机器之心专栏
机器之心编辑部
在这篇论文中 , 研究者提出了一个在 reward-space 进行探索的新算法 RPG(Reward-Randomized Policy Gradient) , 并且在存在多个纳什均衡 (Nash Equilibrium, NE) 的挑战性的多智能任务中进行了实验验证 , 实验结果表明 , RPG 的表现显著优于经典的 policy/action-space 探索的算法 , 并且发现了很多有趣的、人类可以理解的智能体行为策略 。 除此之外 , 论文进一步提出了 RPG 算法的扩展:利用 RR 得到的多样性策略池训练一个新的具备自适应能力的策略 。在法国启蒙思想家卢梭(Jean-Jacques Rousseau)的《论人类不平等起源》中 , 提到这样一个猎鹿(StagHunt)故事:一群猎人安静地在陷阱旁等待鹿的出现 , 猎到鹿的收益较大 , 可以让所有猎人都吃饱 , 但是由于鹿十分机敏 , 需要大家都耐心等待 。 这个时候一只兔子出现了 , 兔子体型较小 , 一人便可以成功捕猎 , 但是相应的收益也很小 。
于是每一个猎人有了两个选择:继续等待鹿的出现还是立刻跳起来捕兔?如果猎人选择立刻捕兔 , 那么他可以捕到兔 , 得到较小的收益;如果猎人选择继续等待鹿 , 若所有其他猎人也都选择了继续等待鹿 , 那么他们最终可以猎到鹿 , 得到最大收益 , 但是一旦有任何一个其他猎人选择立刻捕兔 , 那么选择等待鹿的猎人只能挨饿(既没有捕兔 , 也没有机会再猎到鹿) 。

文章图片
图 1:StagHunt 游戏 , a>b>=d>c
我们考虑 2 个猎人的情况 , 然后把各种情况的收益抽象出来 , 就引出了博弈论中非常经典的 2x2 矩阵游戏 StagHunt 。 