机器之心专栏
机器之心编辑部
Transformer 已经成为众多 NLP 任务以及部分 CV 任务的主流模型 , 但由于硬件资源匮乏 , 很多高校实验室或者公司都无法训练很大的模型 , 而降低批处理大小等措施又会导致训练时间成倍增加 。 针对这一痛点 , 字节跳动推出了 LightSeq 训练加速引擎 , 对 Transformer 训练的整个计算过程进行了优化 , 最多可以实现 3 倍以上的加速 。如今 , NLP 和 CV 领域的大部分任务都将 Transformer 作为基础模型 。 而早在 2019 年 12 月 , 字节跳动就开源过一款 Transformer类模型推理加速引擎——LightSeq [1] 。 作为业界第一款支持多种模型和解码方法的推理加速引擎 , LightSeq 的推理速度快于其它同类软件 , 更是远远超过了 TensorFlow 和 PyTorch 。
今天 , LightSeq 的最新版本发布了!
这次发布引入了引擎方面的重大更新——支持了 Transformer 全流程训练加速 , 在不同的批处理大小下相比主流训练库最高可加速 3 倍多!至此从训练到推理部署的整个过程都已被 LightSeq 打通 。
那么它到底采用了哪些技术呢?笔者将根据 LightSeq 公布的资料为你逐个揭晓 。
【编码|支持Transformer全流程训练加速,最高加速3倍!字节跳动LightSeq上新】LightSeq 能做什么?
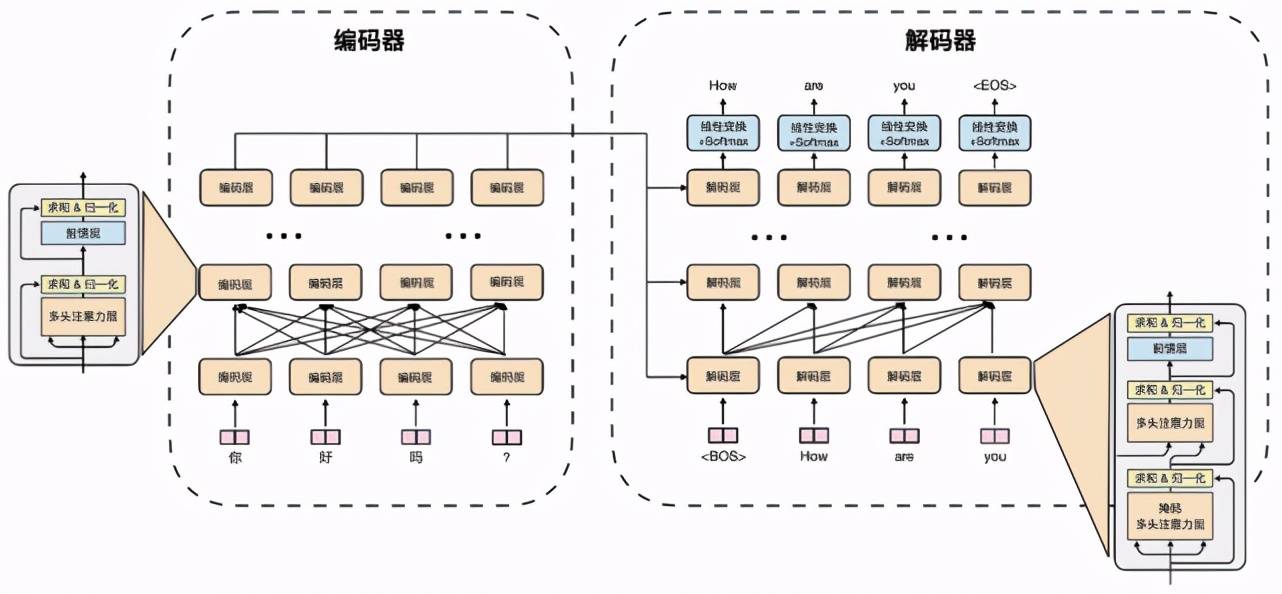
文章图片
图 1:Transformer 模型结构图(以机器翻译为例)
自 2017 年被谷歌提出之后 , Transformer 模型 [2] 成为了众多 NLP 任务以及部分 CV 任务的主流模型 , 尤其是机器翻译、文本生成、文本摘要、时间序列预测等任务 。 图 1 是机器翻译任务使用 Transformer 进行训练的一个例子 。
但由于硬件资源匮乏 , 很多高校实验室或者公司都无法训练很大的模型 , 而降低批处理大小等措施又会导致训练时间成倍增加 。 因此 , 如何利用有限的资源尽快训练出模型成为了亟待解决的问题 。
针对这一痛点 , 字节跳动推出了 LightSeq 训练加速引擎 , 对 Transformer 训练的整个计算过程进行了优化 。 从词嵌入层、编码层、解码层 , 到最后的损失函数层 , 从前向传播、反向传播、梯度同步 , 到最后的参数更新 , LightSeq 都进行了细致的性能分析和优化 。
