状态|最清晰易懂的Raft算法讲解
作者介绍
戌米(笔名) , 金融级行业核心业务分布式数据库DBA , 负责大型金融级系统的国产化数据库改造工作 , 爱好分布式数据库底层技术 。
大家平时看分布式领域的一些资料 , 和了解原生分布式数据库TiDB、OceanBase时 , 常常会听到一个“共识算法”的概念 , 两大代表性的共识算法Paxos和Raft更是常常出现在数据库文档、技术论坛等地方 。 但一去了解 , 往往会发现论文原文或相关的翻译极其复杂 , 相当难以理解 。
可见共识算法的难度有多高 。 为了让大家能不费那么大劲地弄懂共识算法的基本理念 , 笔者把Raft算法论文《In Search of an understandable Consensus Algorithm》 , 用更通俗的语言组织了一下 , 只要你拿出10分钟来看完 , 相信你也会对共识算法有一个基本的理解 。
后文将先简单介绍一下共识算法的概念、作用 , 然后分模块开展Raft的讲解 。
一、共识算法概述
1、什么是共识算法?
要了解共识算法 , 首先我们要区分一致性问题(consistency)和共识问题(consensus) 。
consistency就是大家比较熟悉的事务ACID特性中的C , 指的是事务可以从一个满足完整性约束的状态转换到另一个完整性约束的状态 , 是事务要满足的一种特性 。
【状态|最清晰易懂的Raft算法讲解】而consensus指的是分布式系统中的节点如何就某些东西达成一致 , 可能是一个值、一系列动作 , 也可能是一个决定 。
很多人往往会把consensus和consistency搞混 , 从而把共识算法称作“一致性算法” 。 严格来讲 , 这种叫法也不能算错 , 但中文“一致性”的含义和使用实在太广 , 很容易引发歧义 。 所以我在本文中一并把以Paxos和Raft为代表的算法称作“共识算法” , 也提倡大家都使用这种称呼 。
2、共识算法可以用来做什么?
我们知道在一个分布式系统中 , 通常会使用增加副本的方式来保证系统的高可用 。 但容易忽略的一点是 , 怎样才能确保增加的副本可以发挥出作用?或者说 , 主备切换时 , 选择哪台机器来成为主?(备机如何判断主机宕了?每台备机都想成为主机怎么办?每台备机都不想成为主机怎么办?)
一个比较直接的思路是 , 由客户端或另一类节点维持所有数据节点的信息 , 当发现主不可用时 , 它们从清单中选择另一台机器做主 。
但这就出现了另一个问题 , 这类选主的节点的高可用 , 怎么保证?
显然 , 如果对管理数据节点的节点再设管理节点 , 那么这个问题还会嵌套下去 , 没有得到解决 。 要根本上解决这个问题 , 我们就需要让节点可以在不依赖外界因素的情况下自动完成主节点的选举 , 这就是共识算法的作用 。
目前主要有两种共识算法:Paxos和Raft 。
在具体介绍两种共识算法之前 , 我们先了解一下复制状态机(Replicated State Machine)的概念 。
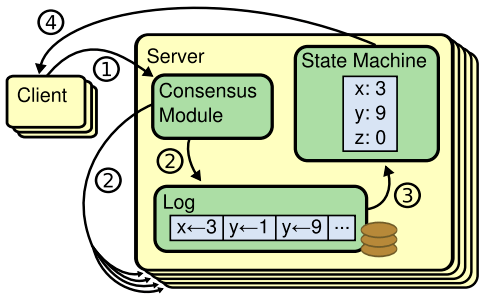
文章图片
复制状态机的核心理念是:相同的初始状态+相同的输入=相同的结束状态 。
简单一点描述就是:多个节点上 , 从相同的初始状态开始 , 执行相同的一串命令 , 产生相同的最终状态 。
可以说 , 我们使用共识算法 , 就是为了实现复制状态机 。 一个分布式场景下的各节点间 , 就是通过共识算法来保证命令序列的一致 , 从而始终保持它们的状态一致 , 从而实现高可用的 。 (投票选主是一种特殊的命令)
二、Raft算法
相比于Paxos , Raft最大的特性就是易于理解(Understandable) 。 为了达到这个目标 , Raft主要做了两方面的事情:
- 问题分解:把共识算法分为三个子问题 , 分别是领导者选举(leader election)、日志复制(log replication)、安全性(safety) 。
- 状态简化:对算法做出一些限制 , 减少状态数量和可能产生的变动 。
