图像|NeurIPS'20 | 建模高阶关系的图像检测和分割方法: 新型可学习树形特征变换器
作者:西安交通大学人工智能学院二年级博士生 宋林
NeurIPS 2020 文章专题
第·14·期
本文是西安交通大学人工智能学院联合香港中文大学、中国科学院自动化研究所发表于 NeurIPS 2020的一项工作 。 本工作抛弃了图像中常用的网格 (Grid) 结构形式 , 利用树形结构实现了线性复杂度的高阶关系建模和特征变换 。 在保证全局感受野的同时 , 保留物体的结构信息和细节特征 。 可学习的模块被灵活地应用在了目标检测、语意分割、实例分割和全景分割上 。
本工作有效地弥补了传统二元关系建模方法的不足之处 , 从而在更低的复杂度下 , 即可取得更为显著的性能提升 。 此外 , 本工作提供了高效的GPU实现和PyTorch代码 , 只需要两行代码即可使用 。

文章图片
论文链接:
https://arxiv.org/abs/2012.03482
代码链接:
https://github.com/Megvii-BaseDetection/TreeFilter-Torch
https://github.com/StevenGrove/LearnableTreeFilterV2
更多参考资料:
https://arxiv.org/pdf/1909.12513.pdf
一、传统长距离关系建模方法
首先说一下研究背景 , 为了解决卷积神经网络的有效感受野受限的问题 , 很多基于视觉上下文建模的方法被提出来 。 它们大体上可以被分为两类 , 一类是local-based , 一类是global based 。 其中local-based通过增大卷积的感受野来实现 , 包括dilation convolution , deformable convolution , aspp等等 , 而global based则利用attention机制 , 通过建模二元关系来获得全局感受野 。 然而 , 这些建模一元或二元关系的方法 , 无法感知其他物体的影响 。 例如 , 当两个同类物体被背景隔离 , 这对于instance相关的任务而言 , 期望两者具有较低的相关性 。 但是 , 在没有position encoding的前提下 , 这些方法会输出较高的相关性 。 这反映在可视化上 , 即很难保留物体的细节或者结构化信息 。
