机器之心原创
机器之心编辑部
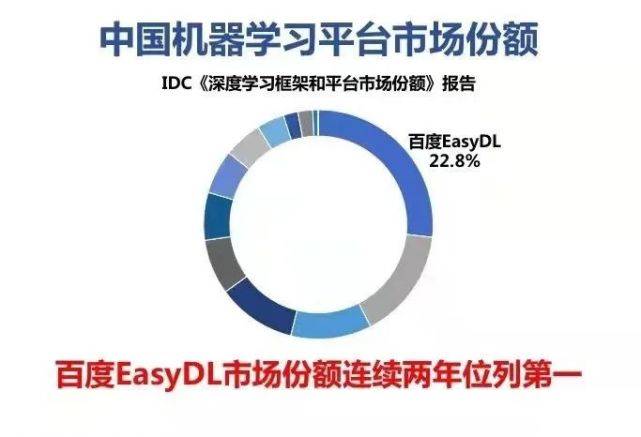
在 2020 年的中国机器学习平台市场 , 百度的 EasyDL 又拿了第一 。
近日 , 全球权威咨询机构 IDC(国际数据公司)发布了中国《深度学习框架和平台市场份额》报告 。 调研数据显示 , 截至 2020 年 12 月 , 百度的「零门槛 AI 开发平台」EasyDL 以 22.80% 的市场份额位列机器学习平台市场份额第一 , 并连续两年保持市场第一 。
文章图片
数据来源:IDC《深度学习框架和平台市场份额》2020.12 。
报告指出 , 在机器学习平台方面 , 百度 EasyDL 的用户认知度最高 , 也是受访者使用频率最高的平台 。
据统计 , 自 2017 年推出以来 , 百度 EasyDL 已经累计服务了70 多万的用户 , 覆盖 20 多个行业 , 得到了大量企业与个人开发者的广泛认可与应用 。
其实 , 随着 AI 技术落地的不断深入 , 市场上已经涌现出多款致力于降低 AI 应用门槛的训练和服务平台 , 为什么 EasyDL 如此受欢迎?哪些人、哪些行业在用?平台的背后有何支撑?今天 , 我们就来探讨一下这些问题 。
为什么 EasyDL 如此受欢迎?
要解释 EasyDL 受欢迎的原因 , 我们就不得不提两个理念 。
第一个理念是:让开发 AI 服务「像使用家电一样简单」 。
在 EasyDL 诞生之前 , 百度大脑已经通过百度 AI 开放平台开放了多项标准能力 , 如人脸识别、文字识别、语音技术等 , 但随着 AI 落地的深入 , 不少企业发现 , 在越来越多的实际应用场景中 , 需要结合场景数据进行模型的定制 。 有研究显示 , 这样的定制化需求占比高达 86% 。
但与之相矛盾的是 , 大部分中小企业并不具备专业的算法开发能力 , 开发定制 AI 模型对于他们来说太难了 。
以一家制作箱包的传统企业为例 。 在箱包出厂之前 , 他们需要借助 X 光扫描箱包内是否含有针、剪刀等异物 , 然后靠人眼来检查扫描图像 。 但问题在于 , 有些「针」可能非常小 , 不易被肉眼察觉 。 因此 , 这家企业就在想:能否让 AI 去「看」这些 X 光图像 。

文章图片
这就涉及到了定制 AI 模型的问题 , 因为通用的标准模型在识别「针」、「剪刀」等特定物体时可能达不到企业想要的准确率 。 如果你懂 AI , 这个问题可能非常容易解决 。 可问题在于 , 这是一家制造类企业 , 真正懂 AI、拥有丰富模型训练经验的人才可能寥寥无几 。
当然 , 这还只是其中的一道坎儿 , 其他坎儿还包括:数据如何采集?采集到之后还要花多少钱标注?模型训练好之后要怎么部署?部署之后效果不理想是不是还得花很长时间迭代?完成这些工作是不是需要组建一支技术团队?如果这些问题得不到妥善解决 , 企业就会面临项目成本高、周期长、前期对项目效果无法准确预期等问题 。
