机器之心专栏
机器之心编辑部
近期 , 中山大学发布了基于常识的无偏视觉问答数据集 (Knowledge-Routed Visual Question Reasoning , KRVQA) 。 由于自然语言与标注者中自然存在的偏差 , 现有的算法能够通过拟合数据集内的这些偏差达到很好的效果 , 而不需要理解对应的文字和图像信息 。 相关论文发表在国际知名顶级期刊 TNNLS 上 。在自然语言处理和计算机视觉领域 , 已经有工作开始探索基于常识的阅读理解和视觉问答问题 。 这类问题要求算法需要额外的常识才能给出答案 。 但现有的常识视觉问答数据集大多是人工标注的 , 并没有基于合适的知识或情感表达进行构建 。 这不仅导致常识的分布相当稀疏 , 容易产生解释的二义性 , 同时还容易引入标注者偏差 , 使得相关算法仍在关注于增加神经网络的表达能力以拟合问题和答案之间的表面联系 。
针对此问题 , 研究者提出了新的基于知识路由的视觉推理数据集 (Knowledge-Routed Visual Question Reasoning , KRVQA) , 该数据集基于现有的多个公开知识 / 常识图谱中与现有图像场景图 (scene graph) 相关的部分 , 通过预先定义的规则搜索图谱中的推理路径 , 并生成大规模无偏差的问答和推理标注 。 如图 1 所示 , 该数据集避免现有数据驱动的深度模型通过过拟合得到高准确率 , 推动视觉问答模型正确感知图像中的视觉对象 , 理解问题并整合对象之间的关系和相应常识回答问题 。
文章图片
图 1:KRVQA 测试基准的样例示意 。
具体而言 , 基于通过生成推理路径 , 从图像场景图或知识库中选择一个或两个三元组进行多步推理 , 并通过约束使用的三元组 , 将知识从其他偏差中分离出来 , 并平衡答案的分布 , 避免答案歧义 。 两个主要的约束为:
1. 一个问题必须与知识库中的多个三元组相关 , 但仅有一个三元组与图像相关 。
2. 所有的问题都基于不同的知识库三元组 , 但训练集和测试集拥有相同的候选答案集合 。
约束 1 能强制视觉问答模型正确地感知图像 , 而不能仅仅根据给定的问题猜测知识 。 约束 2 则能避免现有方法通过训练集中的样本来拟合知识库 , 强制模型通过外部知识来处理未见过的问题 , 促进模型在泛化性上的研究 。
研究者对各种知识库编码方法和最新视觉问答模型进行了大量实验 , 结果表明 , 在给定知识库的情况下 , 是否给定问题相关的三元组的两张情况间仍然会存在较大的差距 。 这说明提出的 KRVQA 数据集能很好体现现有深度模型在知识推理问题上的不足 。
KRVQA 数据集
该数据集基于从自然图像场景图和外部知识库中提取的一个或两个三元组 , 组成推理结构 , 并以该结构为基础通过模板构建问题答案对 。