以机器翻译任务为例 , 在该任务中 , 我们仅需要修改几行代码开启 LightSeq 训练加速 , 就可以实现最多 3 倍以上的加速 。
总的来说 , LightSeq 具有如下几个优点:
1. 支持Transformer 的完整加速 。
LightSeq 是业界第一款完整支持整个 Transformer 模型加速的训练引擎 , 包括了词嵌入层、编码层、解码层、损失函数层等高效自定义层 。 相比之下 , 另一款知名的深度学习优化引擎 DeepSpeed [3] 仅支持编码层的加速 , 因此只能用在 BERT 等模型上 , 局限性较大 。
2. 训练速度快 。
LightSeq 训练速度非常快 。 例如在 WMT14 [4] 英德机器翻译任务上 , 利用英伟达最新的训练显卡 A100 , 相比于主流序列生成库 , LightSeq 最快仅需要三分之一的训练时间 。
3. 功能全面 , 简单易用 。
LightSeq 提供了高效的 TensorFlow 和 PyTorch 自定义层供用户灵活使用 , 可以自由插入到 Hugging Face 等主流训练库中 。 除此之外 , 它还和当前流行的训练库如 Fairseq [5]、NeurST [6] 等做了深度集成 。 用户在安装 LightSeq 后 , 只需要修改几个命令行参数 , 就能在这些训练库上使用 LightSeq 。
4. 提供丰富的二次开发工具 。
LightSeq 提供了完整的 CUDA kernel 和 Transformer 自定义层的单元测试功能 , 可以测试自定义算子的正确性 , 同时分析出运行时间和加速比 , 帮助开发者更快地验证功能的正确性和有效性 。
下表 1 列举了不同训练加速引擎之间支持的功能对比:

文章图片
表 1:不同训练加速引擎支持功能对比
如何快速上手 LightSeq?
LightSeq 提供了多种便捷的运行方式 , 点击文末链接可以快速体验 。 这里简单讲解一下快速接入 LightSeq 进行训练的两种方式 。
使用自定义层
LightSeq 提供了许多自定义层供用户灵活使用 。
例如 , 如果你想将 Transformer 模型中的编码层替换为 LightSeq 的编码层 , 只需要提供一个编码层参数 , 用来初始化 LightSeq 编码层 , 然后就可以用它来替换原始的编码层 , 加速模型训练 。 详细代码如下(这里省略了部分配置参数):
