机器视觉系统是指用计算机来实现人的视觉功能 , 也就是用计算机来实现对客观的三维世界的识别 。 机器视觉系统主要由三部分组成:图像的获取、图像的处理和分析、输出或显示 。 你对机器视觉系统了多少?我们一起来了解一下吧 。
将近80%的工业视觉系统主要用在检测方面 , 包括用于提高生产效率、控制生产过程中的产品质量、采集产品数据等 。 产品的分类和选择也集成于检测功能中 。 下面通过一个用于生产线上的单摄像机视觉系统 , 说明系统的组成及功能 。
【光源|机器视觉系统三大组成部分及其功能介绍】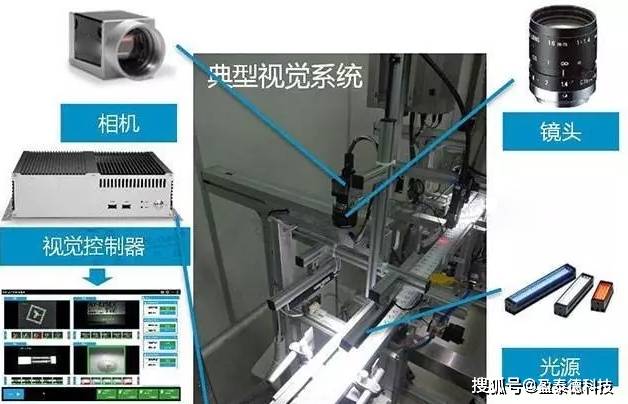
文章图片
视觉系统检测生产线上的产品 , 决定产品是否符合质量要求 , 并根据结果 , 产生相应的信号输入上位机 。 图像获取设备包括光源、摄像机等;图像处理设备包括相应的软件和硬件系统;输出设备是与制造过程相连的有关系统 , 包括过程控制器和报警装置等 。 数据传输到计算机 , 进行分析和产品控制 , 若发现不合格品 , 则报警器告警 , 并将其排除出生产线 。 机器视觉的结果是CAQ系统的质量信息来源 , 也可以和CIMS其它系统集成 。
一、图像的获取
图像的获取实际上是将被测物体的可视化图像和内在特征转换成能被计算机处理的一系列数据 , 它主要由三部分组成:
* 照明
* 图像聚焦形成
* 图像确定和形成摄像机输出信号
1)照明
照明和影响机器视觉系统输入的重要因素 , 因为它直接影响输入数据的质量和至少30%的应用效果 。 由于没有通用的机器视觉照明设备 , 所以针对每个特定的应用实例 , 要选择相应的照明装置 , 以达到效果 。
过去 , 许多工业用的机器视觉系统用可见光作为光源 , 这主要是因为可见光容易获得 , 价格低 , 并且便于操作 。 常用的几种可见光源是白帜灯、日光灯、水银灯和钠光灯 。 但是 , 这些光源的一个较大缺点是光能不能保持稳定 。 以日光灯为例 , 在使用的第一个100小时内 , 光能将下降15% , 随着使用时间的增加 , 光能将不断下降 。 因此 , 如何使光能在一定的程度上保持稳定 , 是实用化过程中急需要解决的问题 。
另一个方面 , 环境光将改变这些光源照射到物体上的总光能 , 使输出的图像数据存在噪声 , 一般采用加防护屏的方法 , 减少环境光的影响 。
由于存在上述问题 , 在现今的工业应用中 , 对于某些要求高的检测任务 , 常采用X射线、超声波等不可见光作为光源 。 但是不可见光不利于检测系统的操作 , 且价格较高 , 所以 , 目前在实际应用中 , 仍多用可见光作为光源 。
照明系统按其照射方法可分为:背向照明、前向照明、结构光和频闪光照明等 。 其中 , 背向照明是被测物放在光源和摄像机之间 , 它的优点是能获得高对比度的图像 。 前向照明是光源和摄像机位于被测物的同侧 , 这种方式便于安装 。 结构光照明是将光栅或线光源等投射到被测物上 , 根据它们产生的畸变 , 解调出被测物的三维信息 。 频闪光照明是将高频率的光脉冲照射到物体上 , 照像机拍摄要求与光源同步 。
2)图像聚焦形成
被测物的图像通过一个透镜聚焦在敏感元件上 , 如同照像机拍照一样 。 所不同的是照像机使用胶卷 , 而机器视觉系统使用传感器来捕捉图像 , 传感器将可视图像转化为电信号 , 便于计算机处理 。
选取机器视觉系统中的摄像机应根据实际应用的要求 , 其中摄像机的透镜参数是一项重要指标 。 透镜参数分为四个部分:放大倍率、焦距、景深和透镜安装 。
3)图像确定和形成摄像机输出信号
机器视觉系统实际上是一个光电转换装置 , 即将传感器所接收到的透镜成像 , 转化为计算机能处理的电信号、摄像机可以是电子管的 , 也可是固体状态传感单元 。