【图像|NeurIPS'20 | 建模高阶关系的图像检测和分割方法: 新型可学习树形特征变换器】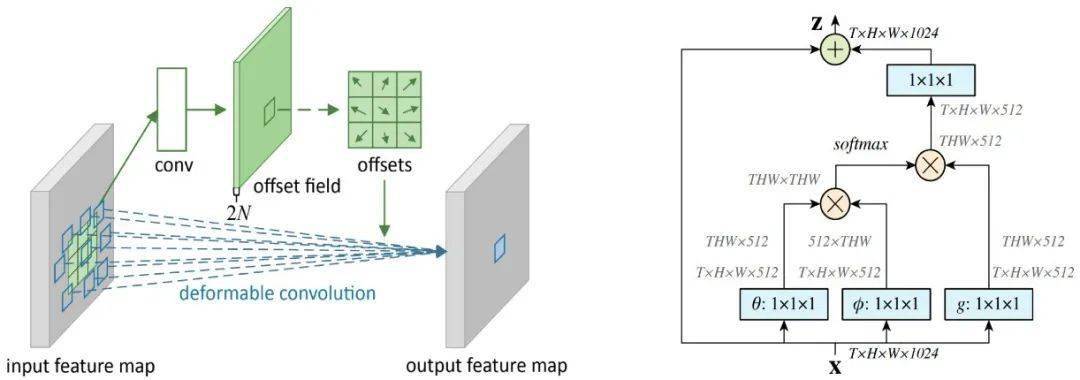
文章图片
图1:传统的上下文建模方法分为local-based (左) 和global-based (右)
二、建模高阶关系的树形特征变换器
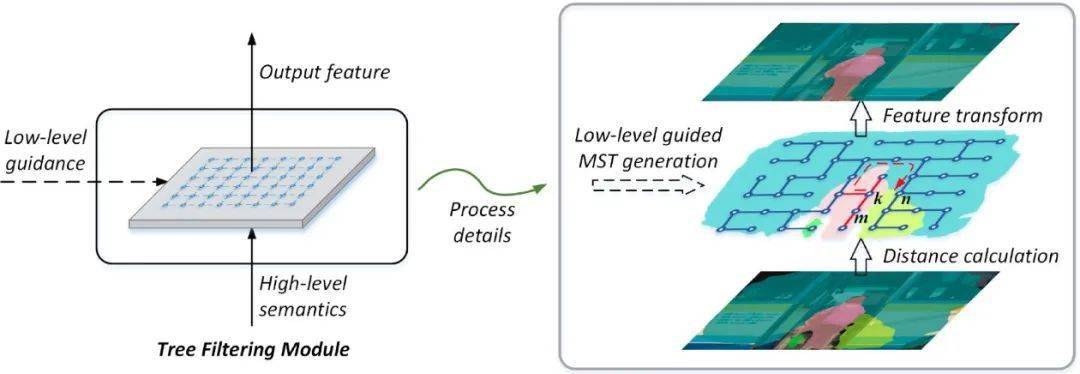
为了解决这个问题 , 我们提出了一篇工作Learnable Tree Filter (https://arxiv.org/pdf/1909.12513.pdf) 。 它利用具有丰富细节信息的低层级特征来构建一颗最小生成树 , 而最小生成树具有一些很好的特性 。 如图2中右侧 , k点和n点分别属于人和车两种不同物体 , 理想情况下我们希望它们之间具有很低的特征相似度 。 但是由于空间距离相近 , 如果只依靠二元关系建模 , 则很难将两者有效地区分开 。
文章图片
图2:Learnable Tree Filter的示意图 , 在树上同一物体内不同节点的距离被拉近 , 而不同物体间的节点则被拉远 。
而最小生成树的构建过程保证了它会优先连接最相近的节点 , 也就是说它会先在人和车的内部进行连接 , 最后再将两者之间进行连接 。 从而 , 可以看到图上k到n的红色箭头 , 它表示的是k到n在树上的路径 。 这个路径的距离等于其中每条边距离的总和 , 因此能够很好地将两者区分开 , 从而达到结构保留的效果 。 这里区别于传统的二元关系建模 , 树上k到n的路径是涉及到多节点间的高阶关系 , 即改变路径中任意一个节点的特征 , 都会改变k到n之间的相关性 。 除此之外 , 由于树是一个无环图 , 因此可以通过动态规划算法来实现线性的计算复杂度(GPU上实际效率也很高 , 具体请参考下文)。
三、灵活的即插即用的模块
文章图片
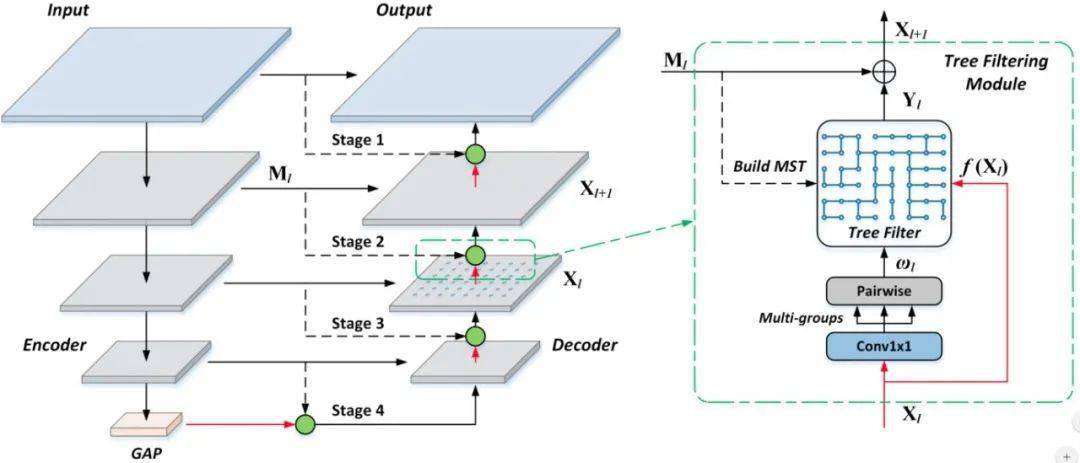
图3:利用Learnable Tree Filter的语义分割网络示意图
