情感|舆情情感是如何被测量的?
通过机器快捷判定舆情事件的初步情况 , 能够为人的综合判断和设计应对方案提供一个好的路线图 , 以便于舆情苗头出现之际快速发现信号、舆情发酵过程中检验应对有效性 , 以及在后期科学评判处置效果 。
情感分析又被称为情感倾向性分析或意见挖掘 , 是从用户意见中提取信息的过程 。 文本情感分析则致力于将单词、句子、段落和篇章映射到一组相对应的情感类别上 , 继而得到一个可用于划分情感状态的心理学模型 。
文本情感分析是舆情事件研判过程中的关键一步 。 当我们基于机器现成的舆情事件情感占比结果 , 研判舆情态势、针对性的采取相应策略时 , 也需要停下来想一想 , 舆情情感被测量的背后机理是什么?
总体而言 , 文本情感分析通常要经过以下几个过程: 一是文本清洗 。 筛除与文本无关的噪声数据 。二是对文本进行分词处理 。 目的是将文本分为单独的词 , 然后转换为词向量 , 也就是将自然语言转化为机器语言 , 随即使用模型处理数据 。三是获取特征 。 从这一步开始有四种不同的方法 , 分别是基于情感词典与规则的方法、传统机器学习方法、深度学习方法、多策略混合方法 。四是使用模型分类 。 利用四种方法特有的模型对词、句、篇章蕴含的情感进行分析和预测其类别 。五是根据预测结果 , 把文本分到相应的类别中 。
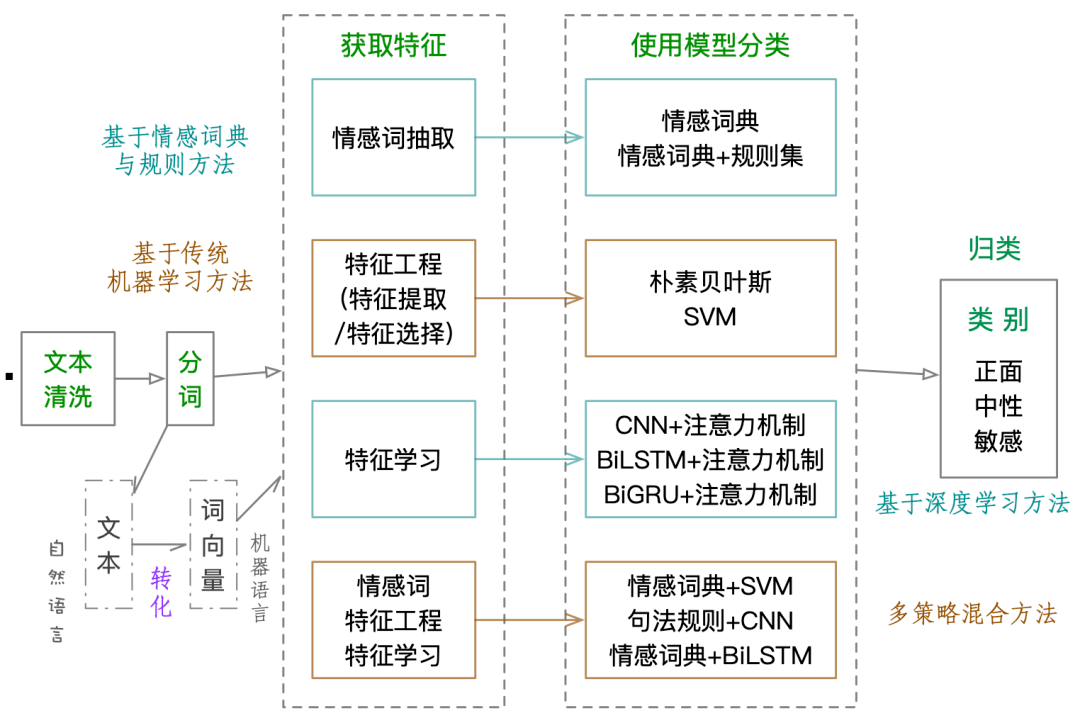
文章图片
图:文本情感分析通用过程及使用方法
Step 01
文本清洗
在文本清洗阶段 , 首先对文本数据进行去停用词、去除换行符等清洗工作 , 统一英文数据、集中英文字母的大小写 , 并将数据序列化 。 这个过程由专门的成熟工具完成 。