我们先来讨论状态简化这一点 , 在任何时刻 , 每一个服务器节点都处于leader , follower或candidate这三个状态之一 。
如果你了解过Paxos的话 , 就会知道 , 相比于Paxos , Raft这点极大简化了算法的实现 , 因为Raft只需考虑状态的切换 , 而不用像Paxos那样考虑状态之间的共存和互相影响 。
那么Raft具体是怎么做到这一点的呢?Raft把时间分割成任意长度的任期(term) , 任期用连续的整数标记 。
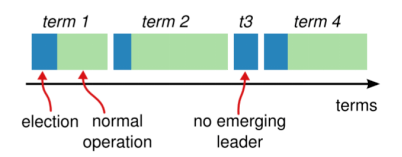
文章图片
如上图 , 每一段任期从一次选举开始 。 在某些情况下 , 一次选举无法选出leader(比如两个节点收到了相同的票数) , 在这种情况下 , 这一任期会以没有leader结束;一个新的任期(包含一次新的选举)会很快重新开始 。 Raft保证在任意一个任期内 , 最多只有一个leader 。
Raft算法中服务器节点之间使用RPC进行通信 , 并且Raft中只有两种主要的RPC:
- RequestVote RPC(请求投票):由candidate在选举期间发起 。
- AppendEntries RPC(追加条目):由leader发起 , 用来复制日志和提供一种心跳机制 。
接下来 , 我们具体讨论领导者选举、日志复制和安全性三个子问题 。
2、领导者选举、日志复制、安全性
1)领导者选举
首先是领导者选举(leader election) 。 Raft内部有一种心跳机制 , 如果存在leader , 那么它就会周期性地向所有follower发送心跳 , 来维持自己的地位 。 如果follower一段时间没有收到心跳 , 那么他就会认为系统中没有可用的leader了 , 然后开始进行选举 。
开始一个选举过程后 , follower先增加自己的当前任期号 , 并转换到candidate状态 。 然后投票给自己 , 并且并行地向集群中的其他服务器节点发送投票请求 。 最终会有三种结果:
- 它获得超过半数选票赢得了选举 -> 成为主并开始发送心跳 。
- 其他节点赢得了选举 -> 收到新leader的心跳后 , 如果新leader的任期号不小于自己当前的任期号 , 那么就从candidate回到follower状态 。
- 一段时间之后没有任何获胜者 -> 每个candidate都在一个自己的随机选举超时时间后增加任期号开始新一轮投票 。
新主选出来后 , 就进入日志复制(log replication)阶段了 。
Leader被选举出来后 , 开始为客户端请求提供服务(你可能会问 , 客户端怎么知道新leader是哪个节点呢?有一个很简单的方法 , 客户端随机发送指令到一个节点 , 如果这个节点不是主 , 那么它就返回主的信息给客户端) 。 Leader接收到客户端的指令后 , 会把指令作为一个新的条目追加到日志中去 , 然后并行发送给follower , 让它们复制该条目 。 当该条目被超过半数的follower复制后 , leader就可以在本地执行该指令并把结果返回客户端 。
在此过程中 , leader或follower随时都有崩溃或缓慢的可能性 , Raft必须要在有宕机的情况下继续支持日志复制 , 并且保证每个副本日志顺序的一致(以保证复制状态机的实现):
- 如果有follower因为某些原因没有给leader响应 , 那么leader会不断地重发追加条目请求 , 哪怕leader已经回复了客户端 。
- 如果有follower崩溃后恢复 , 这时Raft追加条目的一致性检查生效 , 保证follower能按顺序恢复崩溃后的缺失的日志 。 Raft的一致性检查:leader在每一个发往follower的追加条目RPC中 , 会放入前一个日志条目的搜索引位置和任期号 , 如果follower在它的日志中找不到前一个日志 , 那么它就会拒绝此日志 , leader收到follower的拒绝后 , 会发送前一个日志条目 , 从而逐渐向前定位到follower第一个缺失的日志 。
