平台|CMU携手NUS、复旦推出DataLab:打造文本领域数据分析处理Matlab
机器之心专栏
作者:刘鹏飞
以数据为中心 , 实现各种不同操作接口的标准化 , 使得用户在数据处理上只需要有一个入口 , 这就是 DataLab 期待扮演的角色 。

文章图片
建立以数据为中心的人工智能已经成为一个正在到来的趋势 。 一年多前 , 吴恩达开始发起的一项主题为「数据是人工智能的食物」运动 。 数月前 , 谷歌 AI 负责人 Jeff Dean 将数据的分析和管理列为 2021 年后机器学习的一大趋势 。 不久前 , AI 明星创业公司 Huggingface 宣布开始建立可交互的数据分析平台计划 。
近日 , CMU 联合 NUS、复旦、耶鲁等高校发布了 DataLab:面向文本数据的统一数据分析、处理、诊断和可视化平台 。

文章图片
- 论文链接:https://arxiv.org/pdf/2202.12875.pdf
- 平台访问:http://datalab.nlpedia.ai/
- SDK 地址:https://github.com/ExpressAI/DataLab
- 文档地址:https://expressai.github.io/DataLab/
「如果 Matlab 统一了『数值』计算和分析 , 那么谁来扮演『数据』处理和分析统一的角色?」
比起「数值」 , 数据的复杂性表现在它往往有着不同的模态 , 不同的结构 , 不同的处理操作 。 这些种种因素使得对数据存储以及操作标准化变得困难 , 更不用说建立统一的数据分析平台 。