针对这些问题 , EasyDL 提供了「一站式 AI 服务」 , 把数据、训练和部署的活儿都揽了过来 , 还实现了全流程自动化 , 用户只需要根据平台的提示进行操作即可 , 不懂算法、不会写代码都不是问题 。
这就像使用家电一样:你不必了解家电的内部构造和电路原理 , 也能享受家电带来的便捷;同理 , 你不懂 AI , 也能借助 EasyDL 享受到 AI 浪潮带来的红利 。
第二个理念是:「像高级 AI 工程师一样专业」去训练高质量 AI 模型 。
我们生活中有很多「傻瓜式」的产品 。 这种产品很多都有个特点:上手容易 , 但效果一般 。 因此 , 如何在降低使用难度的同时保证其专业性成为这类产品开发的难点 。 也就是说 , 机器可以包揽很多操作 , 帮助用户实现「傻瓜式」操作 , 但机器本身不能傻 , 还要非常聪明 。
越是追求使用简单 , 它的内在就会越复杂 , EasyDL 也是一样 。 为了让 EasyDL 像高级 AI 工程师一样专业 , 百度从模型、数据、部署等多个方面进行了打磨 。
文章图片
在模型方面 , GPT-3 等超大模型已经证明了什么是「钞能力」 。 在现有的理论水平下 , 利用「海量数据预训练 + 迁移学习」的范式提升模型性能已经成了一股风潮 , 但这股风潮对于中小企业、研究机构和个人研究者来说都很不友好 , 毕竟动辄成百、上千万美元的训练成本没有多少公司能够承担 。 而且 , 这些超大规模预训练模型很多都是不开源的 , 即使开源也可能存在各种局限 。
在这方面 , EasyDL 有一个强大的「底座」——百度开源深度学习平台飞桨 。 借助飞桨的强大能力 , EasyDL 打包了各种任务的大规模预训练模型 。 这里说的「大规模」有多大呢?带来的提升有多少呢?我们来看几组数据:
图像分类的预训练模型用海量互联网数据进行大规模训练(包括 10 万 + 的物体类别 , 6500 万的超大规模图像数量) , 适用于各类图像分类场景 , 平均精度可提升 3.24%-7.73%;
物体检测的预训练模型用 800 + 类别 , 170 万张图片以及 1000 万 + 物体框的数据集进行大规模训练 , 适用于各类物体检测应用场景 , 平均精度可提升 1.78%-4.53%;
自然语言处理的文心 ERNIE 2.0 模型学习知识超 10 亿条 , 包含 1500 万篇百科语料和词语、实体知识 , 3 亿篇文章的因果结构关系 , 700 万轮人类对话 , 以及2000 万的语言逻辑关系等知识 , 适用于各类 NLP 应用场景 , 在中英文的 16 个典型 NLP 任务上超越了业界最好模型;目前 , 最新版 ERNIE 模型已经累计学习 50 亿条知识;
……
这些数据说明 , EasyDL 在很多方向都具备强大的通用知识 , 就像一个修炼了多年内功的武林高手 。 有了这些通用知识 , 模型只需要学习少量带有用户领域专业知识的数据就可以「触类旁通」 , 去解决特定场景下的任务 。 目前 , EasyDL 已经支持图像、语音、视频、文本、OCR、结构化数据、商品检测等多种模型类型 。