- 如果leader崩溃 , 那么崩溃的leader可能已经复制了日志到部分follower但还没有提交 , 而被选出的新leader又可能不具备这些日志(因为没有提交 , 所以不违背下面的安全性规则) , 这样就有部分follower中的日志和新leader的日志不相同 。 Raft在这种情况下 , leader通过强制follower复制它的日志来解决不一致的问题 , 这意味着follower中跟leader冲突的日志条目会被新leader的日志条目覆盖(因为没有提交 , 所以不违背外部一致性) 。
最后 , 我们讨论第三个子问题安全性(safety) 。
领导者选举和日志复制两个子问题实际上已经涵盖了共识算法的全程 , 但目前所述的这两点还不能保证每一个状态机会按照相同的顺序执行相同的命令 。 (即怎样防范“后发先至”的可能性)
例如 , 如果一个follower落后了leader若干条日志(但没有漏一整个任期) , 那么下次选举中 , 按照领导者选举里的规则 , 它依旧有可能当选leader 。 它在当选新leader后就永远也无法补上之前缺失的那部分日志 , 从而造成状态机之间的不一致 。
所以需要对领导者选举增加一个限制 , 保证被选出来的leader一定包含了之前各任期的所有被提交的日志条目 。
Raft利用了一种近似于数学归纳的方法来保证这一点:follower只有判断candidate的日志条目“新”于自己 , 才会投票给这个candidate;因为每条已提交的日志都至少同步给了过半节点 , 所以只要一个candidate收集到了过半的选票 , 那么它就一定具备了所有已提交的日志 。
三、总结
总结一下 , Raft通过状态简化和三个子问题的分解 , 规划出了一条清晰可行且易于理解的实现方法 , 大大降低了分布式基础组件使用共识算法的难度 。
Raft论文中还对43个大学生做了个实验 , 结果显示 , 其中有33个人学习Raft的成绩好于学习Paxos的成绩 。
实用性角度看 , 从Raft算法发布之后 , 也就是2014年之后 , 在Paxos和Raft之间选择Raft的软件就越来越多 。 开发者们表示:从前我没得选 , 现在我只想选Raft 。
可见 , 算法的易理解性还是很重要滴 , 再好的东西 , 也要别人能理解并使用啊!
更多干货
四期精选“数据库”主题直播回看:
数据库前沿技术实践与应用趋势探讨:http://z-mz.cn/4CjCp
金融业数据库转型与国产化改造:http://z-mz.cn/3QOjX
主流关系型分布式数据库选型与设计实战:http://z-mz.cn/3GOHl
金融级数据库架构设计与运维实践:http://z-mz.cn/1vTkl
关注公众号dbaplus社群回复【220318】 , 可获取配套PPT哦~
最新一期直播【云原生运维转型的多维度探索】将于4月9日开播 , 通过下方链接进入直播间 , 点击开播提醒 , 精彩内容不错过!
http://z-mz.cn/51yK9
dbaplus社群欢迎广大技术人员投稿 , 投稿邮箱:editor@dbaplus.cn
关注公众号【dbaplus社群】 , 获取更多原创技术文章和精选工具下载
推荐阅读







- 机体|科学家最新研究发现:活得“凉爽”寿命变长
- AMD|最强游戏CPU:AMD锐龙7 5800X3D跑分曝光 比锐龙7 5800X快9%
- 最新消息|客机坠毁详情公布 尚未发现幸存者 东航:飞机起飞前符合适航要求
- 支气管|磁性机器人可进入最小支气管采样
- 企业|产业互通,蜘点再创新绩
- 最新消息|科技部拟规定:不得向境外提供我国人类遗传资源
- 警告!|台湾地区发生连续地震:最大6.6级 台积电等半导体厂受影响
- 最新消息|贝壳组织优化,超20名中高层相继离职
- 最新消息|年上课不用钱的万门大学 一口气把学员全收割了
- 触手|直径仅2毫米磁性机器人可进入最小支气管采样