AI 西方唯一AI芯片独角兽 单挑英伟达( 三 )
譬如 , 用强化学习做出了阿尔法狗的英国AI公司 Deepmind , 很早就因为GPU的计算局限问题而关注Graphcore , 其创始人Demis Hassabis最后成为了Graphcore的投资人 。
“很多企业产品部门的开发者把需求(特别是延时和吞吐量的数据指标)交给算力平台部门时 , 他们通常会拒绝说 ‘GPU 目前不够支持这么低的延时和这么高的吞吐量’ 。
主要原因就在于 , GPU的架构更适用于‘静态图像分类与识别’等拥有高稠密数据量的计算机视觉(CV)任务 , 但对数据稀疏的模型训练并不是最好的选择 。
而跟文字相关的“自然语言处理”(NLP)等领域的算法 , 一方面数据没那么多(稀疏) , 另一方面 , 这类算法在训练过程中需要多次传递数据 , 并迅速给出阶段性反馈 , 以便为下一步训练提供一个便于理解上下文的语境 。”
换句话说 , 这是一个数据在持续流动和循环的训练过程 。
就像淘宝界面的“猜你喜欢” , 在第一天在“学习”了你的浏览和订单数据后 , 把不太多的经验反馈给算法进行修正 , 第二天、第三天以及未来的每一天不断学习不断反馈 , 才会变得愈加了解你的产品喜好 。
而这类任务 , 譬如谷歌为更好优化用户搜索在2018年提出的BERT模型 , 便是优秀且影响深远的RNN模型之一 , 也是Graphcore提到的“GPU非常不擅长的一类任务” 。为了解决这类问题 , 仍然有很多公司在使用大量CPU进行训练 。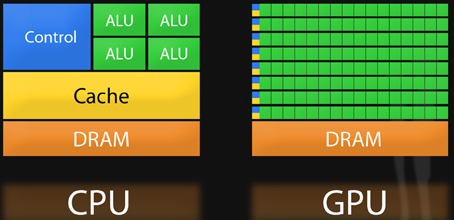
文章图片
CPU与GPU架构对比
从根本上看 , 这其实是由当下芯片运行系统最大的瓶颈之一决定的——如何在一块处理器上 , 将数据尽可能快地从内存模块传送到逻辑操作单元 , 且不费那么多功耗 。在进入数据爆炸时代后 , 解锁这个瓶颈便愈加迫在眉睫 。
举个例子 , 2018年10月 BERT-Large 的模型体量还是3.3 亿个参数 , 到2019年 , GPT2的模型体量已达到15.5亿(两个均属于自然语言处理模型) 。可以说 , 数据量对从系统底层硬件到上层SaaS服务的影响已经不可小觑 。
而一块传统的GPU或CPU , 当然可以执行连续多个操作 , 但它需要“先访问寄存器或共享内存 , 再读取和存储中间计算结果” 。这就像先去室外地窖拿储存的食材 , 然后再回到室内厨房进行处理 , 来来回回 , 无疑会影响系统的整体效率和功耗 。
因此 , 很多半导体新兴企业的产品架构核心思路 , 便是让“内存更接近处理任务 , 以加快系统的速度”——近存算一体 。这个概念其实并不新鲜 , 但能做出真东西的公司少之又少 。
而Graphcore到底做到了什么?简单来说 , 便是“改变了内存在处理器上的部署方式” 。
在一块差不多像小号苏打饼一样大的IPU处理器上 , 除了集成有1216块被称为IPU-Core的处理单元 , 其与GPU和CPU最大的不同 , 便是大规模部署了“片上存储器” 。
简言之 , 便是将SRAM(静态随机存储器)分散集成在运算单元旁 , 抛弃了外接存储 , 最大程度减少数据的搬移量 。而这种方法的目标 , 就是想通过减少负载和存储数量来突破内存带宽瓶颈 , 大大减少数据传输延迟 , 同时降低功耗 。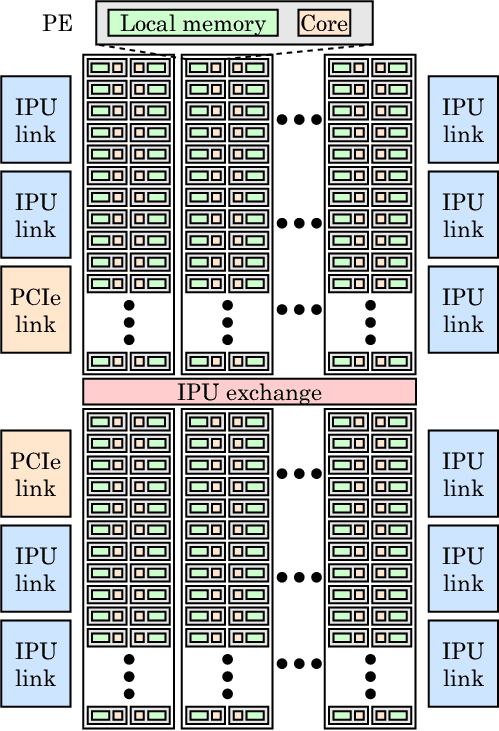
文章图片
IPU架构
也正因为如此 , 在一些特定算法的训练任务中 , 由于所有模型都可以保存在处理器中 , 经过测试 , IPU的速度的确可以达到GPU的20~30倍 。
举个例子 , 在计算机视觉领域 , 除了大名鼎鼎且应用广泛的残差网络模型ResNets(与GPU很契合) , 基于分组卷积与深度卷积方向的图像分类模型 EfficientNet 和 ResNeXt 模型也是逐渐兴起的研究领域 。
而“分组卷积”有个特点 , 就是数据不够稠密 。
因此 , 微软机器学习科学家 Sujeeth 用Graphcore的IPU做了一次基于EfficientNet模型的图像分类训练 。最后的结果是 , IPU用30分钟的时间完成了一次新冠肺炎胸部X光样片的图像分析 , 而这个工作量 , 通常需要传统 GPU 用5个小时来完成 。
推荐阅读







- 研制 好消息中国航空航天技术飞速进步,有望彻底打破西方垄断
- 张艺凡 王俊凯唯一关注的创3学员,根本不是张艺凡,得知是谁后有眼光
- IT 被“芯片慌”催热的新兴芯片市场
- 芯片 比芯片更稀缺的资源,航天航空重要材料,中国年产量仅2吨
- Samsung 三星Galaxy Book Go发布:骁龙7c Gen2芯片 起售价349美元
- 沙漠 美卫星路过中国上空拍下惊人一幕,西方坐不住了到底咋做到的
- Huawei 中国唯一、世界第三,深度解密鸿蒙系统的星辰大海
- 新疆 今年唯一!新疆可见日偏食全过程
- TSMC 台积电公布最新技术进展:3nm明年量产 汽车、射频芯片制程也升级
- Apple 苹果公司在亚利桑那的供应商工厂建设“进展顺利”预计2024年投产芯片