机器之心报道
机器之心编辑部
人类每天使用数字设备的时间长达数十亿小时 。 如果我们能够开发出协助完成一部分这些任务的智能体 , 就有可能进入智能体辅助的良性循环 , 然后根据人类对故障的反馈 , 改进智能体并使其获得新的能力 。 DeepMind 在这一领域有了新的研究成果 。如果机器可以像人类一样使用计算机 , 则可以帮助我们完成日常任务 。 在这种情况下 , 我们也有可能利用大规模专家演示和人类对交互行为的判断 , 它们是推动人工智能最近取得成功的两个因素 。
最近关于 3D 模仿世界中自然语言、代码生成和多模态交互行为的工作(2021 年 DeepMind 交互智能体团队)已经产生了具备卓越表达能力、上下文感知和丰富常识的模型 。 这项研究有力地证明了以下两种组件的力量:机器与人类之间一致的丰富、组合输出空间;为机器行为提供信息的大量人类数据和判断 。
具备这两种组件但受到较少关注的一个领域是数字设备控制(digital device control) , 它包括使用数字设备来完成大量有用任务 。 由于几乎完全使用数字信息 , 该领域在数据采集和控制并行化方面具有很好的扩展性(与机器人或聚变反应堆相比) 。 该领域还将多样化、多模态输入与富有表达能力、可组合且兼容人类的可供性相结合 。
近日 , 在 DeepMind 的新论文《A Data-driven Approach for Learning to Control Computers》 , 研究者重点探究了训练智能体像人一样进行键盘和鼠标的基本计算机控制 。

文章图片
论文地址:https://arxiv.org/pdf/2202.08137.pdf