一键启动
LightSeq 还和几个当前流行的训练库(例如 Fairseq 和 NeurST)做了深度集成 , 仅需修改很少的代码就能开启 LightSeq 加速 。
Fairseq
LightSeq 为 Fairseq 提供了一套完整便捷的 Transformer 训练样例 。
首先 , 你需要安装 Fairseq 以及必要的第三方库 , 然后用如下命令安装 LightSeq 加速库:
接着就可以通过 LightSeq 提供的启动器 , 灵活地指定使用 LightSeq 优化版本的 Transformer 模型、参数优化器和损失函数 。 下面是启动参数样例(这里省略了和 LightSeq 无关的参数):
NeurST
NeurST 是一款同时支持 TensorFlow 和 PyTorch 的开源序列生成库 , 可以用来做文本生成、机器翻译和语音翻译 。 LightSeq 已经与其进行了深度融合 , 无需用户修改代码和启动参数即可直接进行加速训练 。
首先需要安装 NeurST , 官方提供了详细的安装教程 [6] 。
然后安装 TensorFlow 版本的 LightSeq , 命令如下:
这样 , NeurST 就会自动识别 LightSeq 已经安装成功 , 调用 lightseq 库进行模型构建来加速训练 , 无需修改启动参数 。 运行命令详见 NeurST 提供的机器翻译样例 [7] 。
性能测试
在 WMT14 标准的英德翻译任务上 , LightSeq 做了评测实验 。 以当前流行的 Fairseq 训练库(基于 PyTorch)和被广泛使用 Apex 工具库 [8] 为基准 , 测试了 LightSeq 的训练性能 。 实验在 NVIDIA Tesla V100 和 NVIDIA Ampere A100 上进行 , 采用单机八卡数据并行训练和 16 位浮点数混合精度 。
在不同模型大小和批处理大小下 , LightSeq 对单步训练速度的提升结果如图 2 所示:
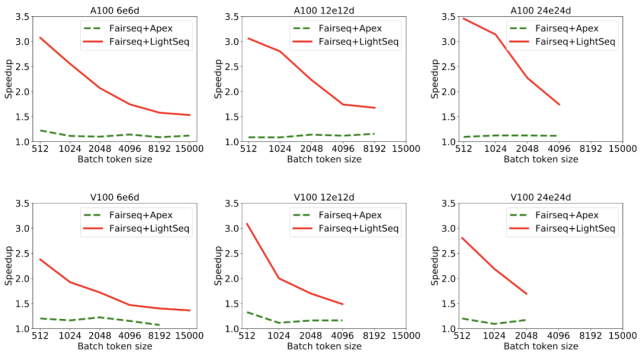
文章图片
图 2:A100 和 V100 显卡下不同层数模型加速比
这里所有模型的词表大小为 40k , 编码层和解码层隐层维度是 1024 , 注意力头数为 16 。 e 和 d 分别表示编码器和解码器的层数 。 加速比的计算采用了每秒训练有效单词数(real word per second)这一常见指标 。