所以即使现在做到比较好的 TensorFlow (TFDS)[1] 以及 HuggingFace (HFDS)[2] 的数据集平台 , 它们也只是完成了标准化数据载入这一件事情;即使集结了几十家高校上百名研究员完成的 Xl-Augmenter 平台 , 也只是尝试标注化数据增强;即使 Sorkel 联手 HuggingFace ,Stanford 等机构提出了 PromptSource [3] , 也只是尝试标准化数据提示 (Data Prompting) 这一个操作 。
这些不同数据操作平台的构建都非常有价值 , 然而平台之间切换的代价仍然存在 , 这里应该有个「平台的平台」的概念 , 以数据为中心 , 实现各种不同操作接口的标准化 , 使得用户以后在数据处理上只需要有一个入口 , 而这就是 DataLab 期待扮演的角色 。
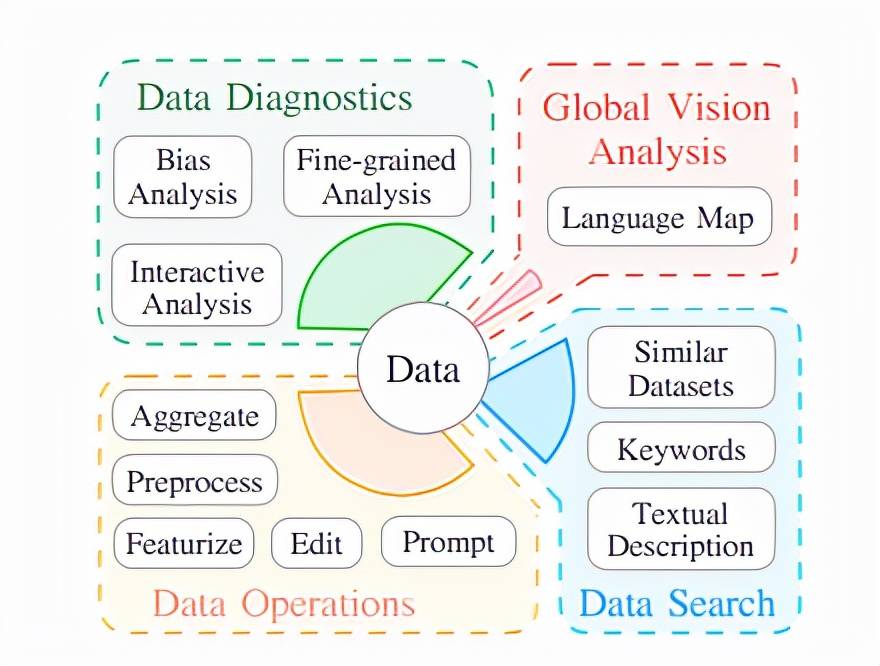
研究团队前段时间刚提出以 Prompt Engineering 为核心的 NLP 发展第四范式 。 那接下来让我们看看 DataLab 具体在做什么 , 以及对 Prompt Engineering 会不会也有些帮助?下图 1 为 DATALAB 功能概述 。
文章图片
DataLab 的特性如下:
- 覆盖广:DataLab 目前覆盖大部分 NLP 任务 , 包含 1700 多个数据集以及 3500 多个通过数据变形获得的数据集;