当learnable tree filter被打包成一个可微的即插即用的模块 , 就可以很方便地用于各种神经网络的某一层上 。 例如 , 对于语义分割任务 , 我们可以将learnable tree filter (也就是图3中的绿圆) 放在FPN的decoder上 。

文章图片
图4:右侧Heatmap表示与一个锚点 (红色十字叉) 之间的相关性
图4给出了一些相关性的效果展示 , 可以看到左边火车上的两个红色十字差表示两个锚点位置 , 右边的热力图表示与其中一个锚点位置的相似度 。 可以看到 , 采用二元关系建模的non-local (右边NL所示) 它对两个锚点的相似度几乎一致 , 而我们的模型则通过建模结构保留了高阶关系 , 从而有效地将两者进行区分 。 此外 , 对于图4中的细长物体 (旗杆), 二元关系建模的non-local会被背景信息淹没 , 而我们的方法则可以很好地保留结构细节 。
文章图片
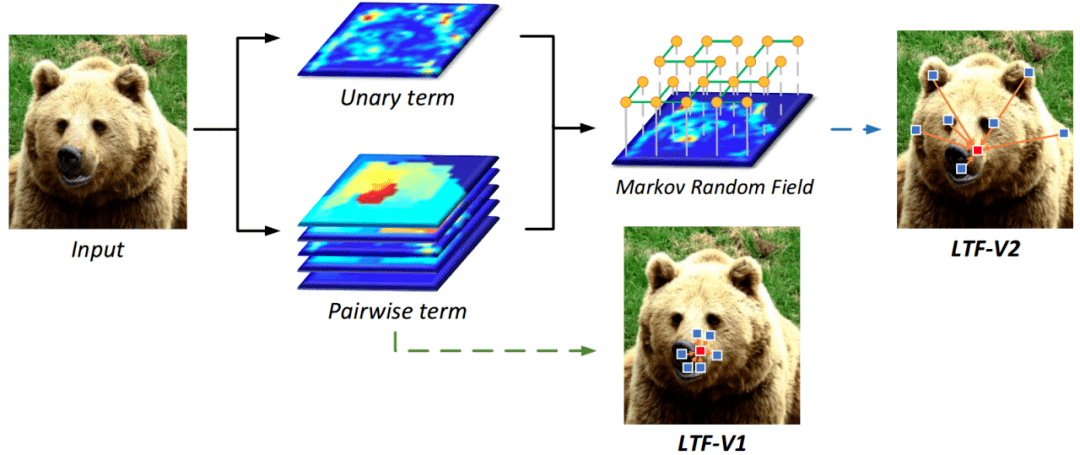
图5:基于改进的Markov Random Field形式的LTF-V2获得了更强大的长距离特征表达能力
四、进一步提升长距离特征表达能力
然而learnable tree filter依然存在一些问题 , 由于树自身具有几何约束 , 导致滤波过程会被限制在一个局部区域内 , 很难与远方的节点进行有效交互 。 另外 , 最小生成树过程是一个不可微的 , 从而降低了模型的通用性和灵活性 。 为了解决第一个问题 , 我们首先利用MRF对learnable tree filter做了重新的建模 (这部分请参考原论文), 然后我们发现对应的MRF的一元项是一个定值 , 而这直接导致了learnable tree filter很难具有长距离的感受野 。
为此 , 我们引入了一个data-dependent的一元项建模形式 。 并利用belief propagation算法得到了闭式解 , 这种新形式的learnable tree filter可以缓解几何约束 , 并且可以高效地与远方节点进行交互 。 另外 , 为了解决最小生成树不可微的问题 , 我们提出了一种可学习的生成树过程 , 从而实现完全的端到端的训练 。
五、目标检测、语意分割和实例分割的应用

文章图片