电子管摄像机发展较早 , 20世纪30年代就已应用于商业电视 , 它采用包含光感元件的真空管进行图像传感 , 将所接收到的图像转换成模拟电压信号输出 。 具有RS-170输出制式的摄像机可直接与商用电视显示器相连 。
固体状态摄像机是在20世纪60年代后期 , 美国贝尔电话实验室发明了电荷耦合装置(CCD) , 而发展起来的 。 它上分布于各个像元的光敏二极管的线性阵列或矩形阵列构成 , 通过按一定顺序输出每个二极管的电压脉冲 , 实现将图像光信号转换成电信号的目的 。 输出的电压脉冲序列可以直接以RS-170制式输入标准电视显示器 , 或者输入计算机的内存 , 进行数值化处理 。 CCD是现在最常用的机器视觉传感器 。
二、图像处理技术
机器视觉系统中 , 视觉信息的处理技术主要依赖于图像处理方法 , 它包括图像增强、数据编码和传输、平滑、边缘锐化、分割、特征抽取、图像识别与理解等内容 。 经过这些处理后 , 输出图像的质量得到相当程度的改善 , 既改善了图像的视觉效果 , 又便于计算机对图像进行分析、处理和识别 。
1)图像的增强
图像的增强用于调整图像的对比度 , 突出图像中的重要细节 , 改善视觉质量 。 通常采用灰度直方图修改技术进行图像增强 。
图像的灰度直方图是表示一幅图像灰度分布情况的统计特性图表 , 与对比度紧密相连 。
通常 , 在计算机中表示的一幅二维数字图像可表示为一个矩阵 , 其矩阵中的元素是位于相应坐标位置的图像灰度值 , 是离散化的整数 , 一般取0 , 1 , …… , 255 。 这主要是因为计算机中的一个字节所表示的数值范围是0~255 。 另外 , 人眼也只能分辨32个左右的灰度级 。 所以 , 用一个字节表示灰度即可 。
但是 , 直方图仅能统计某级灰度像素出现的概率 , 反映不出该像素在图像中的二维坐标 。 因此 , 不同的图像有可能具有相同的直方图 。 通过灰度直方图的形状 , 能判断该图像的清晰度和黑白对比度 。
如果获得一幅图像的直方图效果不理想 , 可以通过直方图均衡化处理技术作适当修改 , 即把一幅已知灰度概率分布图像中的像素灰度作某种映射变换 , 使它变成一幅具有均匀灰度概率分布的新图像 , 实现使图象清晰的目的 。
2)图像的平滑
图像的平滑处理技术即图像的去噪声处理 , 主要是为了去除实际成像过程中 , 因成像设备和环境所造成的图像失真 , 提取有用信息 。 众所周知 , 实际获得的图像在形成、传输、接收和处理的过程中 , 不可避免地存在着外部干扰和内部干扰 , 如光电转换过程敏感元件灵敏度的不均匀性、数字化过程的量化噪声、传输过程中的误差以及人为因素等 , 均会使图像变质 。 因此 , 去除噪声 , 恢复原始图像是图像处理中的一个重要内容 。
三、图像的数据编码和传输
数字图像的数据量是相当庞大的 , 一幅512*512个像素的数字图像的数据量为256 K字节 , 若假设每秒传输25帧图像 , 则传输的信道速率为52.4M比特/秒 。 高信道速率意味着高投资 , 也意味着普及难度的增加 。 因此 , 传输过程中 , 对图像数据进行压缩显得非常重要 。 数据的压缩主要通过图像数据的编码和变换压缩完成 。
图像数据编码一般采用预测编码 , 即将图像数据的空间变化规律和序列变化规律用一个预测公式表示 , 如果知道了某一像素的前面各相邻像素值之后 , 可以用公式预测该像素值 。 采用预测编码 , 一般只需传输图像数据的起始值和预测误差 , 因此可将8比特/像素压缩到2比特/像素 。
变换压缩方法是将整幅图像分成一个个小的(一秀取8*8或16*16)数据块 , 再将这些数据块分类、变换、量化 , 从而构成自适应的变换压缩系统 。 该方法可将一幅图像的数据压缩到为数不多的几十个特传输 , 在接收端再变换回去即可 。
1)边缘锐化
图像边缘锐化处理主要是加强图像中的轮廓边缘和细节 , 形成完整的物体边界 , 达到将物体从图像中分离出来或将表示同一物体表面的区域检测出来的目的 。 它是早期视觉理论和算法中的基本问题 , 也是中期和后期视觉成败的重要因素之一 。