给定一个图像 , 研究者首先合并其场景图和外部知识库以形成和图像相关的知识图 。 该数据集利用现有的公开标注数据构建数据集 , 包括使用 Visual Genome 数据集中图像场景图标注以获得图像中的所有对象 / 关系三元组, 使用 WebChild、ConceptNet、DBpedia 等一般常识知识库获取图像信息以外的常识三元组 。 场景图和知识库中的三元组都包含一个主语、一个关系和一个宾语共三个项 。 如果图像场景图中的物体和知识库某个三元组中一项的名称相同 , 这两项就将合并 。 在合并所有名称相同的项之后 , 可以得到一个与图像相关的知识图 。 研究者利用其中包含的三元组来生成复杂的问题——答案对 。
然后从图中提取一条路径并根据路径提出一阶或二阶问题 。 推理路径的提取由一组层级化的基本查询的构建 。 一个基本查询将告知模型在已知主语 A , 宾语 B 和关系 R 中的其中两个时 , 需要去哪个信息源取出第三个信息 。 例如 , 表示需要模型从知识库中找到包括主语 A 和宾语 B 的三元组 , 并将三元组的关系 R 取出作为输出 。 有如下 6 个基本查询:
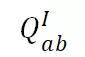
文章图片
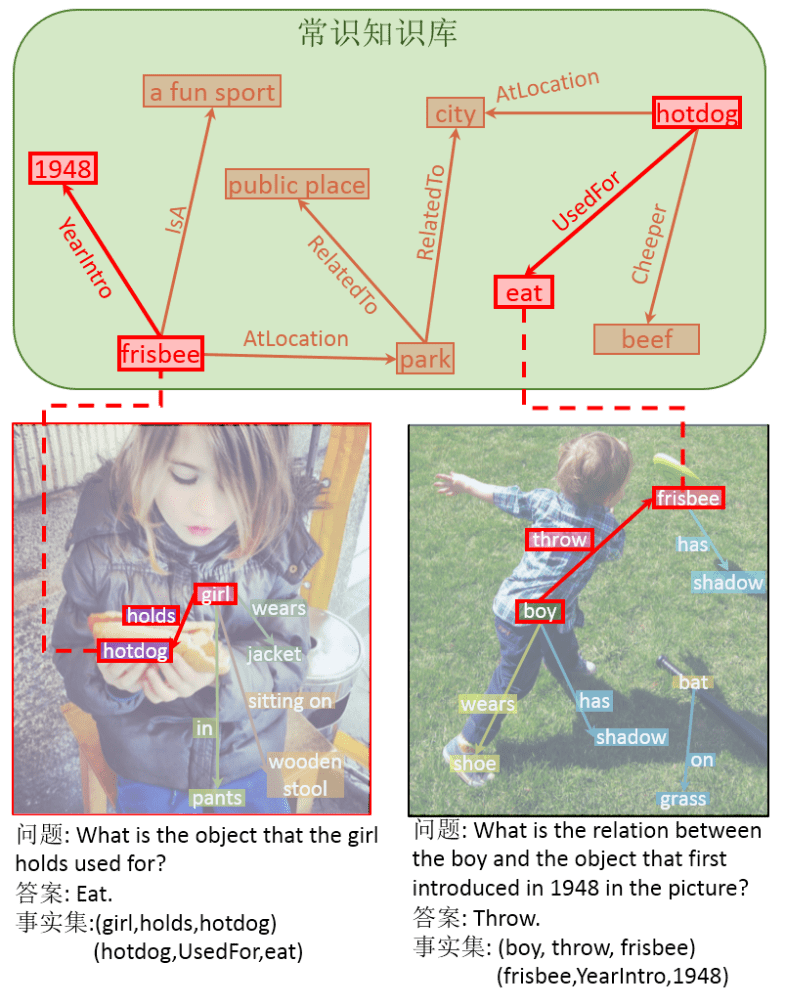
:给定主语 A 和宾语 B , 从图像中获得它们的关系 R 。
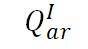
文章图片
:给定主语 A 和关系 R , 从图像中获得宾语 B 。
文章图片
:给定宾语 B 和关系 R , 从图像中获得主语 A 。
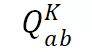
文章图片
:给定主语 A 和宾语 B , 从知识库中获得它们的关系 R 。
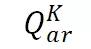
文章图片
【问题|中山大学发布无偏视觉问答数据集,论文登上顶刊TNNLS】:给定主语 A 和关系 R , 从知识库中获得宾语 B 。
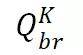
文章图片
:给定宾语 B 和关系 R , 从知识库中获得主语 A 。
通过将每个基本查询的输出作为下个基本查询的输入 , 便可以组成问题的层次化推理结构 , 并作为标注信息 。 例如 , “What is the object that is on the desk used for?”的需要从图像中查询得知是什么在桌子上 , 并在给定前一步查询得到的物体 A 和关系 “UsedFor” 的情况下 , 从知识库中得到桌子上的物体的用处 。