如图 1 所示 , 每个猎人可以执行两种动作:猎鹿(Stag , 缩写为 S)和捕兔(Hare , 缩写为 H) , 如果两个猎人都选择猎鹿(S , S) , 可以得到最大收益 a(吃饱);如果两人都选择捕兔(H , H) , 得到较小收益 d(需分享兔子);如果一人猎鹿一人捕兔(S , H) , 那么捕兔的人得到收益 b(独自吃兔) , 而猎鹿的人得到最小收益 c(挨饿) 。 这些收益情况满足大小关系 a (吃饱)> b (独自吃兔子)>=d (两个人分享兔子)> c (挨饿) 。

文章图片
图 2:PPO 在 StagHunt 游戏中的表现 , 其中 , a=4 , b=3 , d=1 , 10 个随机种子
在这个游戏中存在两个纯策略纳什均衡(Nash Equilibrium , NE):一个是Stag NE , 即两个猎人都选择等待鹿 , 每一个猎人都可以得到很高的回报 , 但这是一个风险很高的合作策略 。 因为一旦其中一个猎人选择不合作 , 该猎人本身的收益不会发生剧烈变化 -- 从最大收益 a(吃饱)变为收益 b(独自吃兔) , 然而 , 对另一名猎人来说损失却是巨大的 -- 从最大收益 a(吃饱)变为最小收益 c(挨饿) 。 而这个损失(也就是 a-c)越大 , 意味着猎人选择合作的风险也就越高 。 另一个纳什均衡是Hare NE , 即两个猎人都选择捕兔 , 尽管每个猎人只能得到较低的回报 , 但这是一个保守的策略 , 因为无论对方怎么选 , 自己都会获得一定的收益 -- 对方选猎鹿 , 自己获得较大收益 b(独自吃兔) , 对方选捕兔 , 自己获得较小收益 d(分享兔子) 。 在这个任务中 , 现有的强化学习算法会收敛到哪个 NE 呢?作者做了一个实验 , 固定 a=4 , b=3 , d=1 , 变化 c 的取值 , 从图 2 可以看出:独自猎鹿的惩罚越大 , 现有的算法收敛到 Stag NE 的概率会越低 , 也就是更倾向于选择保守的捕兔策略 。 这与之前的分析是也是吻合的 。