图6:ground-truth、mask-rcnn和learnable tree filter在COCO实例分割的效果图
有了上面的技术 , 本文给出了实际的运行效果 。 图6是instance segmentation和object detection的效果图 , 左边是ground-truth , 中间是mask-rcnn的结果 , 右边是mask-rcnn+learnable tree filter的结果 。 可以看到learnable tree filter在杯子和勺子的边缘有明显的提升 , 另外检测和分类能力也得到了增强 。

文章图片
图7:learnable tree filter在VOC2012语意分割的效果图
图7给出了语意分割上的效果 , 第一行是输入图片 , 第二行为learnable tree filter的预测 , 第三行为ground-truth 。 其中有个非常有意思的现象 , 比如图中的自行车 , 可以看到即使ground-truth上没有给出辐条的标注 , 利用结构保留的建模 , 我们的算法依然可以将其分割出来 。 另外 , 旗杆、马背、马身的细节也可以有效地保留 。
文章图片
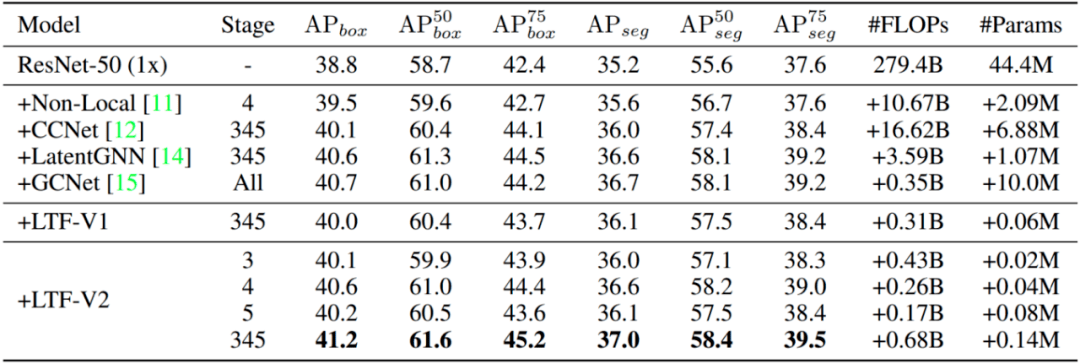
表1:各方法在mask-rcnn (resnet-50 , 1x) 下COCO val set的结果
文章图片
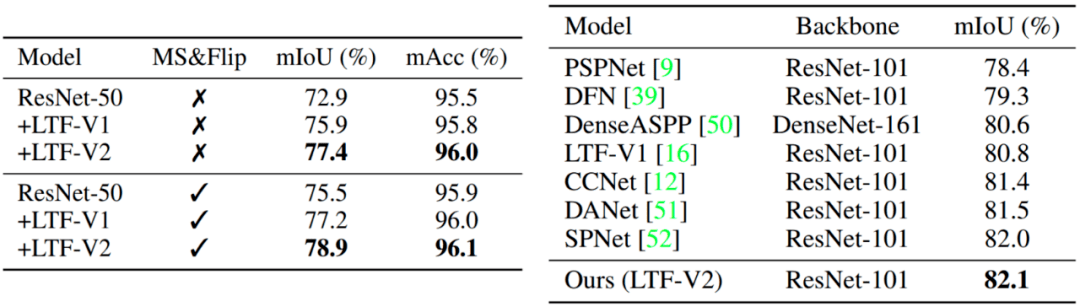
表2:左侧为cityscapes val set右侧为cityscapes test set , 只使用fine数据训练
除此之外 , 这里给出了定量的结果 , 表1的COCO数据集显示 , 我们的算法相当于其他方法 , 只需要用很少的资源就可以实现更高的性能 。 表2显示 , cityscapes的语义分割 , 我们使用简单的FPN结构就可以达到SOTA的结果 。
六、高效灵活 , 两行PyTorch代码即可使用
文章图片
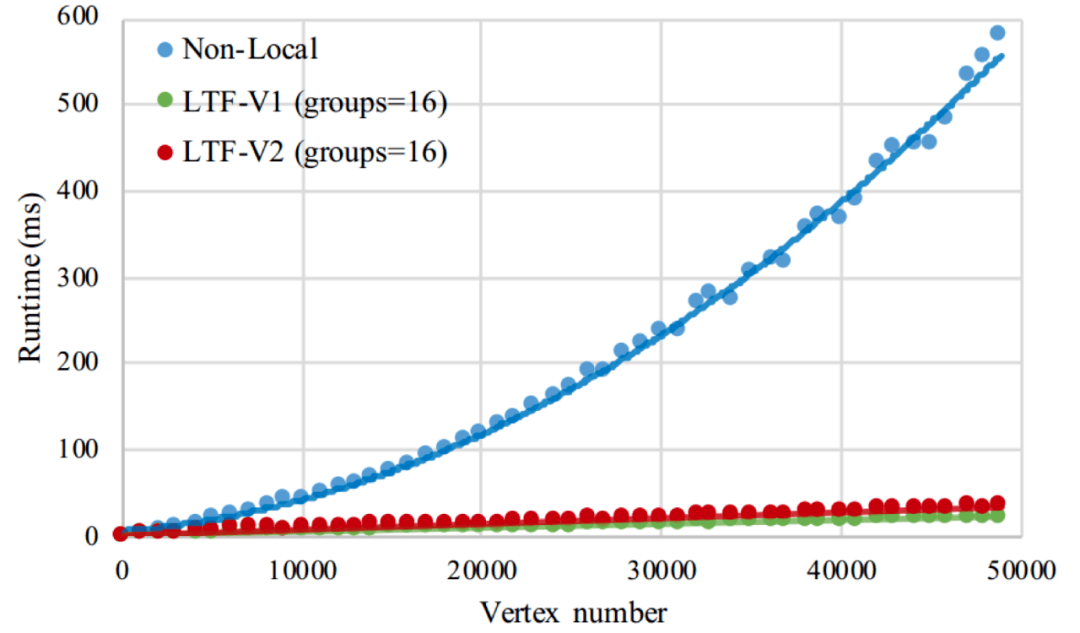
图7:在Tesla V100上的实际运行时间