最终 , 根据提取的三元组和模板 , 例如 “(man, holds, umbrella)” 和模板 “what is <A> <R>? <B>” 生成问题答案对“what is the man holding?Umbrella” 。

文章图片
表 2 不同问题类型及对应模板实例
数据集的统计特性
数据集总共包括 32910 个图像 , 193449 个知识三元组和 157201 个问题答案对 。 其中包括 68448 个一步推理问题和 88753 个二步推理问题 , 以及 87193 个外部知识相关问题和 70008 个外部知识无关问题 。
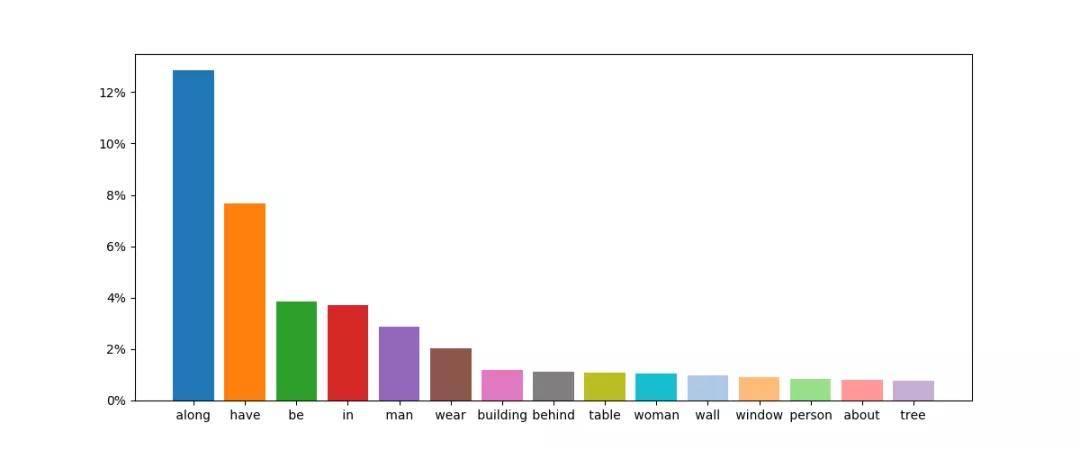
知识库无关的问题中 , 候选答案的数量为 2378 。 候选答案出现的频次在数据集中表现出了长尾分布 。 这使得模型必须准确解析图像 , 找出物体和它们的关系以正确处理图像中显著性不高的物体 。 知识库相关的问题中 , 候选答案的数量为 6536 , 研究者通过限制每个答案的最大出现次数 , 使得知识库相关的问题的答案分布均匀 , 避免模型拟合知识库 。 验证和测试集中 97% 的答案存在于训练集中 , 使得之前基于分类的视觉问答方法也能应用在该数据集上 。
文章图片
图 2 知识相关问题的答案分布
文章图片
图 3 知识无关问题的答案分布
实验
研究者通过评估多个最新视觉问答模型的性能以及包括知识图嵌入和问题编码器预训练等各种知识嵌入方法 , 以检验提出的 KRVQA 数据集的性质 。 其中视觉问答模型包括:
- Q-type 。 对于每个问题 , 使用其问题类型中最频繁的训练答案作为输出答案 。
- LSTM 。 使用双向 LSTM 对问题进行编码 。 并仅用问题编码预测最终答案 。
- 推理路径预测 。 使用双向 LSTM 对问题进行编码 , 并以全监督方式训练和预测推理路径和问题类型 , 以此从场景图和知识库中检索正确答案 。
- Bottom-up attention 。 该方法取得了 2017 年视觉问答挑战赛的第一名方法 。 具有视觉问答模型的经典架构 。
- MCAN 。 模块化共同注意网络(MCAN)为目前在 VQAv2 数据集上不使用额外数据得到最高的性能的方法 , 同时具有与在各种视觉语言任务上预训练的最新模型相似的网络架构结构 。
文章图片
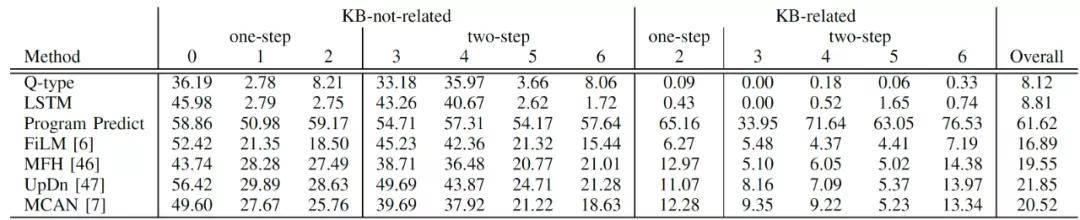
表 2 不同视觉问答方法在 KRVQA 上的准确率