那么 , 如何才能让强化学习收敛到收益最优的策略呢?为了解决这个问题 , 来自清华大学、北京大学、UC 伯克利等机构的研究者提出了一个简单有效的技术 , 奖励随机化(Reward Randomization , RR) 。 不同于传统强化学习中的在状态空间(state-space)中进行探索(exploration)的方法 , 奖励随机化是一个在奖励空间(reward-space)进行探索的方法 。 这项研究已被 ICLR 2021 大会接收为 Poster 论文 。

文章图片
论文地址:
https://arxiv.org/abs/2103.04564
如图 3 所示 , 在一个奖励设置比较极端的游戏里 , 强化学习通常很难探索到最优策略(左图 , 灰色区域表示可能收敛到最优解的子空间 , 由于奖励极端而非常狭小);但是同样的策略在其他奖励设置的游戏中可能很容易被探索到(右图) 。 这就演变出论文的核心观点:通过奖励随机化对原始游戏(StagHunt)的奖励(reward)进行扰动 , 将问题转化为在扰动后的游戏中寻找合作策略 , 然后再回到原始游戏中进行微调(fine-tune) , 进而找到最优策略 。
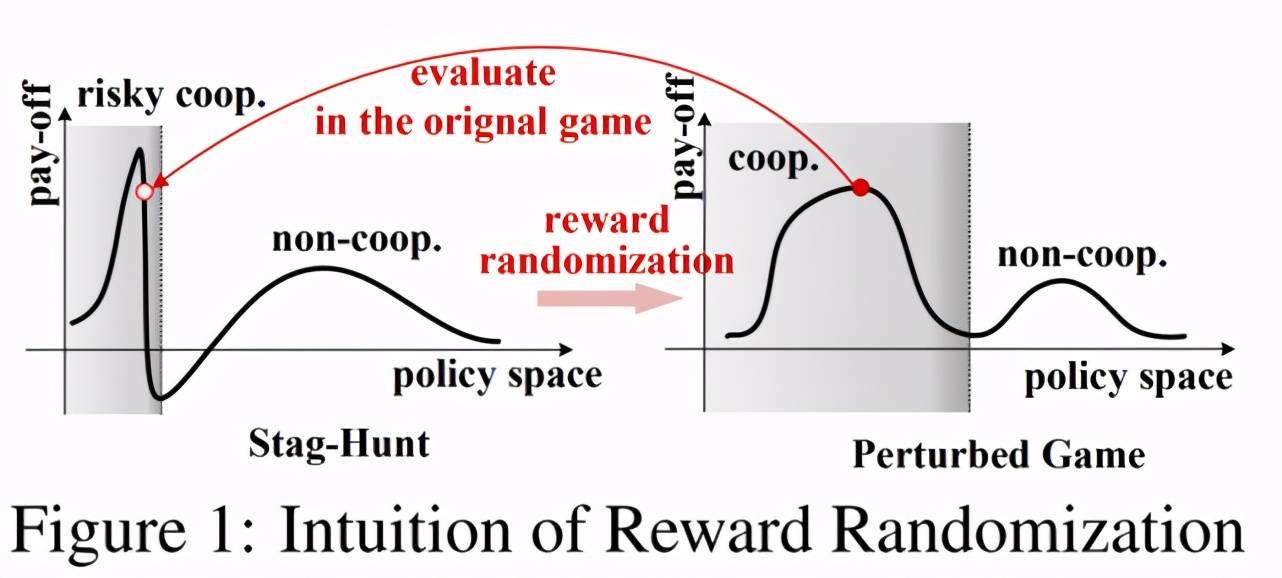
文章图片
图 3:奖励随机化的示意图
进一步地 , 论文将奖励随机化和策略梯度法(Policy Gradient , PG)相结合 , 提出一个在 reward-space 进行探索的新算法 RPG(Reward-Randomized Policy Gradient) 。 实验结果表明 , RPG 的表现显著优于经典的 policy/action-space 探索的算法 , 并且作者还利用 RPG 发现了很多有趣的、人类可以理解的智能体行为策略 。
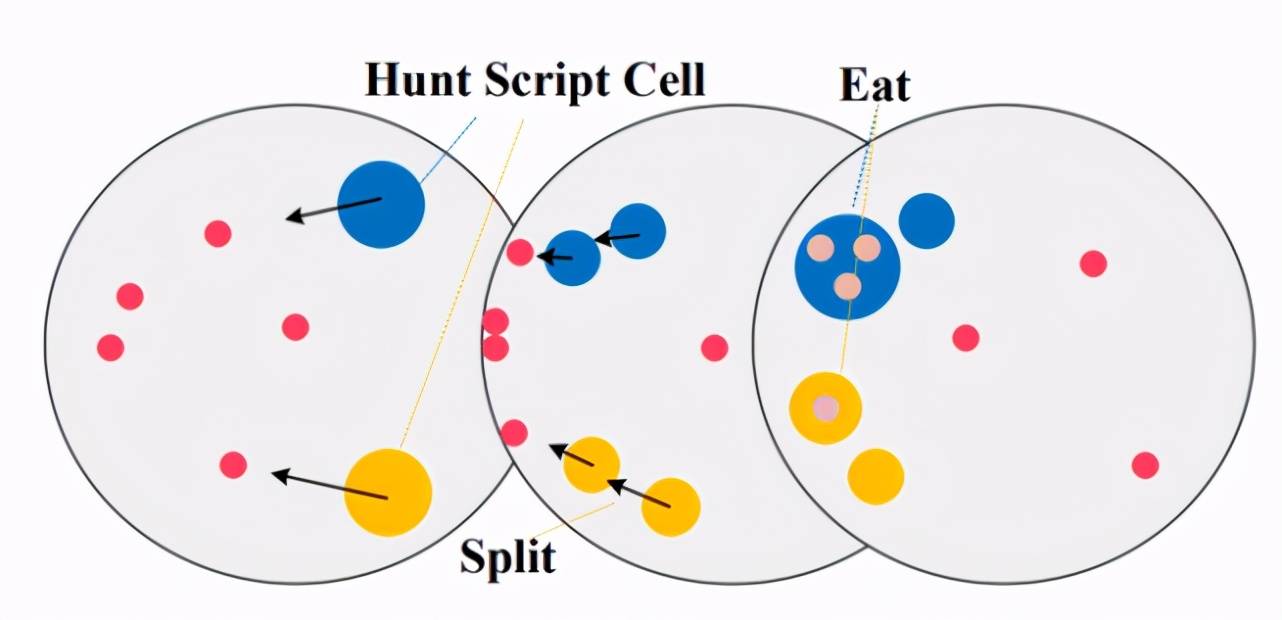