可以发现:
1. 使用了 LightSeq 后 , 单步训练速度有 45%-250% 的提升 。 作为对比 , Apex 仅有 5%-30% 的提升 。 LightSeq 能取得这种大幅度的性能提升 , 源自其对模型进行了全流程的细致优化 。
2. Apex 显存使用量对比原生 Fairseq 略有提升 , 例如 V100 上 , Apex 导致 6e6d 的模型在 15000 批处理大小上出现了显存溢出 , 而 LightSeq 仍然可以正常训练 。 这证明了 LightSeq 在保证高效计算的同时 , 也做到了高效使用显存 , 这个特征在显存有限或者训练大模型时非常关键 。
3. 随着批处理大小的增加 , LightSeq 加速比逐渐降低 。 其原因是 , 经过 LightSeq 优化后 , 单步训练中矩阵乘法占比提高 , 显卡的计算吞吐成为训练速度的瓶颈 。 这表明 LightSeq 已经对计算资源做到了充分利用 。 也解释了为什么计算吞吐更高的 A100 , 平均会取得比 V100 高 15% 左右的加速比 。
最后在 WMT14 英德翻译数据集上测试了图 1 中 Transformer 模型训练至收敛的时间 , 结果如图 3 所示:
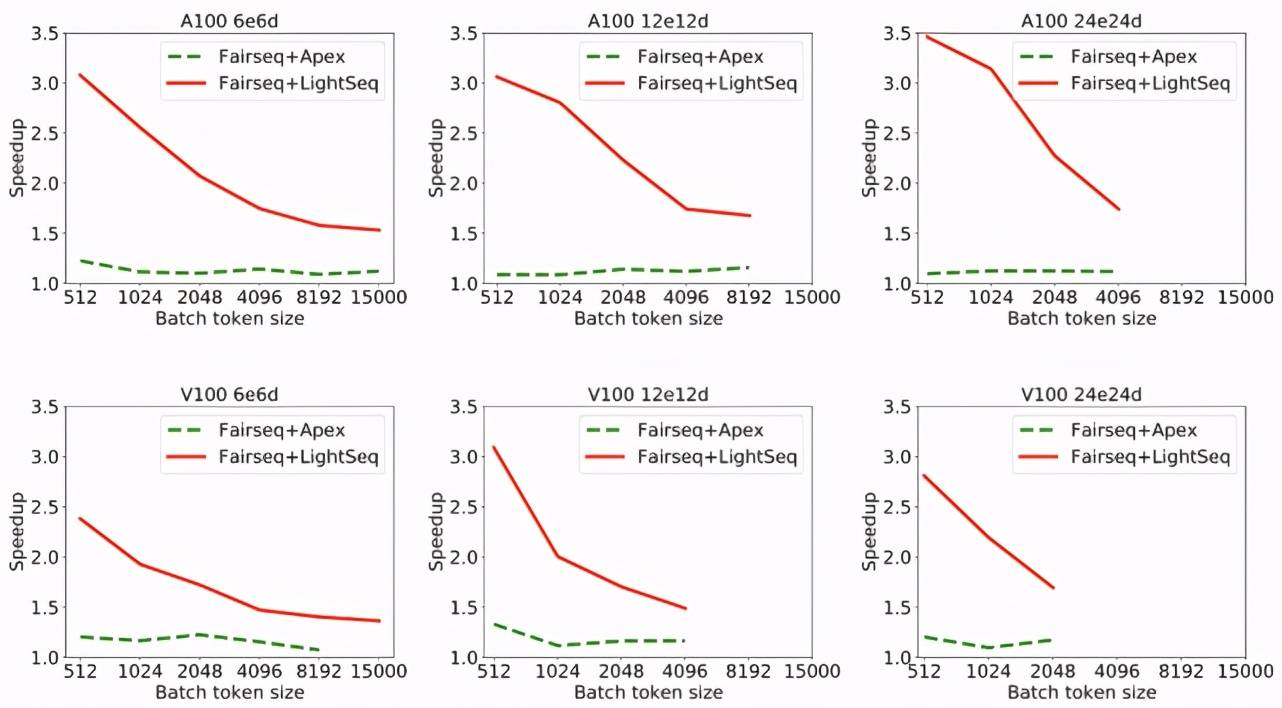
文章图片
图 3:A100 和 V100 显卡下不同模型训练总时间
由于 LightSeq 的计算优化是无损的 , 不会影响模型训练至收敛的训练步数 , 所以收敛时间的提升和单步训练时间的提升趋于一致 。 观察可以发现 , LightSeq 最多可将模型训练时间由 8.5 小时降低到 3.8 小时 。
可视化分析
为了更清楚地看出 LightSeq 优化前后模型的运算情况 , 我们用 Nsight Systems [9] 可视化模型训练过程中单步的算子调用情况来展示 。
首先是 Fairseq+Apex 的可视化 , 结果如图 4 所示 。 总耗时在 288ms 左右 , 三个红色框分别表示前向传播、反向传播、梯度同步与参数更新 。 可以看出前向传播的算子排列比较稀疏 , 存在很大的优化空间 。

文章图片
图 4:Fairseq+Apex 单步训练过程可视化
然后是 Fairseq+LightSeq 的可视化 , 结果如图 5 所示 , 总耗时降到了 185ms 左右 。 而且 LightSeq 的算子排列更加紧密 , 大大增加了显卡的利用率 。