- 可理解性:DataLab 为许多数据集 (728 个数据集 , 139,570,057 个样本) 定制能够刻画数据集的特征(例如性别偏见)并进行计算 , 它可以帮助研究人员和开发人员在使用数据集之前更好地理解数据集 , 并帮助数据创建者提高数据质量 (例如消除 artifacts、偏见等);
- 统一性:DataLab 的主要目标之一是将不同的数据分析和处理操作统一到一个平台和 SDK 中;
- 可交互性:DataLab 使得数据查看、评估和处理更高效方便地完成 (实时搜索、对比、过滤、生成数据集诊断报告) 。 DataLab 也可以作为现成的标注平台 , 用户可以在这里贡献一些缺失但重要的可众包信息;
- 启发性:DataLab 对数据集的全局视角可以激发新的研究方向 , 比如通过跟踪数据集的全球发展状况 , 并确定未来的发展方向 。
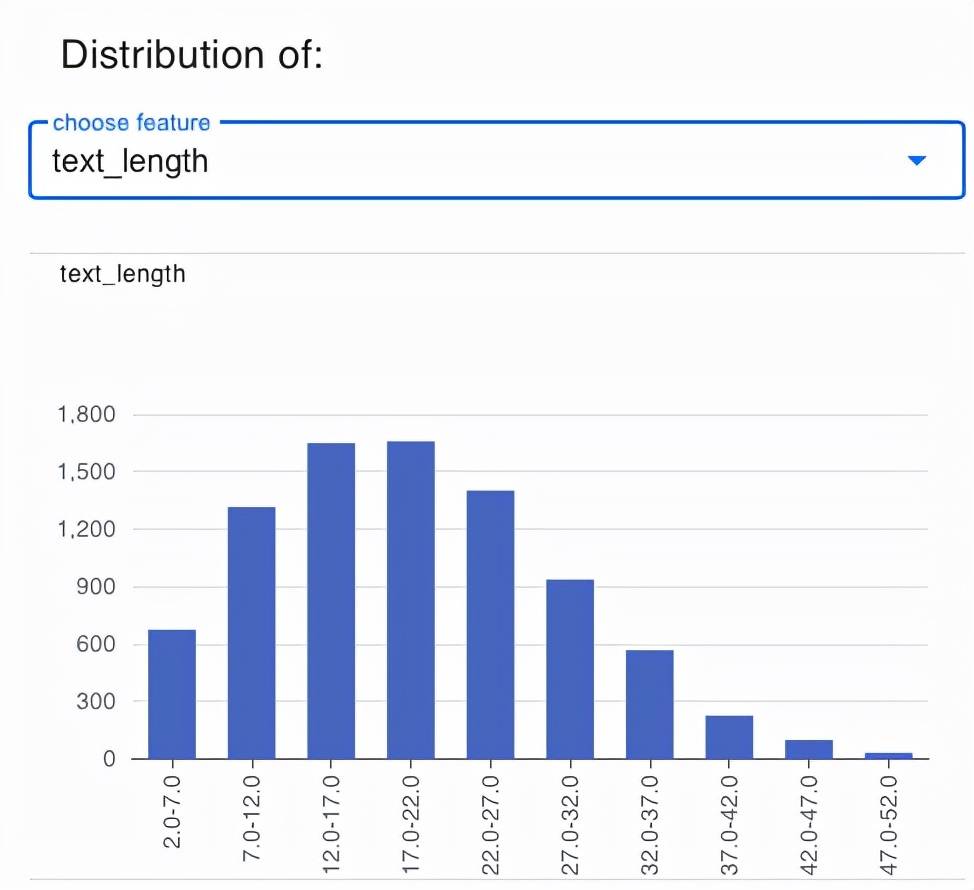
细粒度分析指的是 , 我们从多个不同的角度去认识一个数据集的特性 。 下图 2 为 SST 数据集(自然语言处理中关于情感分析的流行数据集)中的样本按照不同文本长度划分的分布图 。
文章图片
图 2:SST 数据集的样本按照不同文本长度划分的统计分布图
使用 DataLab , 用户可以选择任意支持的分析角度 , 实现一键化操作 。 DataLab 还支持数据集级别的整体分析 , 欢迎登录网站试玩 。
2. 数据集中存在的 「偏见」