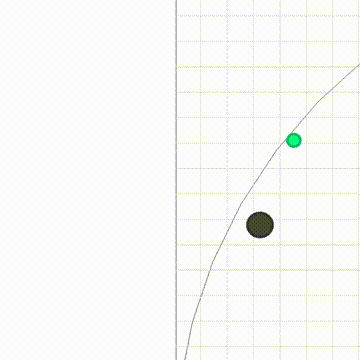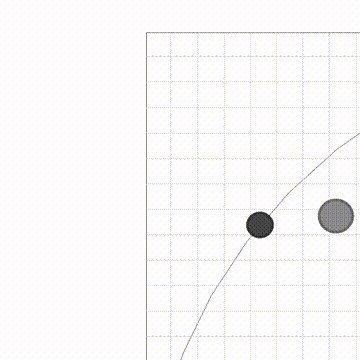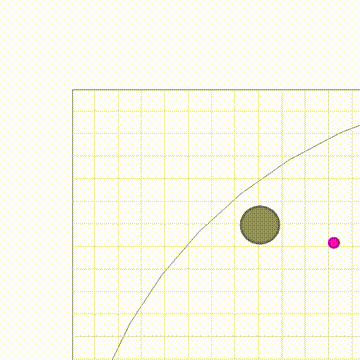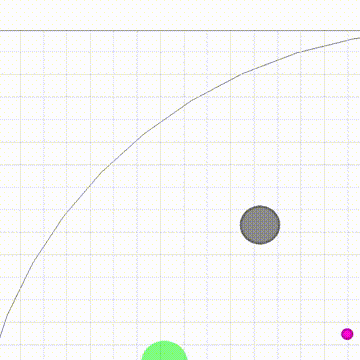
首先 , 论文在 GridWorld 中进行了实验 , 其中有一个任务叫 Monster-Hunt(如图 4 所示) , 这个任务设定是这样的:图中分别用黄色和蓝色表示两个智能体(Agent) , 他们可以在 5*5 格子中移动 , 红色表示怪兽(Monster) , 怪兽可以在格子中随机游走 , 并且怪兽有一个特点是它会朝着离自己最近的智能体移动 。 绿色表示食物苹果(Apple) , 苹果不能移动 。 如果两个智能体同时碰到了怪兽 , 那么每个智能体将会获得 + 5 奖励 , 如果智能体单独碰到了怪兽 , 那么他将会受到 - 2 惩罚 , 智能体也可以吃苹果 , 每个苹果将会带来 + 2 奖励 。 显然 , 在这个任务中存在两个纳什均衡 , 即两个智能体同时遇到怪兽(高风险 , 高收益)或者各自去吃苹果(低风险 , 低收益) 。
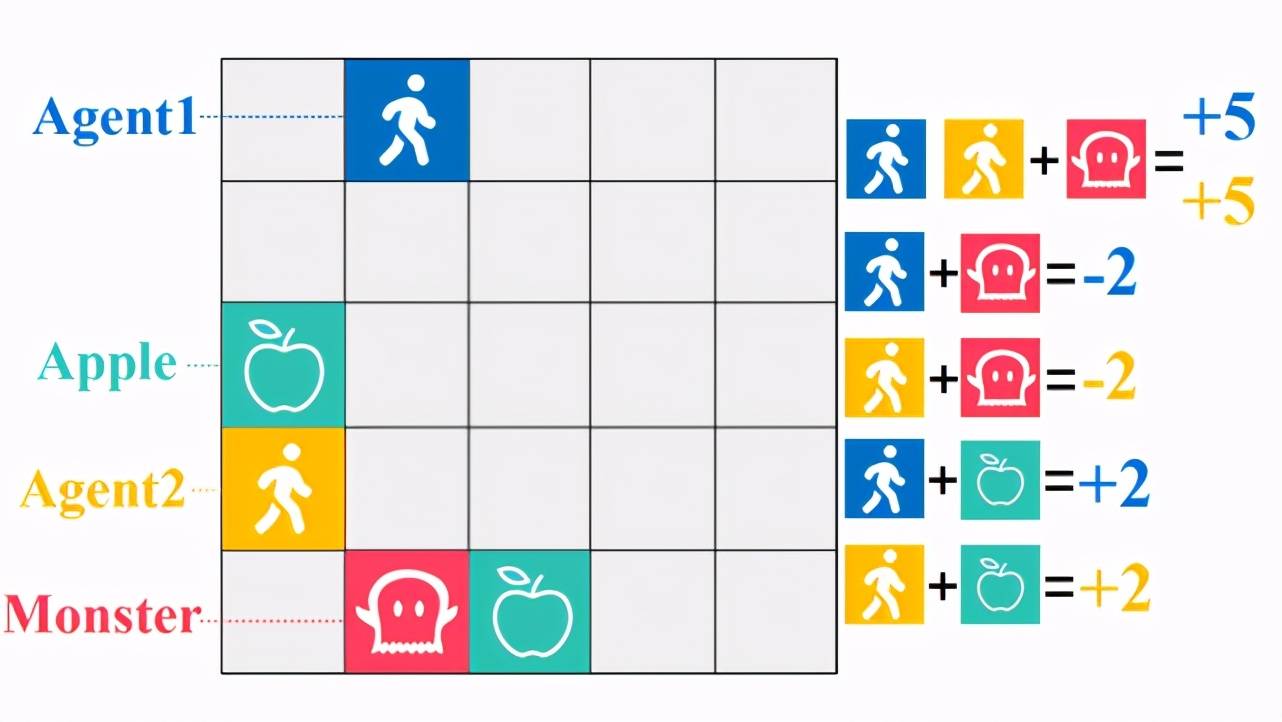
文章图片
图 4:Monster-Hunt 任务示意图
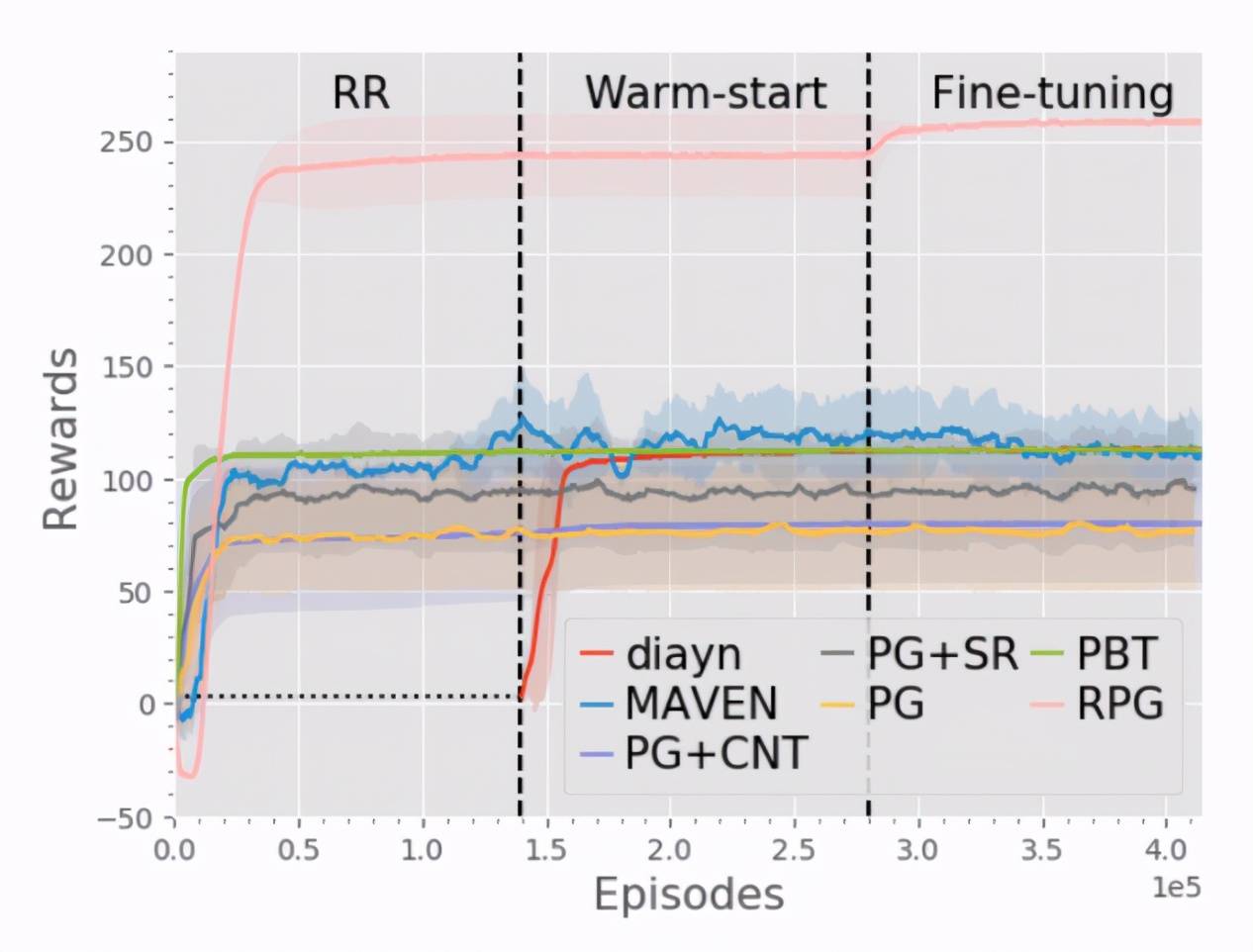
文章图片
图 5:在 Monster-Hunt 任务中不同算法的性能对比
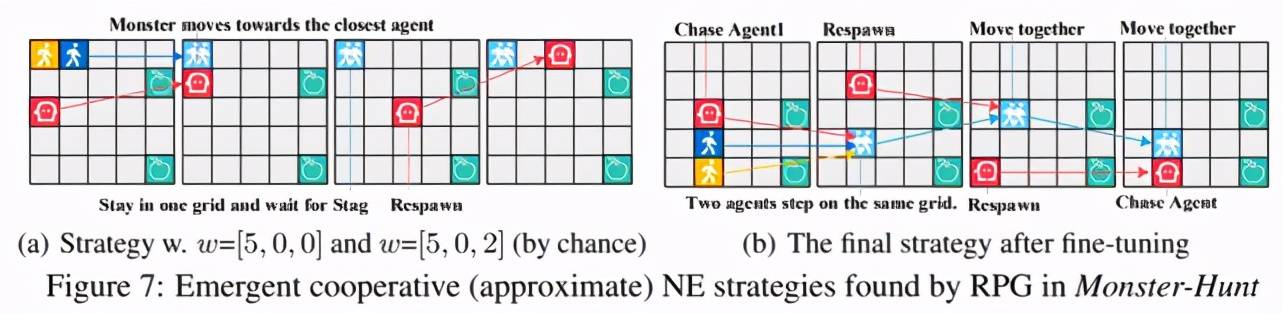
【收益|奖励随机化发现多智能体游戏中多样性策略行为,研究者提全新算法RPG】图 5 给出了 RPG 与不同算法对比的结果 , 这些算法包括标准的策略梯度法、智能体共享奖励的策略梯度法、population-based 算法和一些探索(exploration)算法 , 包括 MAVEN, Count-based 和 Diayn 。 