文章图片
图 5:Fairseq+LightSeq 单步训练过程可视化
CUDA kernel性能
此外还测试了 LightSeq 单卡情况下所有 CUDA kernel 的性能 , 对比了 PyTorch、TensorFlow(XLA 编译优化)、DeepSpeed 和 LightSeq 四种实现方式 。 由于 kernel 太多 , 这里只列举了部分实验结果 。
首先对比了最常用的 dropout , 图 6 是 V100 显卡上 16 位和 32 位浮点数 dropout 不同实现的加速对比结果:

文章图片
图 6:dropout 加速对比
从图 6 中可以看出 , LightSeq 的实现要远远快于 PyTorch 和 DeepSpeed 。 DeepSpeed 在元素数量过百万之后逐渐不如 PyTorch , 而 LightSeq 始终比 PyTorch 快 。 随着元素数量的增加 , LightSeq 和 DeepSpeed 的速度都会有明显下降 。 TensorFlow 在开启了 XLA 之后速度依然落后于 PyTorch , 且随着元素数量的增加差距逐渐缩小 。
然后对比了注意力机制中的 softmax 函数 , 测试了实际训练场景中批处理大小为 8192 情况下的加速比 。 图 7 是 V100 显卡上 16 位和 32 位浮点数 softmax 不同实现的加速对比结果 , 因为 DeepSpeed 只支持句子长度为 8 的整数倍 , 所以这里只测试了长度为 32 的整数倍的句子计算速度:
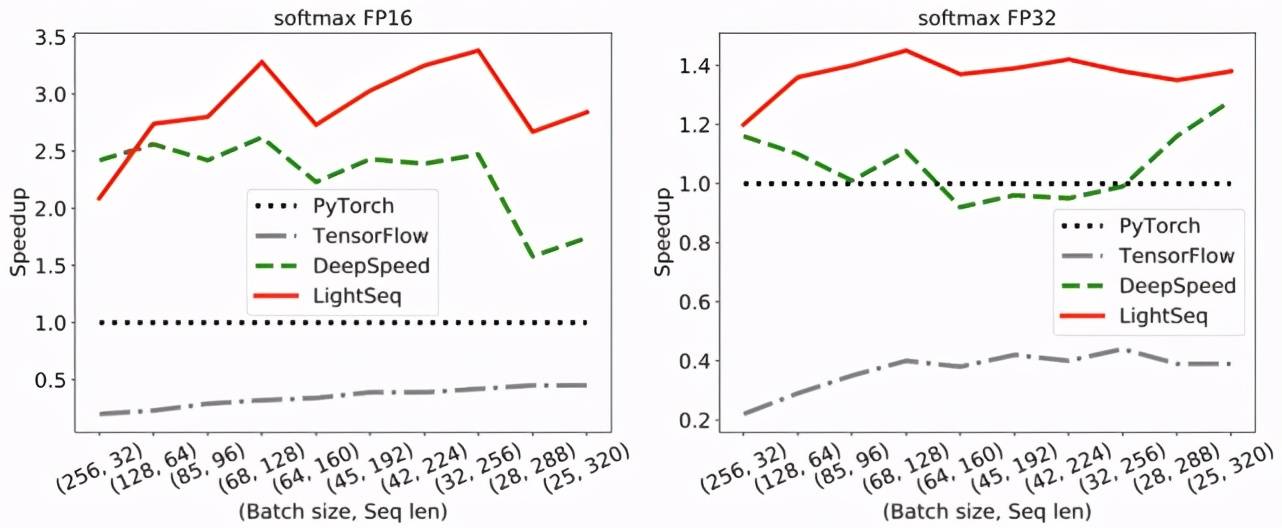
文章图片
图 7:softmax 加速对比
可以看出 , LightSeq 几乎在所有情况下都远远快于 DeepSpeed 。 且随着序列长度增加 , LightSeq 加速比逐渐增大 。 而 DeepSpeed 在 16 位浮点数情况下加速比会逐渐减小 , 在 32 位浮点数情况下甚至会出现比 PyTorch 还要慢的情况 。 TensorFlow 即便使用 XLA 融合算子 , 运算速度也远远落后于其它三种实现 。
在其它多数 kernel 测试中 , LightSeq 都要快于其它三种实现 。
关键技术
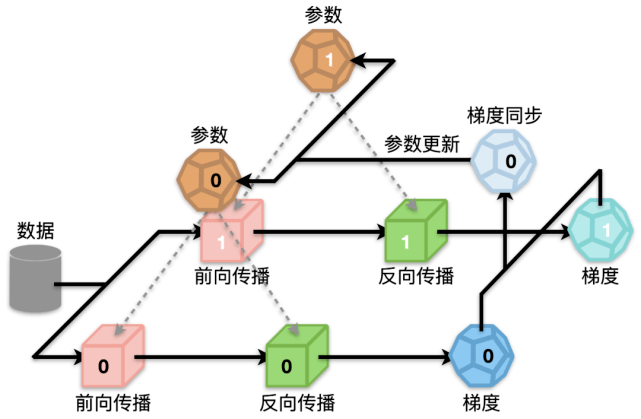
文章图片
图 8:模型训练过程