为了提升模型性能 , EasyDL 还内置了 AutoDL/ML 自动化建模机制 , 包含自动数据增强、自动超参搜索、自动网络架构搜索等技术 , 可以降低零算法基础用户的使用门槛 , 提升专业开发者的建模、调参效率 。
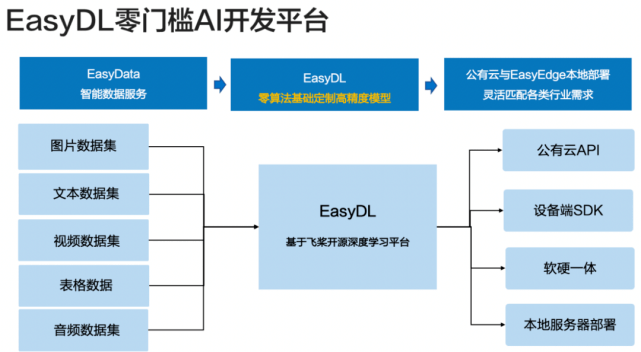
当然 , 数据的处理也是可以充分智能化的 , 这就要提到 EasyDL 的智能数据服务了 。
为了实现数据采集、清洗、标注的一站式服务 , EasyDL 建设了 EasyData 智能数据服务平台 。
在数据采集方面 , 定制模型所需要的数据往往不能从网上直接下载 , 而是需要建设符合实际场景的样本数据集 , 对此 , EasyData 提供了软硬一体、端云协同的自动数据采集方案 , 支持接入摄像头采集图片、云服务数据回流两种数据采集方式 。
在数据标注方面 , EasyData 提供了图片、文本、音频、视频四种数据格式的 11 种数据标注模板 。 但鉴于用户的数据可能比较多 , 标起来费时费力 , EasyDL 开发出了智能标注方案 , 还支持多人标注 。 在物体检测、图像分割、文本分类三类任务场景中 , 通过百度自研的 Hard Sample 主动学习挖掘算法 , 进行针对性适配 , 在同样的模型效果指标下 , 可减少 70% 的数据标注量 。
在数据清洗方面 , EasyData 创新性地开放了图片数据清洗的完整解决方案 , 支持相似度去重、去模糊、裁剪、旋转、镜像 5 种标准的清洗方案 , 和自动识别人体、人脸等高级清洗方案等 , 大幅提升了清洗数据的效率 。
模型训练完成后就到了部署环节 , 这也是决定深度学习平台生态扩展能力的关键一环 。
在这一环节 , 有些开发者可能会问:我的数据私密性要求高 , EasyDL 训练的模型可以本地部署吗?对硬件要求高吗?想开发安卓的图像识别应用 , 平台是否支持?我想用设备端 SDK , 但没有自己的前端智能硬件设备怎么办?
目前 , EasyDL 提供了公有云 API、设备端 SDK、本地服务器部署、软硬一体部署四种方案 。
其中 , 公有云 API 可以支持弹性扩缩容 , 并使用在线数据闭环手动挖掘识别有错误的数据 , 有效持续迭代提升模型效果 。 设备端 SDK 支持超过 15 种芯片类型、Windows、Linux、Android、iOS 4 大常用操作系统 , 能满足各种定制化模型在端侧部署预测的需求 。 本地服务器部署支持企业将 AI 模型部署在本地服务器上 , 在本地局域网进行数据交互 , 保护数据隐私 。 在软硬一体方案部署上 , EasyDL 提供了 6 款软硬一体方案 , 支持专项适配与加速 , 覆盖高中低全矩阵 , 模型识别速度可提升 10 倍 。
【模型|不出所料,百度EasyDL市场份额还是第一】像家电一样简单的操作 , 像高级 AI 工程师一样专业的能力 , 这两个理念帮助 EasyDL 在短短的几年内吸引了 70 多万用户 。 那么 , 这些用户都来自哪些行业?EasyDL 帮他们解决了哪些问题?我们来一起梳理一下 。
哪些行业在用 EasyDL?