可以看出 RPG 在这个任务中显著优于 baseline 。 并且从图中可以注意到 , 即便 RR 阶段并没有找到最优策略 , RPG 依然可以通过 fine-tune 阶段进一步提升性能 , 找到最优策略 。 那么 , RPG 到底发现了哪些策略呢?除了自然的各自单独吃苹果和单独碰到 Monster , 作者还发现了另外两种合作策略:图 6(a)展示的是发现的次优合作策略 , 游戏开始后 , 两个智能体会移动到 5*5 格子的同一个角落 , 然后合体原地不动 , 因为怪兽的一个特点是会朝着离自己最近的智能体移动 , 因此两个智能体原地不动也会一起碰到怪兽 , 得到较高的收益 , 这个合作策略看起来也十分合理 , 那么还有没有更优的合作策略呢?答案是有的 , 图 6(b)展示的是 RPG 发现的最优策略 , 游戏开始后 , 两个智能体会首先汇合 , 然后合体一起朝着怪兽移动 , 加上怪兽也会朝着智能体移动 , 这就大大加快了一起碰到怪兽的速度 , 因而可以得到更高的收益 。 图 7 是最优合作策略的演示动图 。
文章图片
图 6:Monster-Hunt 任务中两种不同合作策略
文章图片
图 7 Monster-Hunt 任务中最优合作策略演示
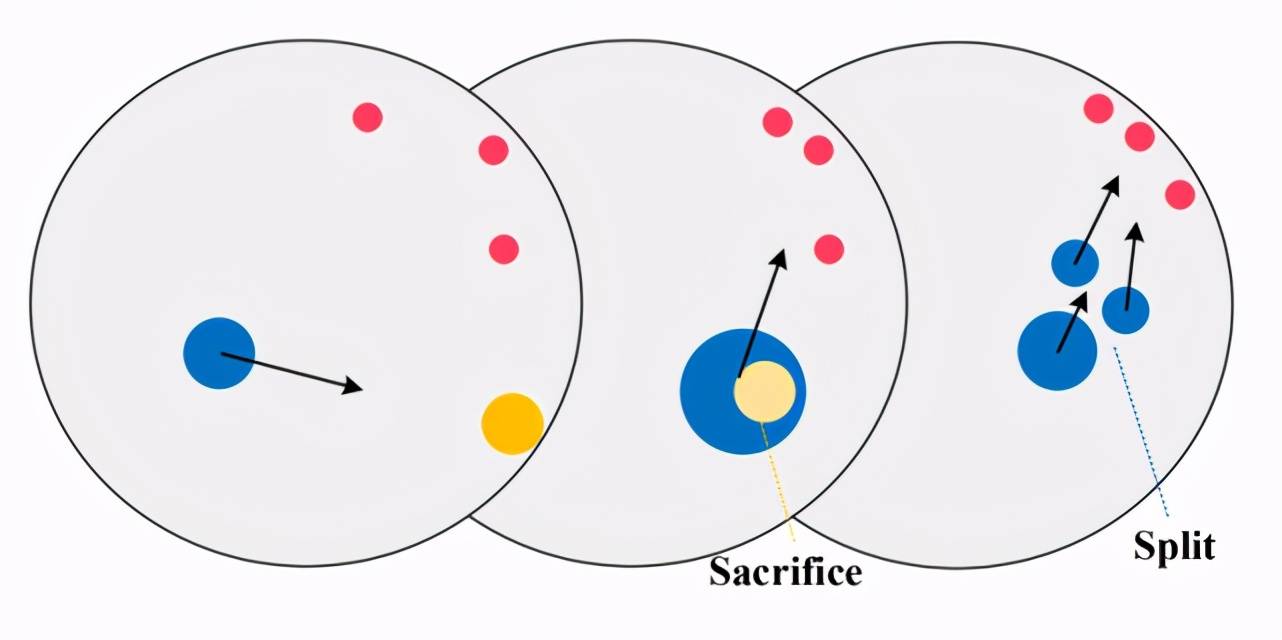
接下来介绍在论文中首次开源的新环境 Agar.io , 这也是该论文的一大贡献 。 Agar.io 是一个非常流行的在线多玩家游戏(游戏地址:http://agar.io) , 每个玩家可以通过鼠标控制运动方向来吃掉比自己小的智能体(可以是食物 , 也可以是其他玩家) 。 论文只考虑 2 个玩家的情况 , 下图(a)表示任务的示意图 , 同样用黄色和蓝色表示两个智能体 。 红色表示地图中随机生成的食物 , 玩家通过吃掉食物或者其他比自己小的玩家来获得奖励(奖励大小等于吃掉的质量) , 同理如果丢掉了质量也会受到相当的惩罚 。 