Step 02
分词
由于计算机不能够直接理解人类的自然语言 , 对自然语言进行建模是让计算机能够运用自然语言进行计算的第一步 。 在自然语言处理任务中 , 首先需要考虑词如何在计算机中表示 。 研究自然语言的时候 , 都是需要把大量文本划分为最小知识单元 , 也就是把文章、段落、句子都划分为词 。
分词算法的原理是基于词典进行扫描 , 生成有向无环图;然后是根据词频进行最大化的切分与组合;最后使用基于汉字成词能力的HMM模型提取新词(该模型主要使用了Viterbi算法)完成对中文文本的词法分析 。 精确模式、全模式和搜索引擎模式是三种分词模式 。 精确模式就是将词最准确的划分出来 , 没有多余的词 , 这种分词方法最适用于对文本进行一些分析操作 。 分词原理及过程见下图 。
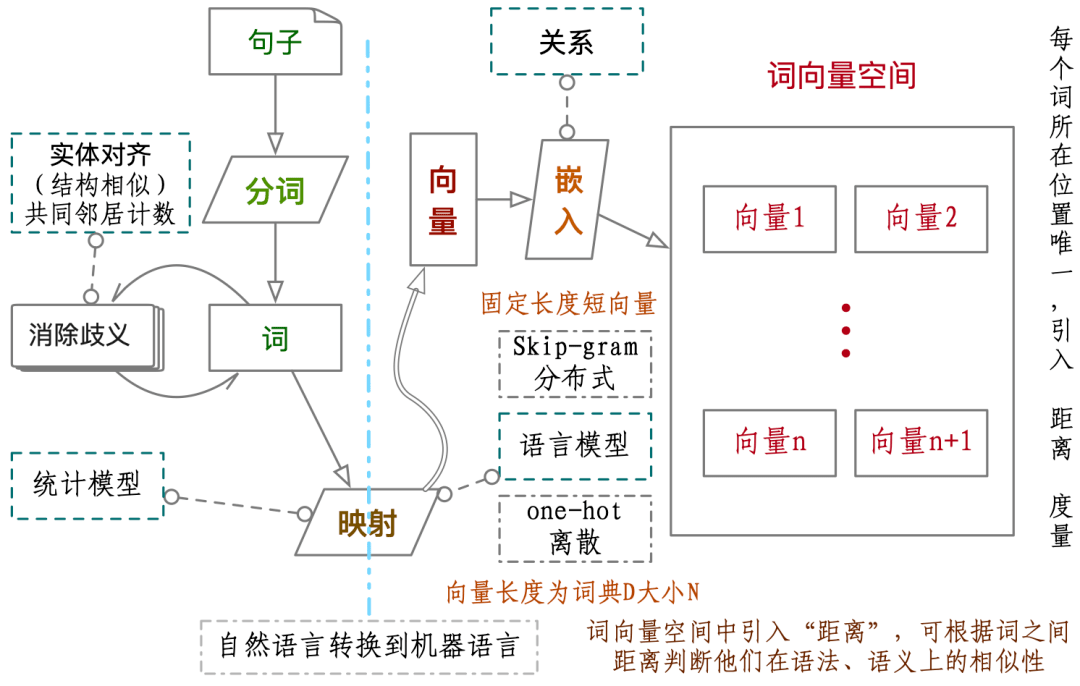
推荐阅读







- 中新经纬|反向带货还是饥饿营销,瑞幸李国庆互怼伤害了谁?
- 专访|专访犀思云创始人张雄国:NaaS服务的核心是成就客户
- 什么|什么是超高效过滤器?
- 苹果|关机后你的手机还能被定位,是真的咩?
- 财联社|对话荣耀CEO赵明:折叠屏会是国产手机弯道超车苹果的契机
- 视点·观察|肯德基盲盒二手价暴涨8倍 是否在搞“饥饿营销”?
- IT|永远改变了F1的六起悲剧
- 寿命|iphone手机是否能充电过夜?几个前提应该要知道
- 来源|天津战“疫”:逆境中的光芒
- 病例|奥密克戎再研判:毒性是否减弱?疫苗还有效吗?