Samsung 三星Galaxy Book Go发布:骁龙7c Gen2芯片 起售价349美元
- 沙漠 美卫星路过中国上空拍下惊人一幕,西方坐不住了到底咋做到的
- Huawei 中国唯一、世界第三,深度解密鸿蒙系统的星辰大海
- 新疆 今年唯一!新疆可见日偏食全过程
- TSMC 台积电公布最新技术进展:3nm明年量产 汽车、射频芯片制程也升级
- Apple 苹果公司在亚利桑那的供应商工厂建设“进展顺利”预计2024年投产芯片