下图(b)表示的是玩家常见的行为 , 例如用过分裂(Split)提高移动速度完成捕食 , 分裂后的部分也可以合并(Merge) 。 随着智能体质量的增大 , 移动速度也越来越慢 , 因此捕猎的难度也越来越大 , 玩家需要合作才能获得更高的收益 。 然而 , 当两个玩家距离较近时 , 质量较大的玩家极有可能选择攻击对于质量较小的玩家 , 从而立刻获得奖励 , 导致合作破裂 。 因此 , 对于质量较小的玩家 , 这种合作策略风险很高 。
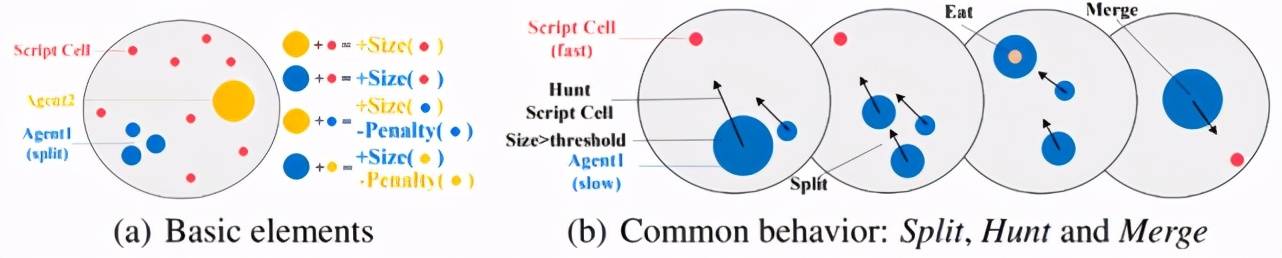
文章图片
图7 Agar.io 任务示意图
如果你是玩家 , 你会选择什么策略呢?带着这个问题 , 看一下 RPG 发现的 7 种有趣的、人类可以理解的玩家策略 。
(1)Cooperative strategy(合作策略 , 图 8):两个玩家合作将食物驱赶至某一区域 , 然后分别捕食 。
文章图片
图 8 (a)Agar.io 任务中的合作策略(Cooperate)

文章图片
图 8 (b)合作演示
(2)Aggressive strategy(倾向攻击策略 , 图 9):两个玩家当两个玩家距离较近时 , 质量较大的玩家选择捕食质量较小玩家 。
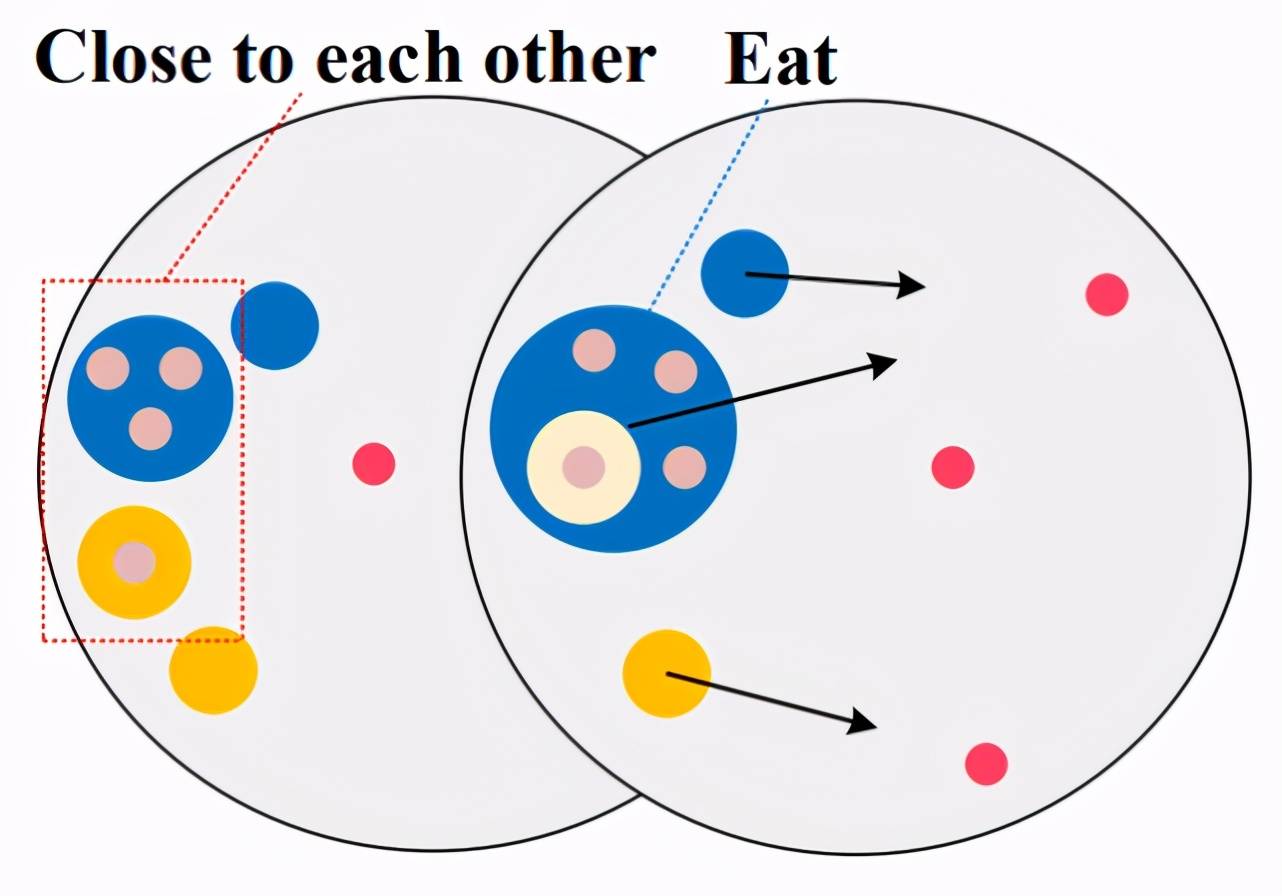
文章图片
图 9 (a)Agar.io 任务中的攻击策略(Attack)
文章图片
图 9 (b)攻击演示
(3)Non-cooperative strategy(非合作策略 , 图 10):两个玩家各自单独捕食 。

文章图片
图 10 Agar.io 任务中单独捕食策略(Non-cooperate)

文章图片
图 11 Agar.io 任务中偶尔攻击策略(Aggressive cooperative)
(4)Aggressive cooperative strategy(偶尔攻击策略 , 图 11):两个玩家大部分时间选择合作 , 偶尔也会发生攻击行为 。