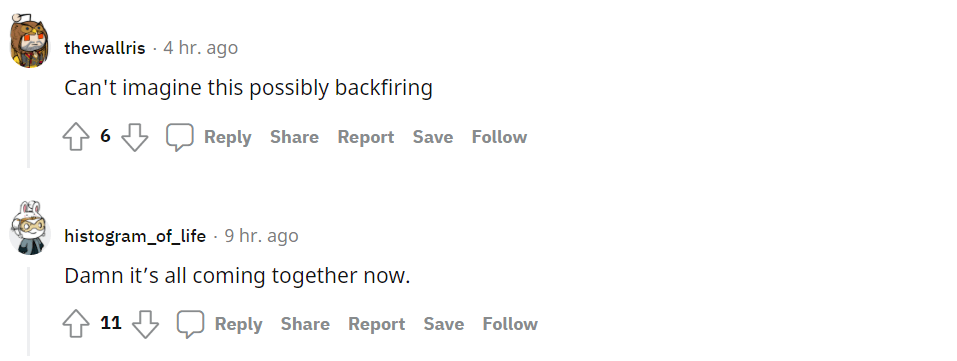
DeepMind 对计算机控制进行初步调查采用的基准是 MiniWob++ 任务套件(一组具有挑战性的计算机控制问题) , 它包含一组执行点击、打字、填写表格和其他此类基本计算机交互任务的指令(下图 1 b) 。 MiniWob++ 进一步提供了以编程方式定义的奖励 。 这些任务是迈向更开放人机交互的第一步 , 其中人类使用自然语言指定任务并提供有关性能的后续判断 。
研究者重点训练智能体来解决这些任务 , 使用的方法在原则上适用于任何在数字设备上执行的任务 , 并且具备符合预期的数据和计算扩展特性 。 因此 , 他们直接结合强化学习(RL)和行为克隆(BC)两种技术 , 其中行为克隆通过人类与智能体行动空间之间的对齐来辅助完成(也就是键盘和鼠标) 。
具体地 , 研究者探究使用键盘和鼠标进行计算机控制 , 并通过自然语言指定对象 。 并且 , 他们没有专注于手工设计的课程和专门的行动空间 , 而是开发了一种基于强化学习的可扩展方法 , 并结合利用实际人机交互提供的行为先验 。
这是 MiniWob(2016 年由 OpenAI 提出的一种与网站交互的强化学习智能体的基准 , MiniWob++ 是它的扩展版本)构想中提出的一种组合 , 但当时并未发现可以生成高性能智能体 。 因此 , 之后的工作试图通过让智能体访问特定 DOM 的操作来提升性能 , 并通过受限的探索技术使用精心策划的指导来减少每个步骤中可用的行动数量 。 通过重新审视模仿与强化学习的简单可扩展组合 , 研究者发现实现高性能主要的缺失因素仅是用于行为克隆的人类轨迹数据集的大小 。 随着人类数据的增加 , 性能会可靠地提升 , 使用的数据集大小是以往研究中的 400 倍 。