如表 2 所示 , 基线方法 「Q-type」和「LSTM」仅根据问题预测答案 , 准确率大幅低于其他方 。 所有的方法在两步问题上的表现都与一步问题有较大差距 , 在知识相关问题上的准确率也更低 。 这些结果表明 , KRVQA 数据集中的问题需要结合图像上下文和知识进行推理回答 , 多跳推理对现有方法仍具有挑战性 。
知识编码与预训练
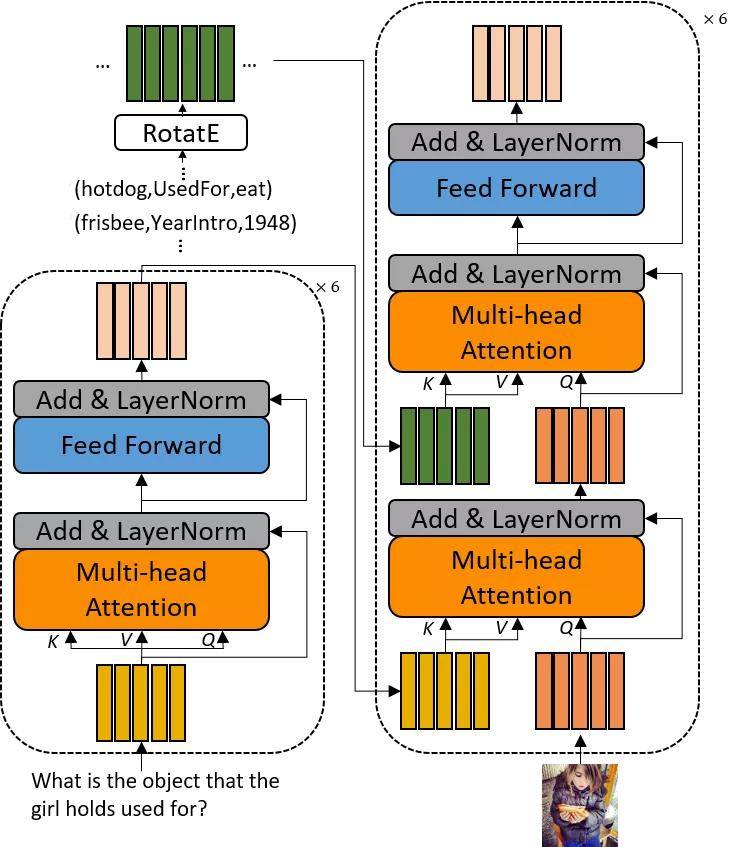
通过在整个知识库上训练 , RotatE 可以对知识库中所有的实体和关系进行编码 , 使得针对三元组有 。 研究者使用 RotatE 对知识库三元组编码 , 并与 VQAv2 数据集上的效果最好之一的 MCAN 基线模型融合 , 如图 4 所示 。
文章图片
图 4 嵌入知识库编码的 MCAN 模型
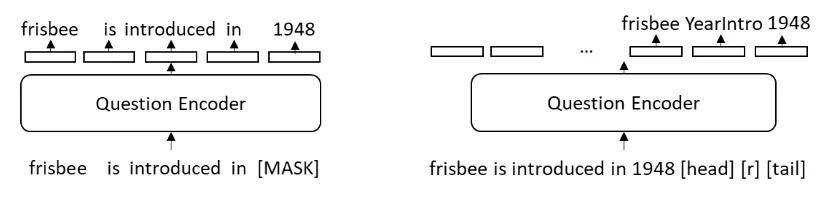
最近的研究表明 , 通过对大量文本的训练 , 语言模型可以在一定程度上对知识进行编码 。 受此启发 , 研究者同样在知识文本上预训练问题编码器 , 对知识进行隐式编码 。 具体地说 , MCAN 的自注意问题编码器将知识三元组的对应文本作为输入 , 然后如图 5 所示预测被掩盖的文本字符或相应的知识三元组 。
文章图片
图 5 用以隐式编码知识库的预训练任务示意
在表三上所示的 KRVQA 结果显示 , 在给定标定的三元组或查询实体时 , 模型能大幅提高在知识相关问题上的结果 。 而在给定除查询实体外的标定三元组 “+knowledge inference” 时 , 由于一副图像可能对应多个知识三元组 , 模型在推理图像答案时仅仅取得了少量提高 。 两个预训练任务则仅仅相对基线方法有稍微的提高 。 这显示了 KRVQA 中知识库的重要性 , 同时说明当前模型在正确感知图像内容以及编码知识库上的不足 。

文章图片
表 3 不同知识库编码方法与 MCAN 基线方法的准确率
推荐阅读







- Samsung|三星预告1月11日发布Exynos 2200芯片组 RDNA 2 GPU加持
- 手机|一加10 Pro宣传视频曝光:将于1月11日14点发布
- Google|谷歌暂缓2021年12月更新推送 调查Pixel 6遇到的掉线断连问题
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 功能|Linux 微信官方版 2.1.1 正式发布
- 人物|造车三兄弟的“喜与忧”:销量暴增但问题加剧,一人舒服两人困难?
- 硬件|闪极140W多口充电器发布:首发399元 支持PD3.1
- 办公|统信UOS助手发布:支持“一键秒传”
- Intel|Intel谈DDR5内存价格贵、缺货问题:新技术升级在所难免
- 最新消息|宝马LG和其他公司正考虑使用量子计算机解决具体问题