如图 8 所示 , 以 2 卡为例 , 一个完整的 Transformer 模型训练过程主要包括四个步骤:前向传播、后向传播、梯度同步和参数更新 。 其中前向传播和后向传播占模型训练总时间的 70% 多 , 包含了众多计算密集型和 I/O 密集型操作 , 因此是优化的重点 。 而梯度同步虽然耗时相对较少 , 但是也可以通过和反向传播并行化等方法隐藏掉大部分延时 。 最后优化器更新参数方面也大有文章可做 , 可以从计算和 I/O 两个方面降低延时 。
下面详细介绍优化这四个步骤的几种技术:算子多运算融合、输入输出层融合、动态显存复用和参数连续化 , 最后介绍一下 LightSeq 提供的单元测试功能 。
算子多运算融合
在大多数深度学习框架(例如 TensorFlow 和 PyTorch)中 , 一个简单的运算通常都需要很多细粒度的核函数来实现 。 例如在 TensorFlow 中 , 一次层归一化(Layer Normalization)操作需要调用三次核函数以及两次中间显存读写 , 非常耗时 。 而基于 CUDA , LightSeq 定制化了一个层归一化专用的核函数 , 将两次中间结果的写入寄存器 。 从而实现一次核函数调用 , 同时没有中间结果显存读写 , 因此大大节省了计算开销 。
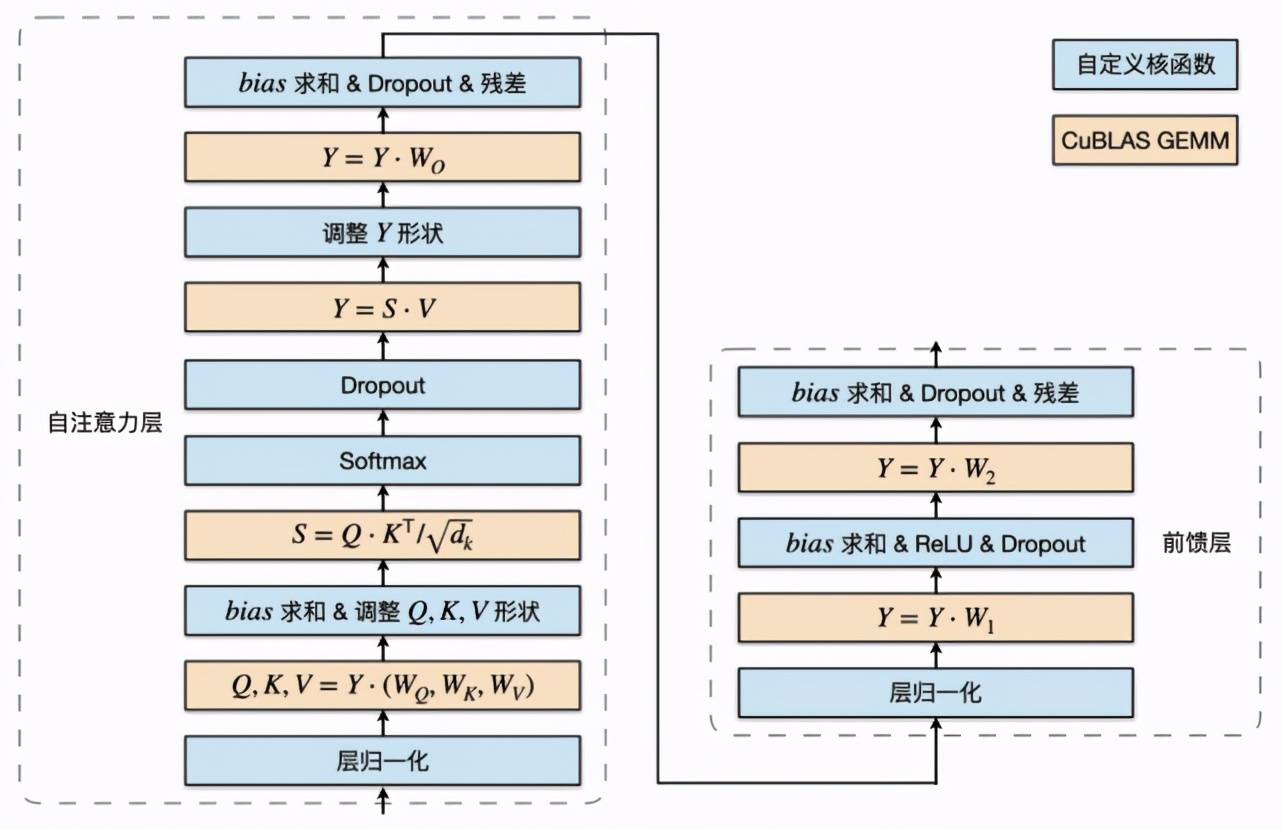
基于这个思路 , LightSeq 利用 CUDA 矩阵运算库 cuBLAS [10] 提供的矩阵乘法和自定义核函数实现了 Transformer 的编码器和解码器 。 以编码层为例 , 具体结构如图 9 所示:
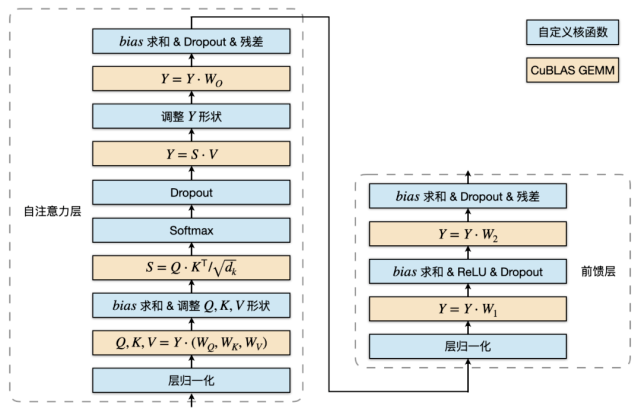
文章图片
图 9:编码层计算过程
蓝色部分是自定义核函数 , 黄色部分是矩阵乘法 。 可以发现 , 矩阵乘法之间的运算全部都用一个定制化核函数实现了 , 因此大大减少了核函数调用和显存读写 , 最终提升了运算速度 。
LightSeq 还优化了核函数的实现 , 采用 float4 数据类型来进行数据读写 , 大大增加了数据的吞吐量 , 减小了核函数执行的延时 。 LightSeq 支持任意长度的序列输入 , 根据不同的序列长度选择最合适的核函数来调用执行 。 相比之下 , DeepSpeed 多数核函数只支持句子长度为 8 的整数倍 , 因此速度较慢 , 局限性较大 。
输入输出层融合