研究者在 MiniWob++ 基准测试中的所有任务上都实现了 SOTA 和人类平均水平 , 并找到了跨任务迁移的强有力证据 。 这些结果证明了训练机器使用计算机过程中统一的人机界面非常有用 。 总之 , 研究者结果展示了一种超越 MiniWob++ 基准测试能力以及像人类一样控制计算机的方案 。
对于 DeepMind 的这一研究 , 网友大都惊呼「不可思议」 。
文章图片
方法
MiniWob++
MiniWob++ 是 Liu 等人在 2018 年提出的基于 web 浏览器的套件 , 是早期 MiniWob(Mini World of Bits)任务套件的扩展 , 而 MiniWoB 是一个用于与网站交互的强化学习基准 , 其可以感知小网页(210x160 像素)的原始像素和产生键盘和鼠标动作 。 MiniWob++ 任务范围从简单的按钮点击到复杂的表单填写 , 例如 , 在给出特定指令时预订航班(图 1a) 。
之前关于 MiniWob++ 的研究已经考虑了能够访问 DOM 特定动作的架构 , 从而允许智能体直接与 DOM 元素交互而无需鼠标或键盘导航到它 。 DeepMind 的研究者选择仅使用基于鼠标和键盘的操作 , 并进一步假设该接口将更好地迁移到计算机控制任务 , 而无需与紧凑的 DOM 进行交互 。 最后 , MiniWob++ 任务需要单击或拖动操作 , 而这些操作无法通过基于 DOM 元素的操作来实现(参见图 1b 中的示例) 。