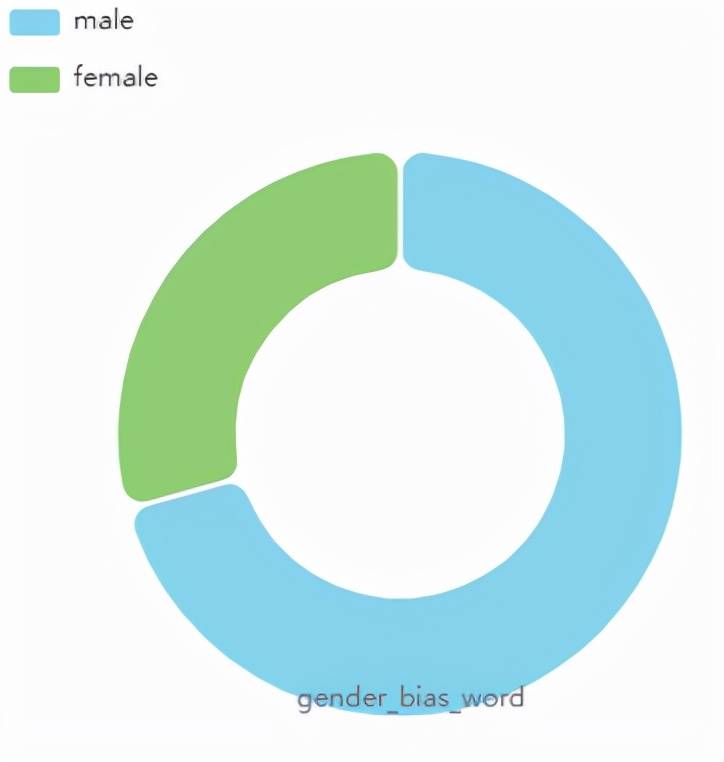
DataLab 可以帮助用户一键化地识别数据集中的「偏见」 。 目前支持三种分析:
- 性别偏见
- 仇恨言论
- artifacts
文章图片
图 3:SST2 数据集的性别偏见分布
再比如 , 利用 DataLab , 我们容易复现 Gururangan et al.[4] 在 SNLI 数据集(自然语言处理中关于两个句子关系推理流行的数据集)上发现的一个很有名的 artifact 现象:hypothesis 越长的句对 (premise-hypothesis) 通常是「neutral」关系 , 如下图 4 所示 。

文章图片
图 4:SNLI 数据集的 artifact 现象
3. Prompt 的分析
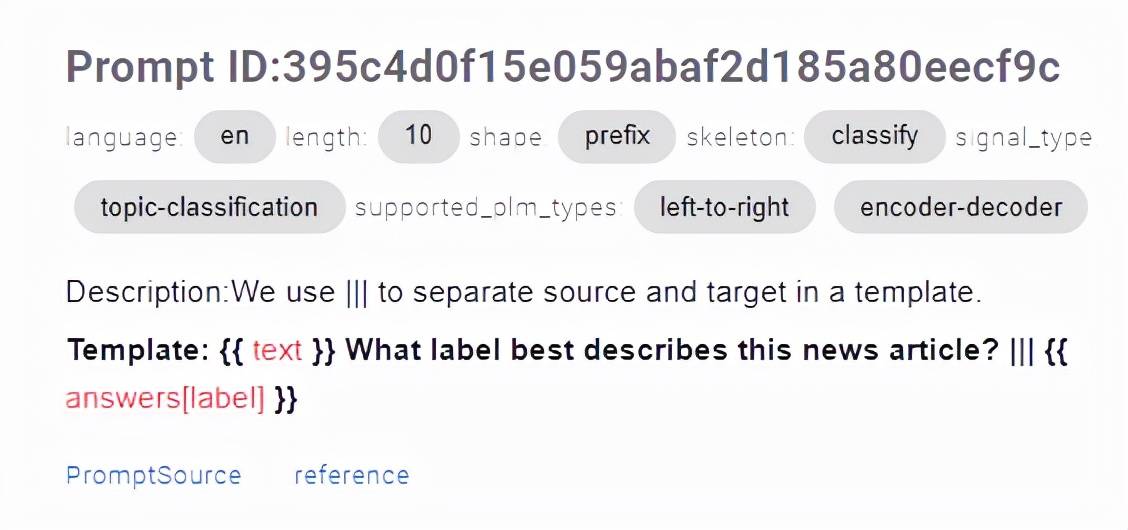
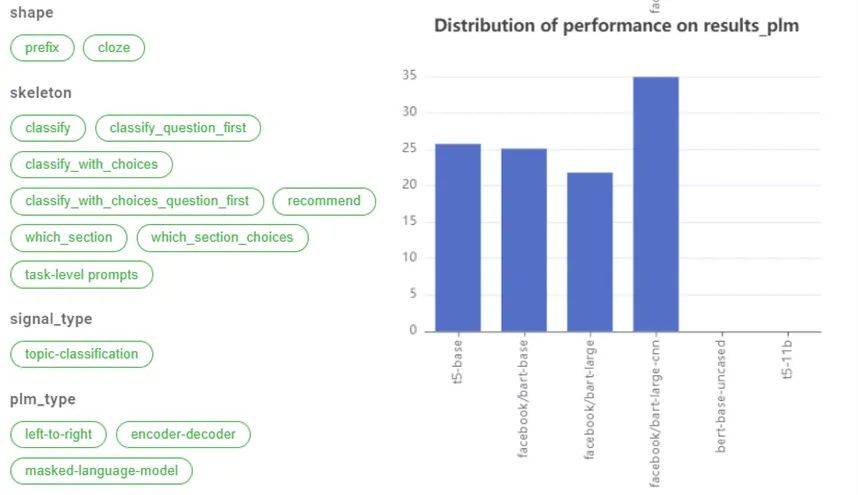
Prompt Learning 已经得到了相当多的关注 , 因为它能更好地利用预训练的语言模型中有利于许多 NLP 任务的知识 。 在实际应用中 , 什么是好的「Prompt」是一个具有挑战性的问题 。 下图 5 为DataLab 定义 Prompt 的一个例子 。
文章图片
(a)Prompt的定义
文章图片
(b)属性;(c)同一个数据集Prompts在不同PLM上的结果
