北理工|ICLR 2022论文双盲通过却被爆抄袭:数据算法照搬,第二页几乎空白
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
最近,一篇已经通过ICLR 2022双盲评审的论文被曝“严重剽窃”!
还是算法直接截图粘贴,图表颜色都不改一下的那种!
就像是这样,直接把ICLR 2020上的一篇论文的算法部分截图,然后粘贴到自己的论文里:
(而原论文的算法部分可复制,也更加清晰)

文章插图
还有架构图部分,除了标注了“引用”的那句话,其余的从架构图本身到图表下的说明,都与EMNLP 2020的一篇论文分毫不差:

文章插图
不仅是算法和架构图,摘要、正文、实验结果部分也存在着大量的Ctrl+C内容。
现在,这篇论文已经被项目主席以“严重剽窃”为由直接Desk Reject:
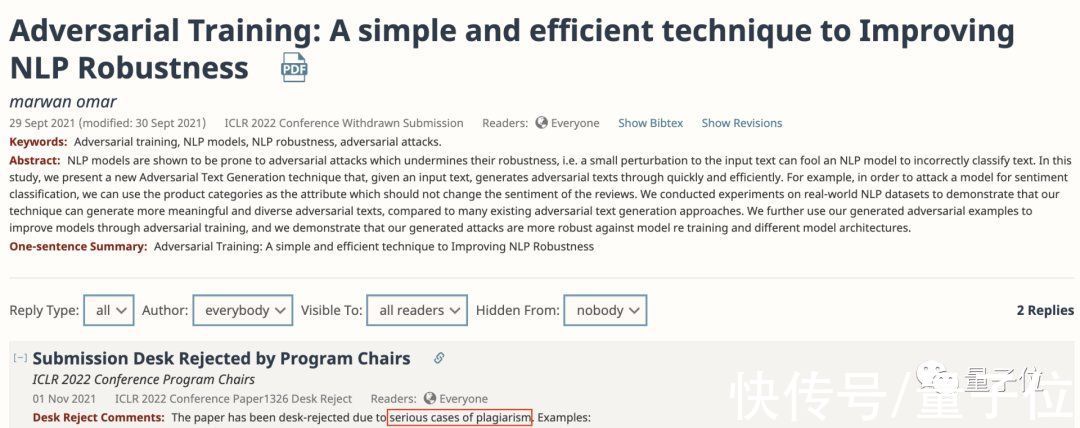
文章插图
而点进作者的个人资料链接,能看到他的大部分工作内容都与网络安全相关,并没有发表过任何机器学习领域的论文。
文章插图
【 北理工|ICLR 2022论文双盲通过却被爆抄袭:数据算法照搬,第二页几乎空白】但他抄袭的两篇论文,偏偏都来自于机器学习领域的顶会:

文章插图

文章插图
跨界抄袭、低得可笑的论文质量、草率而毫不掩饰的剽窃行为,种种现象甚至都让网友怀疑:
这简直就像是同行评议人的“虚拟测试”……作者不会真觉得别人发现不了他的抄袭吧?

文章插图
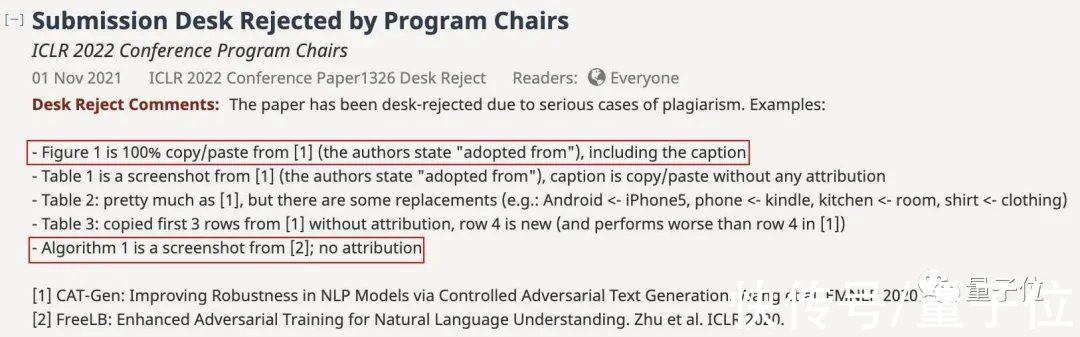
「忠实原著」的论文接下来,就让我们顺着ICLR项目主席列出的五条抄袭的证据,来看看这篇论文。

文章插图
五条证据分别指出的分别是图表和算法几个部分。
但实际上,涉事论文从摘要就已经开始了它的表演。
在论文摘要中,作者提出了一种新的对抗性文本生成模型Text-Gen,能够生成更有意义和多样性的对抗性文本:

文章插图
但如果和ICLR 2020里的这篇提出了CAT-Gen模型的论文摘要做个在线文本对比……

文章插图
△红色部分是不同处
好家伙,你搁这儿找不同呢?
摘要过后,马上就是这样一页:
(持续往下拉,没错,大片空白的第二页)