(5)Sacrifice strategy(献祭策略 , 图 12):游戏开始后 , 两个玩家各自捕食 , 一段时间后 , 质量较小的玩家会在地图边界等待 , 将自己献祭给质量较大的玩家 , 由质量较大的玩家控制所有质量进行捕食 。
文章图片
图 12 (a)Agar.io 任务中献祭策略(Sacrifice)

文章图片
图 12 (b)献祭演示
(6)Perpetual strategy(永动机策略 , 图 13):游戏开始后 , 两个玩家各自捕食 , 一段时间后 , 质量较大的玩家会在地图边界等待 , 质量较小的玩家驱赶食物向质量较大玩家靠拢 , 然后捕食 , 之后质量较大的玩家会非常小心地吃掉一部分质量较小的玩家 , 而质量较小的玩家剩下的部分会继续出去驱赶食物 。 一段时间后 , 两个玩家会交换角色 , 周而复始 , 因此称为永动机 。

文章图片
图 13 (a)Agar.io 任务中永动机策略(Perpetual)

文章图片
图 13 (b)永动机演示
(7)Balance strategy(均衡策略 , 图 14):由 RPG fine-tune 之后得到的最优策略实际上是一种在互相献祭 , 单独捕食和合作之间的平衡策略 , 从图 14 可以看出 , 尽管 RPG 学到的策略合作行为略低 , 但它的收益最高 。
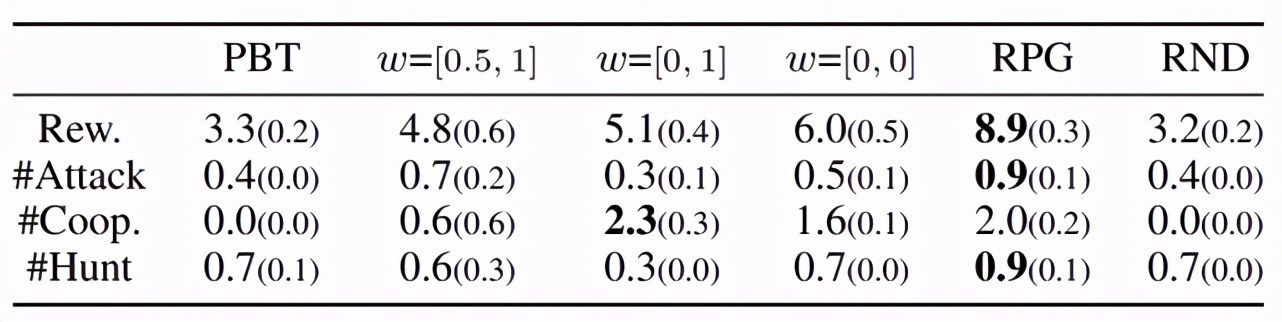
文章图片
图 14 RPG 学出了均衡策略(Balance)
论文的最后给出了 RPG 算法的扩展:利用策略随机化得到的多样性策略池训练一个新的具备自适应能力的策略(Adaptive policy) , 为了验证策略的适应性 , 作者在 Agar.io 种做了一个很有趣的实验:在游戏玩到一半时切换对手玩家的策略 , 然后与 Oracle 策略进行对比 , 如图 15 所示 。 