此外 LightSeq 还实现了词嵌入层和损失函数层的算子融合 。 对于词嵌入层 , LightSeq 将词表查找与放缩、位置向量融合以及 dropout 操作都写成了一个核函数 。 对于损失函数层 , 将交叉熵损失融合成一个核函数 。 通过输入输出层的融合 , 进一步减小了模型训练的时间 , 增加了显卡利用率 。
以词嵌入层为例 , 图 10 展示了输入句子中单词 id 之后 , 词嵌入层进行的计算过程:
文章图片
图 10:词嵌入层计算过程
可以看出 , 在融合之前 , 一个词嵌入层需要经过词向量查找与放缩、位置向量查找、两者相加、dropout 五种运算 , 因此需要频繁调用核函数 , 非常耗时 。 而将这五个操作融合成一个核函数可以大大加快获取最终词表示的速度 。
动态显存复用
为了避免计算过程中的显存申请释放并节省显存占用 , LightSeq 首先对模型中所有动态的矩阵大小都定义了最大值(例如最大序列长度) 。 接着在模型初始化的时候 , 为计算过程中的每个中间计算结果按最大值分配显存 , 并对没有依赖的中间结果共用显存 。
参数连续化
LightSeq 将 Transformer 每一层中所有的参数都绑定在一起 , 做连续化处理 。 初始化模型某一层的时候只需要定义一个参数 , 参数量为原始模型该层总的参数量 。 在后续计算时 , 只需要从这个参数的对应位置处取出原始参数值即可 。
以编码层为例 , 自注意力层和前馈层共有 16 个参数 , 假设总参数量为 S 。 于是可以定义一个大小为 S 的参数 , 按照原始各个参数的参数量来划分出 16 个块 , 连续存储 16 个参数 , 在计算时只需要取出对应的参数块即可 。
参数连续化能显著降低参数更新期间拷贝、同步、计算的次数 。 实验分析发现 , 进行了这项优化后 , 优化器性能提升了 40%-50% 。
开发工具
LightSeq 提供了丰富的单元测试功能 , 不仅可以测试所有的自定义核函数和自定义层的正确性 , 还可以对比测试不同实现之间的速度 。 用户可以自由指定测试的组数、每组重复运行次数、容差和数据类型 。
具体步骤上 , 首先用户需要构造随机数据 , 然后根据数据类型选择不同的 CUDA 核函数 , 最后分别实现自定义和基准的计算函数即可 。 这样就保证了用户可以基于自身场景进行更进一步的二次定制开发 。
总结
LightSeq新版训练加速引擎全方面提升了Transformer模型的训练速度 , 打通了训练和推理部署全流程 , 使用灵活方便 。 大大缩减了科研工作者们训练模型的成本 。 可以期待未来像机器翻译、文本生成、摘要、对话生成、情感分析等大量NLP应用场景可以使用LightSeq来训练和推理 。