与之前的 MiniWob++ 研究一样 , DeepMind 的智能体可以访问由环境提供的文本字符串字典 , 该字典被输入到给定任务的输入字段中(参见附录图 9 示例) 。
下图为运行 MiniWob++ 的计算机控制环境 。 人类和智能体都使用键盘和鼠标控制计算机 , 人类提供用于行为克隆的示范行为 , 智能体受过训练以模仿这种行为或表现出追求奖励的行为 。 人类和智能体尝试解决 MiniWob++ 任务套件 , 其中包括需要单击、键入、拖动、填写表格等 。
文章图片
环境接口
如果想要智能体像人类一样使用计算机 , 它们需要接口来传输和接收观察结果和动作 。 最初的 MiniWob++ 任务套件提供了一个基于 Selenium 的接口 。 DeepMind 决定实现一个可替代环境堆栈 , 旨在支持智能体可以在 web 浏览器中实现各种任务 。 该接口从安全性、特性和性能方面进行了优化 (图 1a) 。
原来的 MiniWob++ 环境实现通过 Selenium 访问内部浏览器状态并发出控制命令 。 相反 , DeepMind 的智能体直接与 Chrome DevTools 协议 (CDP) 交互 , 以检索浏览器内部信息 。
智能体架构
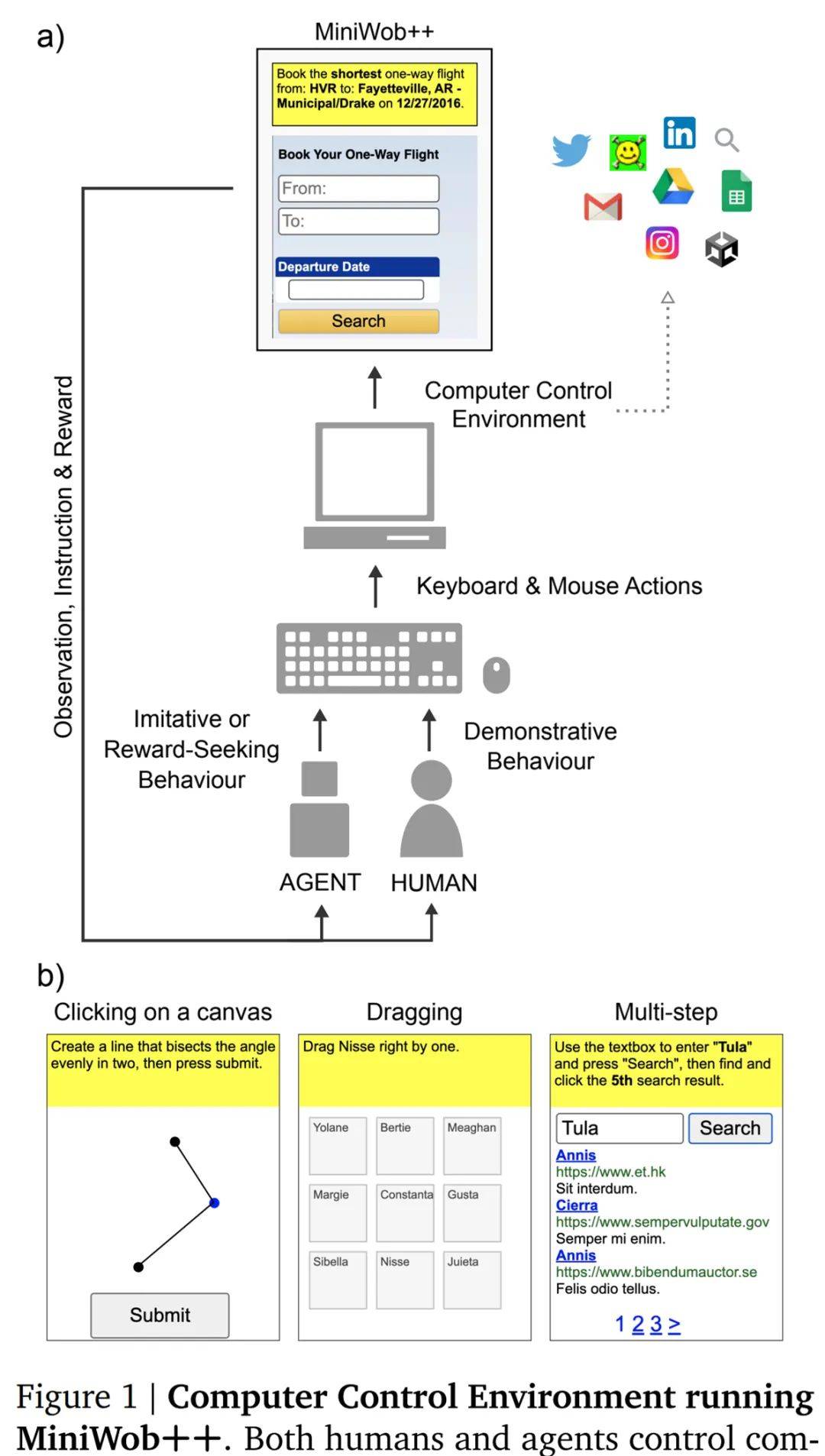
DeepMind 发现没有必要基于专门的 DOM 处理架构 , 相反 , 受最近关于多模态架构的影响 , DeepMind 应用了最小模态特定处理 , 其主要依靠多模态 transformer 来灵活处理相关信息 , 如图 2 所述 。
文章图片