DataLab 目前不但支持了 3000 多个已经设计好的 Prompt(包含 PromptSources 公布的 2000 多个) , 覆盖了上百个数据集 , 并且为 Prompt 设计了一个模式 , 使得每一个 Prompt 可以被许多不同的角度刻画 。 图 5 为 DataLab 定义的 Prompt 例子 , 包括 Prompt 的特征 (如长度、形状等)、属性 (如模板、答案等)、支持的预训练语言模型 , 以及它在不同的预训练语言模型的结果(图 5 下右) 。 该设计不仅可以帮助研究者更好地设计 Prompt , 还可以分析什么是好的 Prompt 。
【平台|CMU携手NUS、复旦推出DataLab:打造文本领域数据分析处理Matlab】4. 对比两个数据集差异
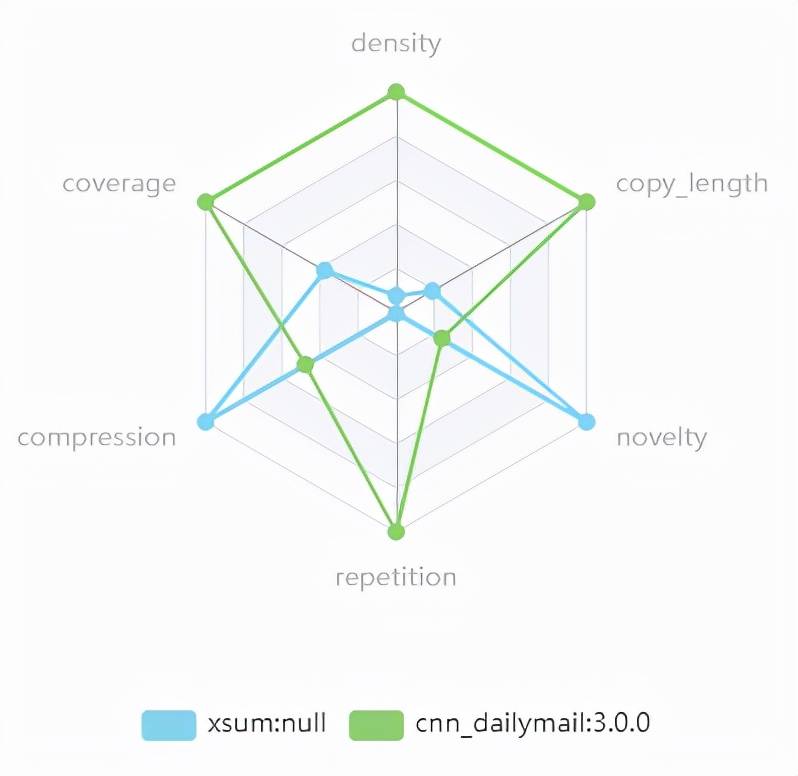
在做研究时 , 了解两个数据集之间的详细差异在很多方面都很重要 , 例如 , 它可以帮助我们解释模型训练在不同数据集上的不同行为 。 然而 , 分析它们的差异是一项繁琐的工作 , 通常需要设计不同的特征并且在不同的数据集上去计算 。 DataLab 将这一过程自动化 , 并帮助研究人员以非常方便的方式进行两两数据集分析 。
我们选取了两个文本摘要的数据集进行测试 ,然后会得到关于这两个数据集全方面的比较 , 如下雷达图 , 两个数据集各自特点可以清晰的被刻画 。
文章图片
文章图片
5. 数据集推荐
我们常常有个好的 idea , 却不清楚应该选用哪些合适的数据集 , 随着越来越多的数据集被提出 , 如何为给定的应用选择正确的数据集变得更加困难 。