LightSeq 地址:
https://github.com/bytedance/lightseq
参考文献:
[1] LightSeq: https://github.com/bytedance/lightseq
[2] Transformer: "Attention is all you need", NIPS (2017)
[3] DeepSpeed: https://github.com/microsoft/DeepSpeed
[4] WMT14: http://www.statmt.org/wmt14/
[5] Fairseq: https://github.com/pytorch/fairseq
[6] NeurST: https://github.com/bytedance/neurst/tree/lightseq
[7] NeurST 机器翻译样例:
https://github.com/bytedance/neurst/tree/lightseq/examples/translation
[8] Apex: https://github.com/NVIDIA/apex
[9] Nsight Systems: https://developer.nvidia.com/nsight-systems
[10] cuBLAS: https://docs.nvidia.com/cuda/cublas/index.html
推荐阅读







- 微信|积极落实互联互通,微信收款码支持云闪付及银行APP支付物料落地
- 手机|黑莓宣布 1 月 4 日起将终止 BlackBerry OS 设备服务支持
- 硬件|闪极140W多口充电器发布:首发399元 支持PD3.1
- 微信|微信支付“九宫格”全面支持开通中国银联云闪付
- 办公|统信UOS助手发布:支持“一键秒传”
- 支持|神评 | 你涨任你涨,我买算我输
- 传统|联想预热 135W 充电器,新款拯救者笔记本有望支持 PD 3.1
- 支持|联发科OPPO携手推进5G普及,OPPO A72首发天玑720
- HONOR|荣耀Magic V已完成3C认证 支持66W快充
- Windows|Windows 11“Sun Valley 2”将引入对第三方Widgets的支持