【训练|AI键盘侠来了:DeepMind开始训练智能体像人一样「玩」电脑】感知 。 智能体接收视觉输入(165x220 RGB 像素)和语言输入(示例输入显示在附录图 9 中) 。 像素输入通过一系列四个 ResNet 块 , 具有 3×3 内核 , strides 为 2、2、2、2 , 以及输出通道(32、128、256、512) 。 这产生了 14×11 的特征向量 , DeepMind 将其展平为 154 个 token 列表 。
三种类型的语言输入任务指令、DOM 和任务字段使用同一个模块处理:每个文本字符串被分成 token , 每个 token 映射被到大小为 64 的嵌入 。
策略:智能体策略由 4 个输出组成:动作类型、光标坐标、键盘键索引和任务字段索引 。 每个输出都由单个离散概率分布建模 , 除光标坐标外 , 光标坐标由两个离散分布建模 。
动作类型是从一组 10 种可能的动作中选择的 , 其中包括一个无操作(表示无动作)、7 个鼠标动作(移动、单击、双击、按下、释放、上滚轮、下滚轮)和两个键盘动作(按键、发出文本) 。
DeepMind 从 77 名人类参与者那里收集了超过 240 万个 104 MiniWob++ 任务演示 , 总计大约 6300 小时 , 并使用模仿学习和强化学习 (RL) 的简单混合来训练智能体 。
实验结果
MiniWob++ 上的人类水平性能
由于大部分研究通常只解决了 MiniWob++ 任务的一个子集 , 因此该研究在每个单独的任务上采用已公开的最佳性能 , 然后将这些子任务的聚合性能与该研究提出的智能体进行比较 。 如下图 3 所示 , 该智能体大大超过了 SOTA 基准性能 。

文章图片