2)图像的分割
图像分割是将图像分成若干部分 , 每一部分对应于某一物体表面 , 在进行分割时 , 每一部分的灰度或纹理符合某一种均匀测度度量 。 某本质是将像素进行分类 。 分类的依据是像素的灰度值、颜色、频谱特性、空间特性或纹理特性等 。 图像分割是图像处理技术的基本方法之一 , 应用于诸如染色体分类、景物理解系统、机器视觉等方面 。
图像分割主要有两种方法:一是鉴于度量空间的灰度阈值分割法 。 它是根据图像灰度直方图来决定图像空间域像素聚类 。 但它只利用了图像灰度特征 , 并没有利用图像中的其它有用信息 , 使得分割结果对噪声十分敏感;二是空间域区域增长分割方法 。 它是对在某种意义上(如灰度级、组织、梯度等)具有相似性质的像素连通集构成分割区域 , 该方法有很好的分割效果 , 但缺点是运算复杂 , 处理速度慢 。 其它的方法如边缘追踪法 , 主要着眼于保持边缘性质 , 跟踪边缘并形成闭合轮廓 , 将目标分割出来;锥体图像数据结构法和标记松弛迭代法同样是利用像素空间分布关系 , 将边邻的像素作合理的归并 。 而基于知识的分割方法则是利用景物的先验信息和统计特性 , 首先对图像进行初始分割 , 抽取区域特征 , 然后利用领域知识推导区域的解释 , 最后根据解释对区域进行合并 。
6)图像的识别
图像的识别过程实际上可以看作是一个标记过程 , 即利用识别算法来辨别景物中已分割好的各个物体 , 给这些物体赋予特定的标记 , 它是机器视觉系统必须完成的一个任务 。
按照图像识别从易到难 , 可分为三类问题 。 第一类识别问题中 , 图像中的像素表达了某一物体的某种特定信息 。 如遥感图像中的某一像素代表地面某一位置地物的一定光谱波段的反射特性 , 通过它即可判别出该地物的种类 。 第二类问题中 , 待识别物是有形的整体 , 二维图像信息已经足够识别该物体 , 如文字识别、某些具有稳定可视表面的三维体识别等 。 但这类问题不像第一类问题容易表示成特征矢量 , 在识别过程中 , 应先将待识别物体正确地从图像的背景中分割出来 , 再设法将建立起来的图像中物体的属性图与假定模型库的属性图之间匹配 。 第三类问题是由输入的二维图、要素图、2·5维图等 , 得出被测物体的三维表示 。 这里存着如何将隐含的三维信息提取出来的问题 , 当是今研究的热点 。
目前用于图像识别的方法主要分为决策理论和结构方法 。 决策理论方法的基础是决策函数 , 利用它对模式向量进行分类识别 , 是以定时描述(如统计纹理)为基础的;结构方法的核心是将物体分解成了模式或模式基元 , 而不同的物体结构有不同的基元串(或称字符串) , 通过对未知物体利用给定的模式基元求出编码边界 , 得到字符串 , 再根据字符串判断它的属类 。 这是一种依赖于符号描述被测物体之间关系的方法 。
转自:https://www.0755vc.com
推荐阅读







- 人物|马斯克谈特斯拉人形机器人:有性格 明年底或完成原型
- 硬件|Yukai推Amagami Ham Ham机器人:可模拟宠物咬指尖
- Insight|太卷了!太不容易了!
- 王者|布局手术机器人赛道,谁是王者? | A股2022投资策略⑩
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 孙自法|中国科技馆“智能”展厅携多款机器人亮相 喜迎新年和人机共融时代
- 国际|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 猎豹|数字化助力实体消费 机器人让商场“热”起来
- 机器人|微创血管介入手术机器人获国际创业大赛冠军,获价值千万元奖励
- 观众|中国科技馆“智能”展厅携多款机器人亮相