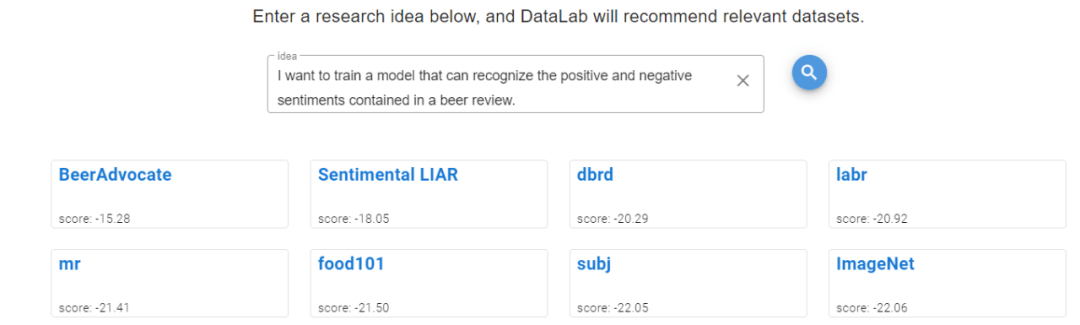
DataLab 尝试在这方面提供些帮助 。 具体说来 , 给定一个研究想法的描述 , DataLab 可以根据语义搜索出比较适配的数据集 , 并且给出排序得分 。 我们用一个例子测试对比了下 DataLab 和 Google Dataset Search:我们发现前者可以比较精准地找到一个符合描述的数据集 , 而 Google Dataset Search 直接失效 。
下图 6:DataLab 和 Google Dataset Search 对于同一个学术 idea 而推荐的数据集 。
文章图片
(a) DataLab 为给定的 idea 而推荐的数据集的结果页面 。

文章图片
(b)Google Dataset Search 为给定的 idea 的搜索结果(没有结果返回)
6. 全球视野分析
(1)语言地图
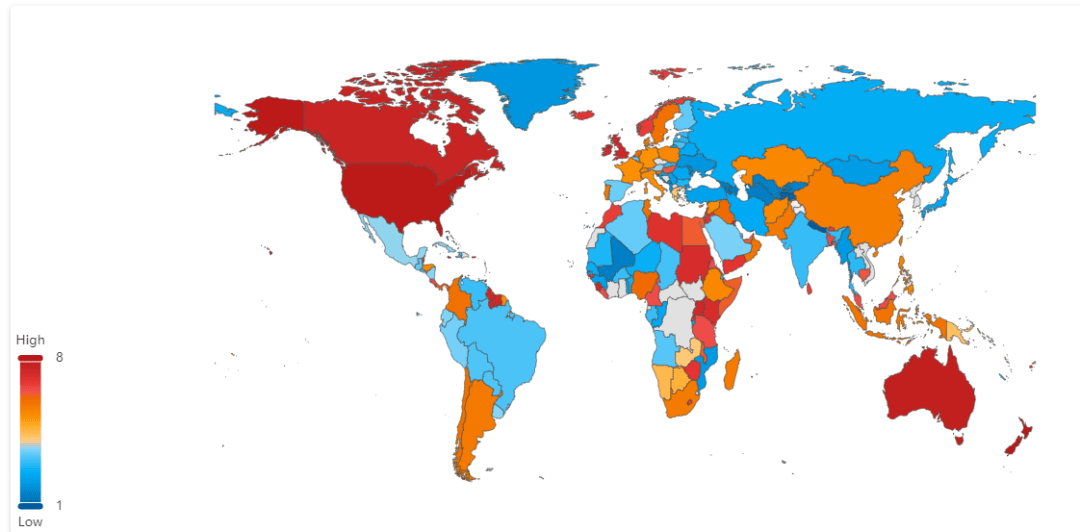
语言地图是用来从地理的角度分析哪些语言研究得多 , 哪些语言研究得少 , 从而告诉我们未来应该更关注构建哪些语言的数据集 。
如下图 7 , 颜色越红表示该国语言的数据集被研究得越多 。 我们可以很容易看出哪些国家语言的数据集很丰富(红色) , 相比而言 , 中文数据集是相对匮乏(橙色) 。
文章图片
图 7:语言地图
(2)NLP 模型谁家强?