从整体来看 , EasyDL 的用户横跨互联网、智能硬件、零售、工业、医疗、安防监控、物流等多个行业 , 典型的应用场景包括生产安全、工业质检、货架巡检、盘点计数等 。
一般来讲 , 降本增效是企业的普遍诉求 。 以喷油器制造企业柳州源创电喷为例 , 这家公司在进行汽车喷油器阀座的质检时 , 每日的需求 4000-6000 件 , 峰值能达到 12000 件 , 但由于阀座体积非常小 , 人工检测非常费力 , 常规上要由熟练工人每天付出 4-7 班才能满足质检需求 , 时间成本与人力成本高昂 。
通过一场竞赛 , 柳州源创接入了 EasyDL 的图像能力 , 让 AI 作为 “质检之眼” , 实现了自动化检测瑕疵 。 通过打造一整套瑕疵识别、自动化分类流转的解决方案 , 柳州源创成功实现了零件瑕疵判读的无人化 , 公司可节约近 60 万 / 年的人力成本 , 检验效率整体提高了 30% , 这一个点的技术优化 , 助推企业加快产业升级迈出了一大步 。

文章图片

文章图片
在这一应用中 , EasyDL 的能力与效果被完全发掘 。 虽然阀座体积小、被检测瑕疵如黑点、划痕等目标更小 , 但基于 EasyDL 底层的超大规模预训练模型与优化封装好的模型训练算法 , 即使目标小也能准确完成识别 , 达到业务应用的要求 。 这样优异的模型效果 , 是企业在追求 AI 服务时最为看重的要素之一 , 能够帮助企业更高效地实现 AI 落地应用 。
此外 , EasyDL 还在诸多领域帮助企业实现业务和流程创新 。
以地铁维修为例 , 地下轨道建设和维修工作经常需要工人进入地铁的封闭轨行区进行操作 , 由于每次作业前都需要准备好必要的工具 , 所以工作前后都需要人工清点工具以避免遗漏在地下的封闭区域 。 而这样传统重复操作不光费时费力 , 往返路途也有很大的安全隐患 。 为此 , 长沙地铁借助 EasyDL 自主研发了「智能维修头盔」 , 能够自动拍照并识别常用工具名称和数量 , 及时查看是否有遗漏 , 降低安全隐患 。

文章图片
类似的应用还包括疫情期间的口罩佩戴识别、施工现场的安全帽佩戴识别等 。
EasyDL 的背后:十年磨一剑
EasyDL 这款 AI 平台的成功 , 离不开百度多年以来在 AI 领域的技术积累 。
2010 年初 , 已经有了 10 年技术积累的百度 , 开始全面布局人工智能 , 陆续开始了包括自然语言处理、机器翻译、语音、图像、知识图谱、机器学习、数据挖掘、用户理解等技术的研发 。
在之后的十年里 , 百度创造了多个「第一」:
2013 年初 , 百度成立了世界上第一个深度学习研究院;
2015 年 , 百度上线了世界上第一个大规模神经网络机器翻译系统;
2016 年 , 百度发布了开源深度学习平台飞桨 , 如今 , 飞桨已经成为中国首个开源开放、技术领先、功能完备的产业级深度学习平台;
2019 年 , 百度 ERNIE 模型在国际权威的通用语言理解评估基准 GLUE 上首次突破了 90 大关 , 获得全球第一;去年 , 这一模型又斩获全球规模最大的语义评测比赛 SemEval 2020 5 项冠军 , 刷新多模态领域权威榜单 VCR , 还拿到了世界人工智能大会的最高奖项——SAIL 奖;
……
这些奠基性的工作为 EasyDL 等产品的成功埋下了伏笔 。
从技术到硬件 , 从场景到应用 , 通过百度 AI to B 的重要承载者和输出者——百度智能云 , 为各行各业大规模输送百度的 AI 技术成果与平台能力 , 支持产业智能化升级 。 百度智能云拥有中国最领先的 AI 开放平台 , 日调用量突破 1 万亿 , 已开放超过 270 项 AI 能力 , 培养了超过 100 万人工智能领域的从业者 , 这个规模也在持续快速增长 。
有了这样坚实的支撑 , 百度 EasyDL 连续两年保持市场第一也是意料之中 。
推荐阅读







- Baidu|百度抢跑元宇宙 却默认“输给”字节?
- Tencent|继百度网盘后腾讯微云也已解除限速 不用单独下载App
- 词条|百度百科上线2500万词条,超750万用户参与共创科普知识内容
- Baidu|百度网盘青春版正式上线 只能传3次文件被吐槽是“一次性App”
- 青春|百度网盘青春版正式上线:免费空间 10GB,支持无差别速率下载
- Create|什么是元宇宙游戏?百度《希壤》成国内第一个吃螃蟹的人
- 模型|2022前展望大模型的未来,周志华、唐杰、杨红霞这些大咖怎么看?
- 量子|百度量子平台2.0重磅发布!推动构建量子计算领域繁荣生态
- 汽车|Apollo迎来7.0重大升级,百度自动驾驶开放平台迈向工具化时代
- 国计民生|25万亿级新蓝海!百度、华为、腾讯重磅出击,抢食智慧城市"大蛋糕",AI巨头如何赋能?来看真实案例