有些人可能会质疑 , learnable tree filter这种序列操作在GPU这样的并行设备上效率不高 。 我们对cuda代码做了仔细的优化 , 实现batch、channel和同深度节点间的并行 , 并行效率很好 。 下图是我们在一块tesla v100的实测结果 , 可以看到随着节点数的增多 , 我们的算法实现线性的时间增长 , 这在具有大量节点的应用中 , 我们的算法会有很大的优势 。
另外 , 我们还给出了一个很简单的pytorch代码 , 大家只用在原有的pytorch代码中加入两行就可以用learnable tree filter的模块 。
七、丰富的潜在应用场景

文章图片
图8:丰富的潜在应用 , 包括替换transformer , 解迷宫问题和视频特征增强
我们相信learnable tree filter还有很多的潜在应用场景 , 图8给出了三个例子:1) 替换transformer中的attention模块;2) 由于我们算法可以建模高阶关系 , 这可能对因果推断 , 解迷宫也会有帮助;3) 高效的推断可能会帮助视频分析类任务提取高分辨率的时序信息 。
//
作者简介
宋林 , 西安交通大学人工智能学院二年级博士生 , 导师为孙剑和孙宏滨 。 他目前的研究兴趣是通用物体检测、图像分割和视频行为识别与检测 。
个人主页:linsong.me
▼
推荐阅读







- 精度|将建模速率提升10倍,消费级3D扫描仪Magic Swift在2021高交会大显“身手”
- IT|新航空图像拍摄系统Microballoon:可重复使用且成本更低
- 人物|1年级中学生斩获日本U22编程大奖 雕刻方式立体建模
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 画质|海思越影新一代AI ISP图像处理引擎技术硬核
- Lenovo|2022年联想ThinkPad Z系列新品泄露:暂时仅有图像 配置细节不明
- 软件和应用|开发者介绍新颖的QOI图像文件格式 较PNG更具性能优势
- 错误|微软确认 Win11 存在图像编辑器颜色渲染问题,预计 1 月下旬修复
- Samsung|Galaxy S22 Ultra Burgundy 勃艮第色渲染图像抢先看
- Samsung|三星Galaxy S21 FE显示屏维修替换部件图像和价格信息泄露