文章插图
开头所展示的流程图和算法也就是项目主席列出的第一条和第五条:
图像100%复制粘贴还注明了引用;
来自其他论文的算法截图则根本就没有注明。
文章插图
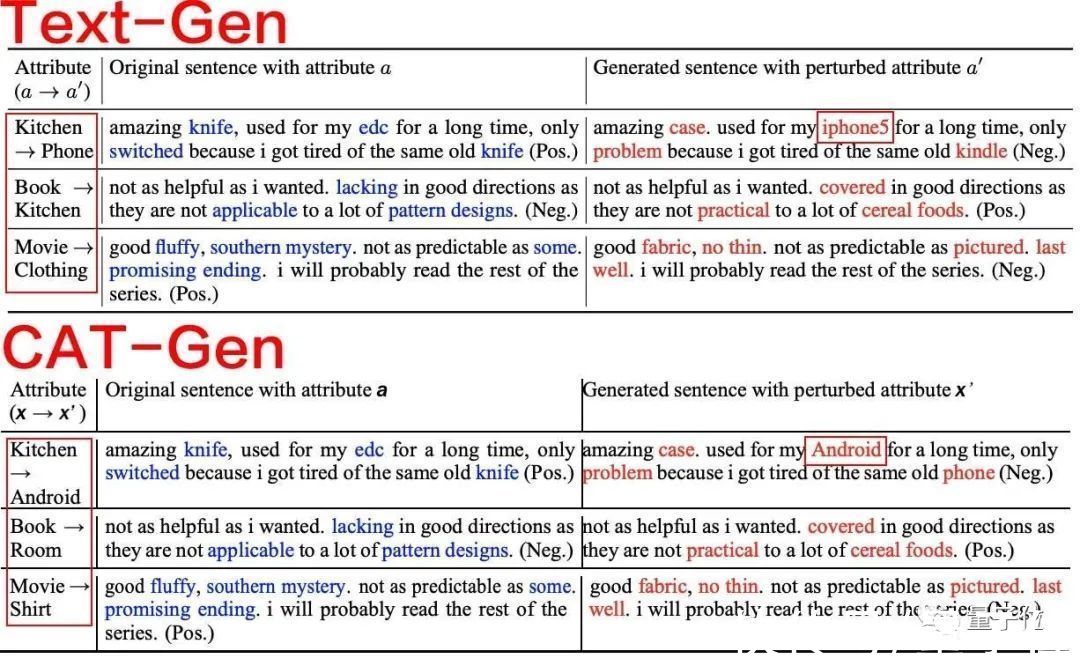
而剩下的三条展示实验结果的表格也是如法炮制,要么是无引用的直接截图粘贴:

文章插图
要么就是将原表格中的Android、phone、kitchen、shirt等名词“别出心裁”地换成了iPhone5、kindle、room、clothing……
文章插图
还有“良心发现”修改了数据的Table 3,却被评委无情吐槽:
你这数据还没原文的好,不如不改……
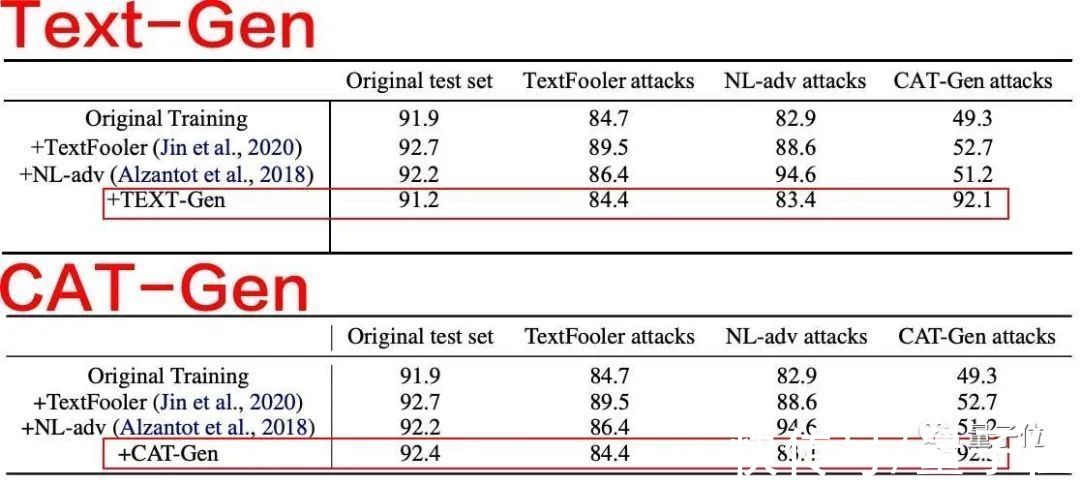
文章插图
推荐阅读







- 甜玉米|北上广一站购齐,大乡村年货升级:拼多多30亿红包聚焦全国全球尖货好物
- 集团有限公司|信用赋能发展!石景山园荣膺“北京市创新信用领跑园区”称号
- 质量|北京消协实测8个品牌代餐粉质量:多款核心营养素不合规
- 公积金|北京金融公共数据专区汇集数据25亿条,覆盖14个部门机构
- 中轴线|云上现中轴,数字化「你好,北京」
- 北京市朝阳区市场监督管理局|消费者下单付款成功不发货“十荟团”运营主体被重罚30万元
- 红包|北上广一站购齐,大乡村年货升级:拼多多30亿红包聚焦全国全球尖货好物
- 上海金山|“国际国内的物流就都通了!”北仑企业生产发货忙
- 北交所|徐明:创新型中小企业不仅包括“专精特新”类型企业
- 农村电商|绵阳北川:升级农村电商 开启乡村振兴新征程