此外 ,该智能体在 MiniWob++ 任务组件中实现了人类水平的平均性能 。 这种性能是通过结合 BC 和 RL 联合训练来实现的 。

文章图片
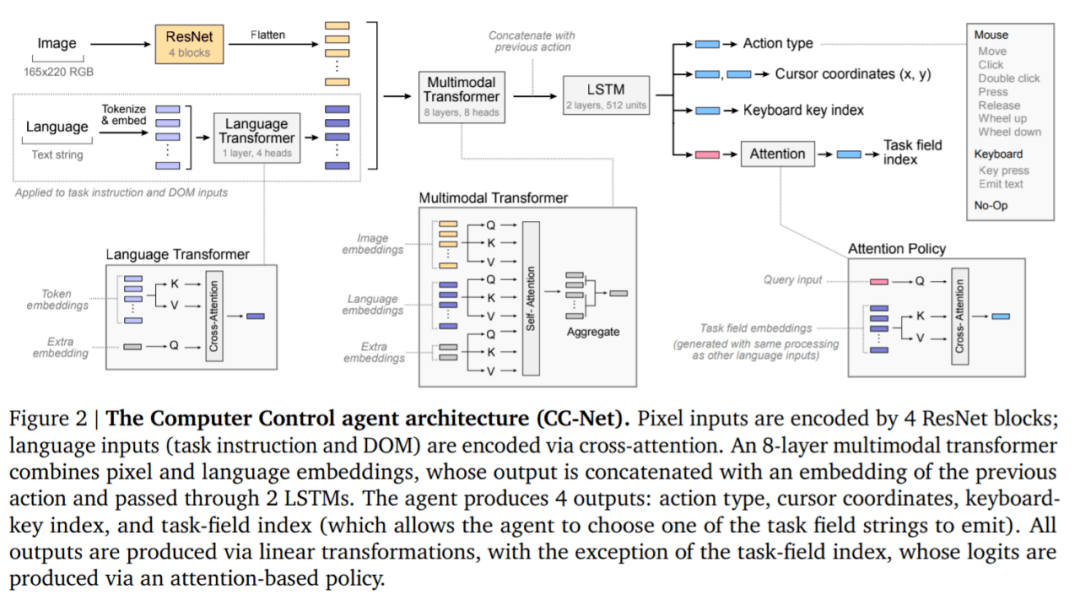
研究者发现 , 虽然该智能体的平均性能与人类相当 , 但有些任务人类的表现明显优于该智能体 , 如下图 4 所示 。
文章图片
任务迁移
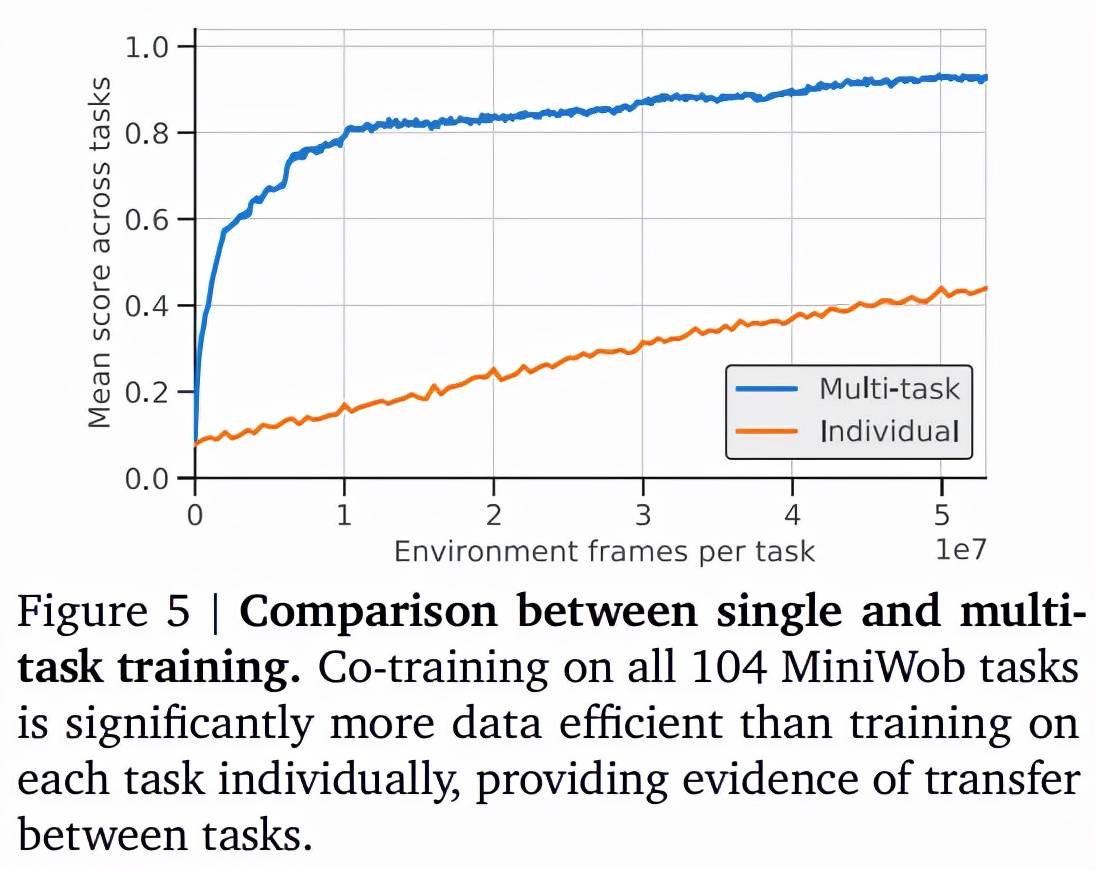
研究者发现 , 与在每个任务上单独训练的智能体相比 , 在 MiniWob++ 的全部 104 个任务上训练一个智能体可以显著提升性能 , 如下图 5 所示 。
文章图片
扩展
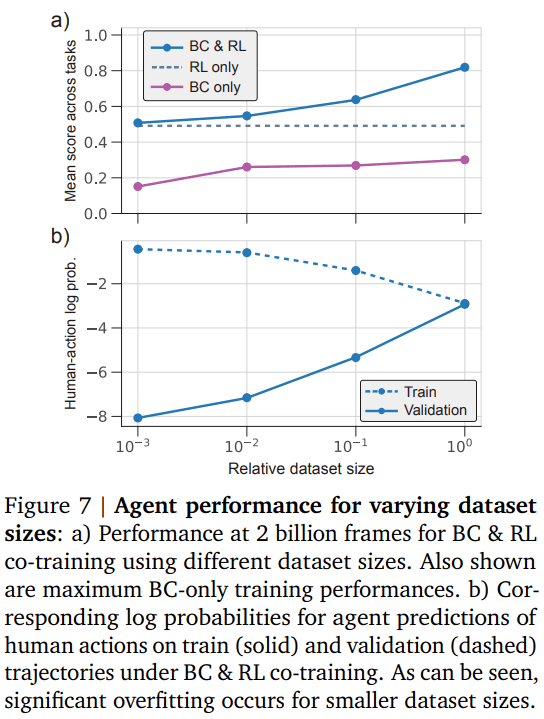
如下图 7 所示 , 人类轨迹数据集(human trajectory dataset)的大小是影响智能体性能的关键因素 。 使用 1/1000 的数据集 , 大约相当于 6 小时的数据 , 会导致快速过拟合 , 并且与仅使用 RL 的性能相比没有显著提升 。 随着该研究将此基线的数据量增加到三个数量级直至完整数据集大小 , 智能体的性能得到了持续的提升 。
文章图片
此外 , 研究者还注意到 , 随着算法或架构的变化 , 在数据集大小上的性能可能会更高 。
消融实验
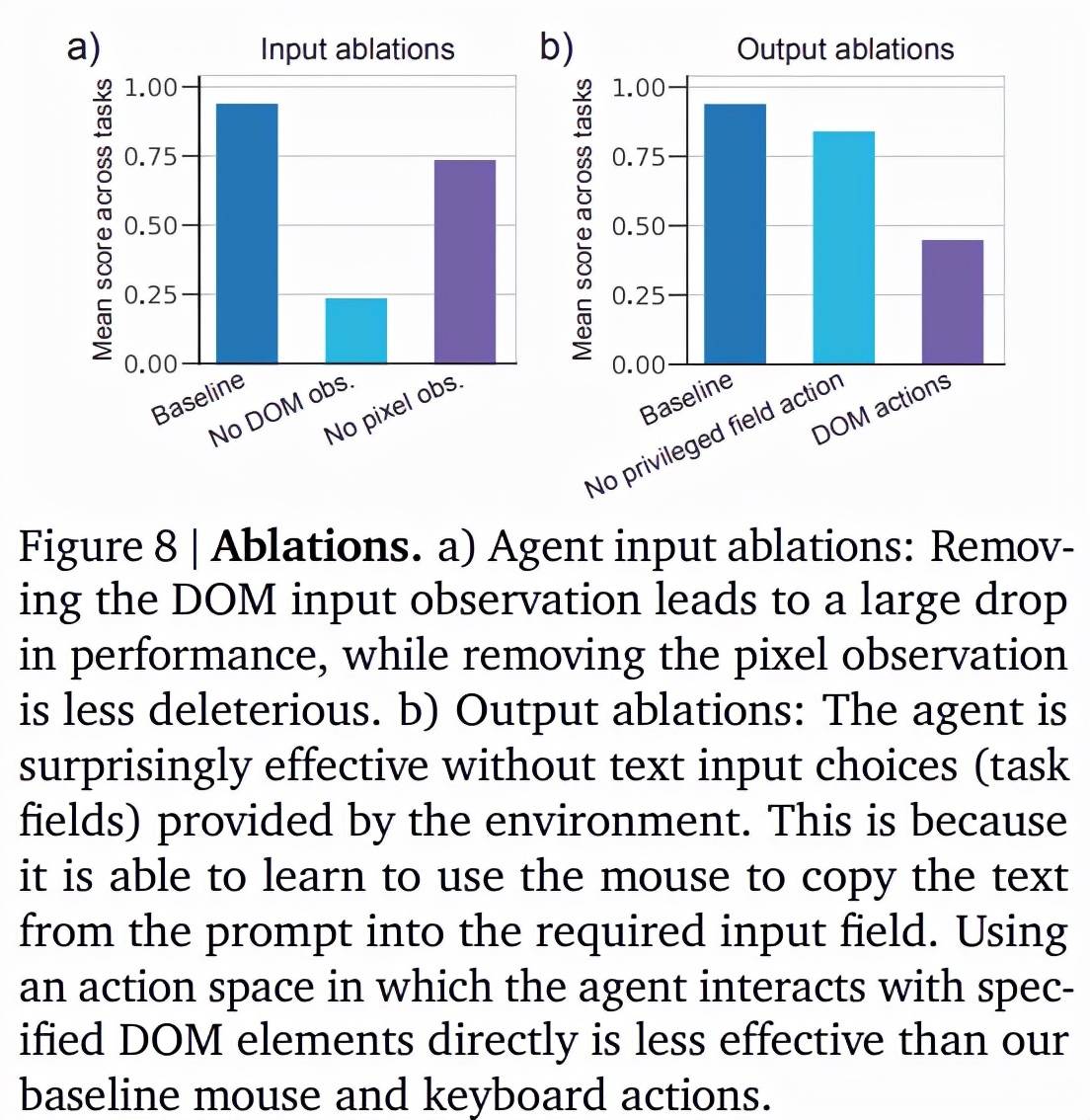
该智能体使用像素和 DOM 信息 , 并且可以配置为支持一系列不同的操作 。 该研究进行了消融实验以了解各种架构选择的重要性 。