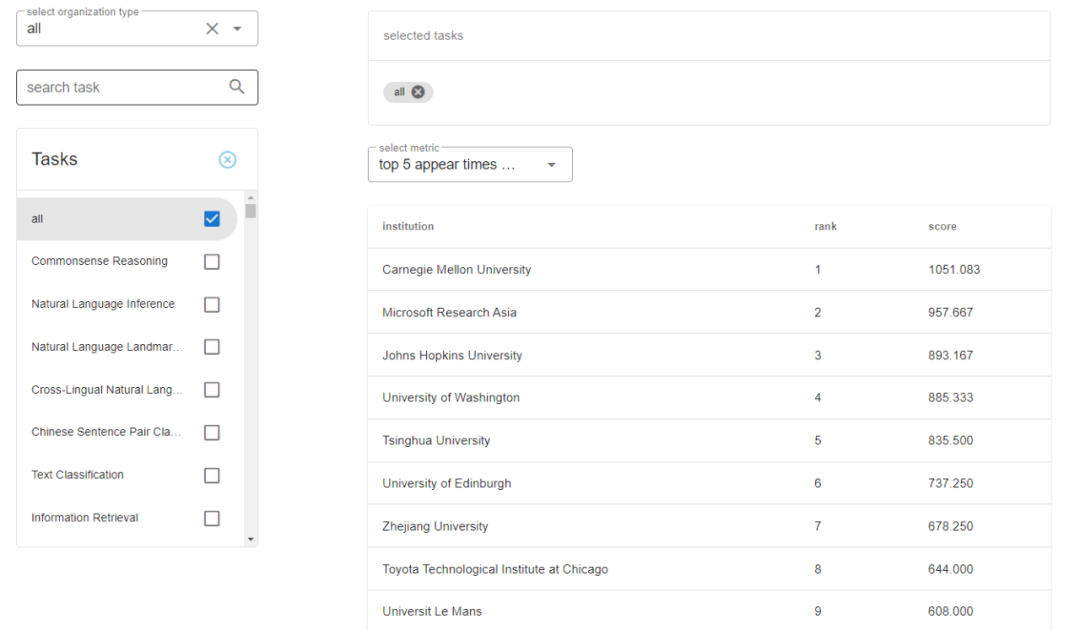
以数据集为单位 , 根据依赖其实现模型性能的排序 , 以及对应的实现机构 , 我们可以对不同机构设计的 NLP 系统的性能上进行排序 , 并且判断不同机构更擅长的 NLP 任务 , 如下图 8 所示 。
文章图片
图 8:全球机构在 NLP 系统性能上的排名
未来展望
我们希望平台的统一可以让集体智慧更容易发挥作用 。 未来 , DataLab 将继续向多个方向扩展:
- 探索并包含更多不同的数据类型 。 目前 , DataLab 仅包含文本类型的数据集 , 随着进一步优化 , DataLab 将逐渐支持其他领域不同类型的数据集 , 例如图像、多模态和声音等;
- 扩展更多的操作 。 目前 , DataLab 包含的操作有预处理、prompting、数据编辑等操作 。 随着引入不同任务的系统 , DataLab 有望探索系统组合等技术 , 实现高精度的自动数据标注 , 从而一定程度上为用户减少数据标注的成本;
- 促进该领域更好的进步 。 不同平台的统一能够让用户快速找到相关数据集(数据集推荐) , 定位合适的数据集(数据可理解性) , 快速进行数据的处理(预处理、prompting 等) , 从而一定程度上让学术研究更容易 。
[1] https://www.tensorflow.org/datasets
[2] Datasets: A Community Library for Natural Language Processing
[3] PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
[4] Annotation Artifacts in Natural Language Inference Data
推荐阅读







- 影像|OPPO Find X5 系列今日开售,包揽四大平台销量 & 销售额双冠军
- 平台|中公教育旗下“企易学堂”在线学习平台上线
- 速度|三星宣布 LPDDR5X DRAM 已应用于高通骁龙移动平台
- 产品|辐射京津冀 中关村(智造)中试服务平台项目昨日启动
- 旗舰|MediaTek发布天玑8000 系列轻旗舰5G移动平台
- 平台|我国量子计算云平台 上线两大国产量子编程软件
- Apple|开放网络倡导组织希望苹果解除iOS平台的第三方浏览器引擎限制
- 系列|广州灯光音响展,联诚发携手独角兽系列活动赋能娱乐夜经济!
- 数智|中公旗下“企易学堂”平台上线,三大模块赋能企业发展
- 平台|中公教育旗下“企易学堂”在线学习平台上线,向企业用户开放