例如 , 当对手玩家策略由合作型切换为竞争型 , Adaptive 策略得到的奖励略低于竞争型策略 , 但显著高于合作型策略;当对手玩家策略由竞争型切换为合作型 , Adaptive 策略得到的奖励略低于合作型策略 , 但显著高于竞争型策略 。 证明训练后的策略确实具有自适应性 。
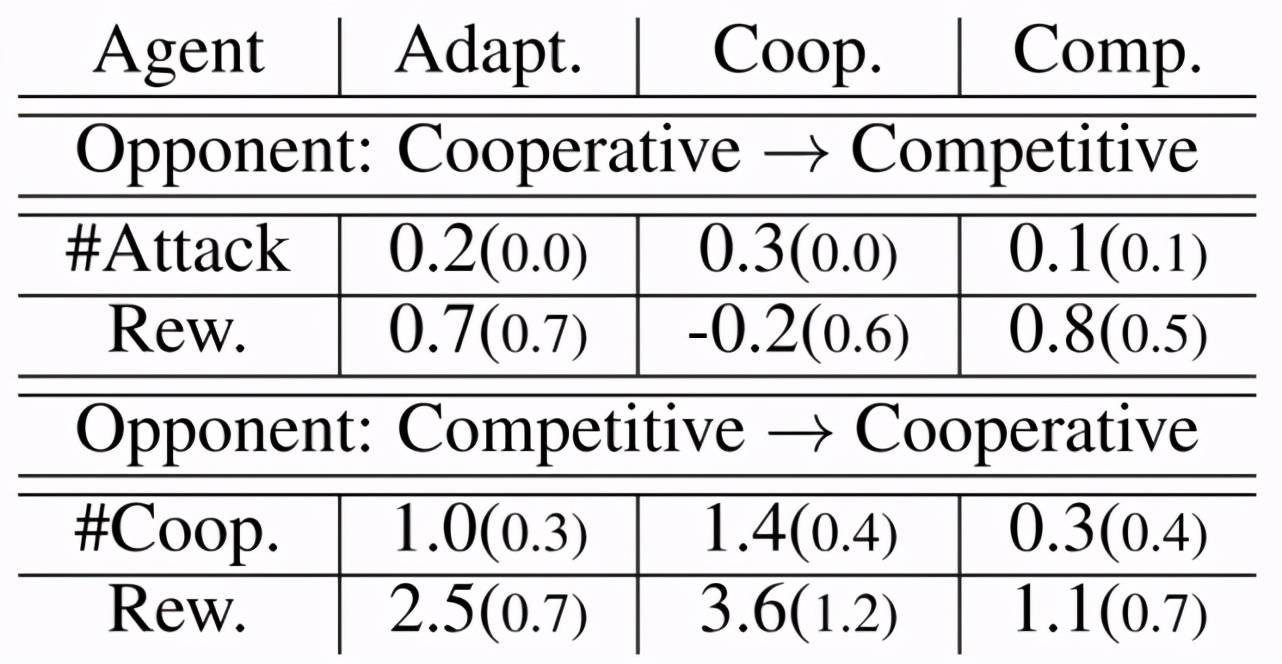
文章图片
图 15 Agar.io 任务中 Adaptive 策略与 Oracle 策略结果对比 , 注意 , 只统计切换策略后的奖励
以上就是论文的主要内容 , 更多详细的实验和分析可以查看论文原文 , 论文的源码以及开发的 Agar.io 环境已经开源 , 代码指路:
https://github.com/staghuntrpg/RPG 。
参考链接:
论文介绍主页:
https://sites.google.com/view/staghuntrpg
推荐阅读







- 国际|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 机器人|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 股票|获取更稳健的收益:趋势策略与因子选股的结合
- Apple|竞争对手挖墙角太厉害 苹果以18万美元特别股票奖励慰留工程师
- 数字货币|ETH 2.0难度炸弹将削薄GPU挖矿收益 但短期内显卡价格不会大跳水
- 硬件|SA:Q3全球智能手机应用处理器市场收益增长17% 海思下降了96%
- 市场|iPhone13卖太火,苹果代工厂疯狂招人,备战过年:推荐奖励上万元!
- Foxconn|iPhone 13备战过年 富士康启动新一轮招工:推荐奖励上万元
- 人物|徒手爬楼救下一家三口 快递小哥被顺丰提拔为中层干部并奖励三万元
- 服务|科技创新贡献突出,萨摩耶云林建明获“高新企业人才奖励”