自注意力中的不同的掩码介绍以及他们是如何工作的?

文章图片

文章图片

文章图片

文章图片
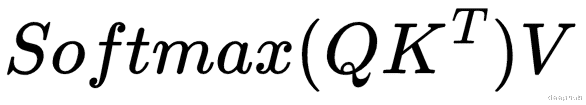
文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片

文章图片
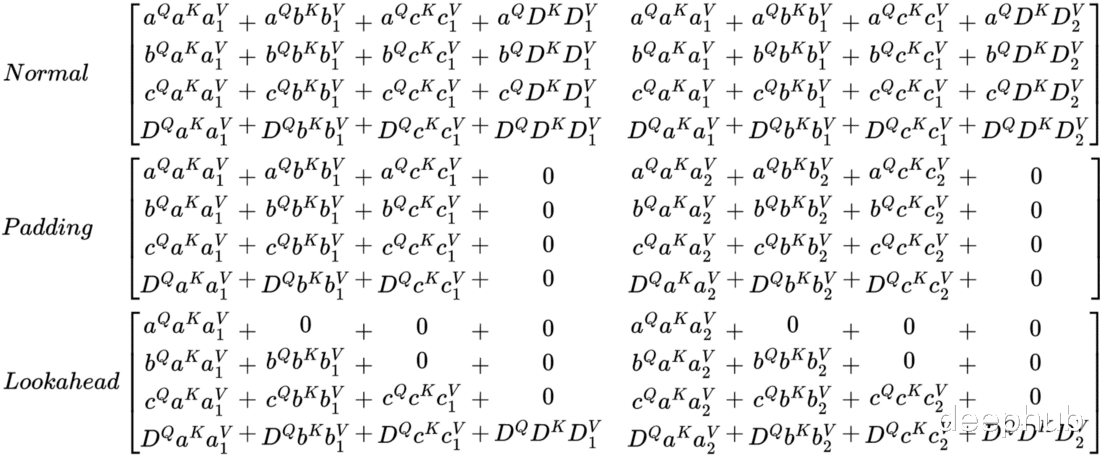
文章图片

文章图片
在研究自注意力时 , 有很多的名词需要我们着重的关注 , 比如填充掩码 , 前瞻掩码等等 , 但网上没有太多注意力掩码的教程和它是如何工作的信息 , 另外还有以下的细节需要详细的解释:
- 为什么要对多个层应用注意力掩码?、
- 为什么不沿键和查询应用注意力掩码?
- 键、查询和值权重是否混淆了原始矩阵的序列顺序?
问题定义让我们从一个有 4 个单词的矩阵 X 开始 。当这些词被转换成它们的令牌嵌入 , 每个令牌的嵌入大小将是 3 个值 。例如下面是我们的句子:
“a b c D”
现在让我们把这些词变成令牌 。
向量a b c D各有3个分量 , 这个序列本质上是由4个令牌符号组成的 。 每个令牌是3个值的向量 。 我们把这些符号变成一个矩阵X 。
X是由向量a、b、c和D组成的4 × 3矩阵这是我们想要用自注意力来转化的矩阵 。
注意力计算前的准备为了准备注意力 , 我们必须首先使用加权矩阵生成键K、查询Q和值V 。 对于这个句子 , 我们想把它转换成一个4 * 2矩阵 。 所以每个权重矩阵的形状都是3或2 。 例如下面是Q的权值矩阵QW 。
将X矩阵转换为Q(查询)矩阵的权重 , 下面是利用QW矩阵可以得到查询矩阵Q 。
计算的过程如下
现在我们有了 Q 的表示 。 注意力结果矩阵中的每个向量不是所有其他令牌的线性组合 。而每个向量都是其自身和一些权重的线性组合 。第一个向量只是 a 的线性组合 。第二个只是b的线性组合 。这种转换不会弄乱矩阵内的序列顺序 。a 仍然在矩阵的顶部 , 而 D 仍然在矩阵的底部 。对于未来的操作 , 我将使用最右边的矩阵来表示 Q, 这样轻松地可视化 a、b、c 和 D 的向量 , 并且也可以说明这些向量是没有被转换为彼此相结合的某种组合 。
对于K和V也是类似的 , 所以我们得到了从X矩阵和相应矩阵权重计算的K , Q , V
现在我们来计算这个序列的注意力 。
QK?矩阵最原始的自注意力是用下面的公式来定义的
为了更容易地可视化发生了什么 , 我将删除d?常数 。 《The Attention is All You Need 》的作者声明 , 使用标量d?是因为“我们怀疑对于d?的大值 , 点积的量级变大 , 将softmax函数推到具有非常小的梯度的区域“ 。 所以d?只是一个帮助数值量级转换的标量 , 所以在本文中不用不关心它 , 那么可以使用下面的公式来代替 , 也就是把d?删除了
推荐阅读







- 盘点NBA自毁基业的六笔交易,湖人一蹶不振,76人目光短浅
- 量子力学:人不会死去,人本身就不存在,人来自个人定义
- 来自旅行者1号和2号的数据表明,在太阳系边界处存在未知涟漪结构
- 拜仁最悔恨的一笔交易:赫内斯的自大,促成拜仁最优秀的中场,成皇马四冠王功臣
- 高手在民间!云南一小伙捡松果自制桌子,创意满满,成品惊艳众人
- 案例:孕妇追求自我不穿胸罩上班,遭无业青年惦记拖入果园酿悲剧
- “人类从鱼进化而来”被证实后,我们吃鱼,是在吃自己的祖先?
- 丈母娘要48万彩礼遭拒,女儿多年未嫁后降彩礼求娶,女婿:自私活该!
- “黑洞”是什么?“黑洞”能吸入大气层中的气体吗?
- 美女房东强拉我去相亲,不料相亲对象是她自己,她并因此赖上了我