该研究首先消融不同的智能体输入(图 8a) 。 当前的智能体配置强烈依赖 DOM 信息 , 如果删除此输入 , 性能会下降 75% 。 相反 , 视觉信息的输入对该智能体的影响不太显著 。
文章图片
如图 8b 所示 , 该研究移除了智能体使用环境给定的文本输入选项(任务字段)的能力 。 有趣的是 , 移除之后的智能体仍然能够解决涉及表单填写的任务 , 但它是通过 highlight 文本 , 并将其拖动到相关的文本框 , 以从人类轨迹中学会完成这个任务 。 值得注意的是 , 在原始 Selenium 版本的环境中智能体实现这种拖动操作并不简单 。
图 8b 还展示了一个消融实验结果 , 其中智能体使用与特定 DOM 元素交互的替代动作 。 这意味着智能体无法解决涉及单击画布内特定位置、拖动或 highlight 文本的任务 。
推荐阅读







- Aamrit|《蜘蛛侠:英雄无归》4K 蓝光版将于 4 月 12 日推出
- oppo|OPPO平板真机图首次出现 磁力键盘盖配件同步曝光
- 辽宁|辽宁:动作捕捉分析系统助力自由式滑雪运动训练效果提升
- 初二|初二数学下册:第十七章勾股定理同步训练
- 指令|别再怪你的iPhone耗电快了,原因我已经替你找到|闪修侠
- 蝙蝠侠|?iPhone 14 Pro 内存或提升/ QQ 音乐推出无缝播放功能 /《新蝙蝠侠》内地定档
- 选材|中国体育代表团表现出色,科技对训练有哪些强有力支撑?
- Europe|欧洲统一充电规格法案年底前通过 拟扩大至笔电、键盘等产品
- 方案|体育总局:科技冬奥为跨界跨项选材和科学化训练方案提供支持
- 橘子|还记得《家有儿女》里的键盘吗?现在成了帅气rapper?