实例|新入坑的SageMaker Studio Lab和Colab、Kaggle相比,性能如何?( 三 )
奇怪的是 , Colab Pro High RAM 实例的训练速度比普通 Colab Pro 实例慢 , 尽管前者有更多的 CPU 核和 CPU RAM 以及相同的 GPU 。 然而 , 它们之间的差异并不大 。
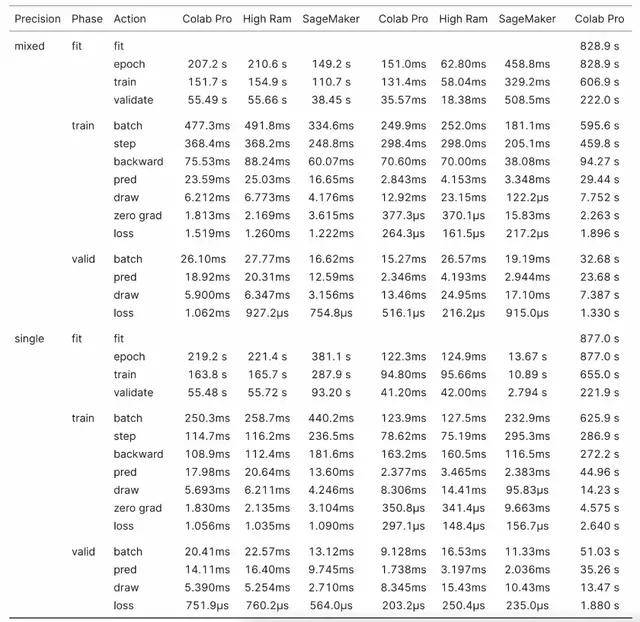
文章图片
表 3:RoBERTa 基准结果
XResNet18
对于 XResNet18 基准测试 , 了解绘制动作测量内容很关键 。 XResNet18 基准测试是从数据加载器绘制 batch 之前到开始 batch 操作之间的时间 。 数据加载器的 prefetch_factor 设置为默认值 2 , 这意味着研究者尝试在训练循环调用它们之前提前加载两个 batch 。 其中包括前向和后向传递、损失和优化器 step 和零梯度操作 。
绘制动作越低 , 实例 CPU 就越能满足需求 。
这里的结果符合预期 , 更多的 CPU 核意味着更少的绘制时间 , 并且在相同的核数下 , 较新的 CPU 的性能优于较旧的 CPU 。
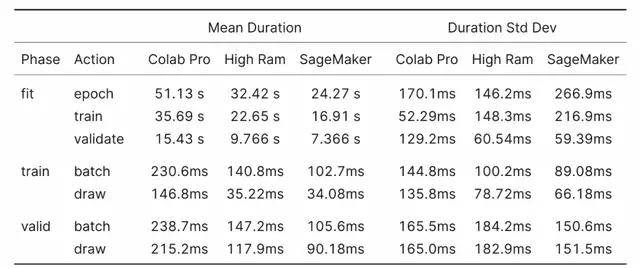
文章图片
表 4:XResNet18 基准结果
Colab Tesla K80
由于免费 Colab 实例的 Tesla K80 的 RAM 比其他 GPU 少四分之一 , 因此我将混合精度 batch 大小也减少了四分之一 。 此外 , 我没有运行任何单精度测试 。
我运行了两个 epoch 的 Imagenette 基准测试 , 并将 IMDB 数据集从 20% 的样本减少到 10% 的样本 , 并将训练长度减少到一个 epoch 。
Colab K80 在半数 Imagenette epoch 上进行训练花费的时间大约是 Colab Pro 实例的两倍 。 与 Colab P100 相比 , 在 Colab K80 上进行等效的 IMDB 训练时间要长 3 倍 。 如果可能的话 , 应避免使用 K80 对除小型模型以外的任何其他模型进行训练 。
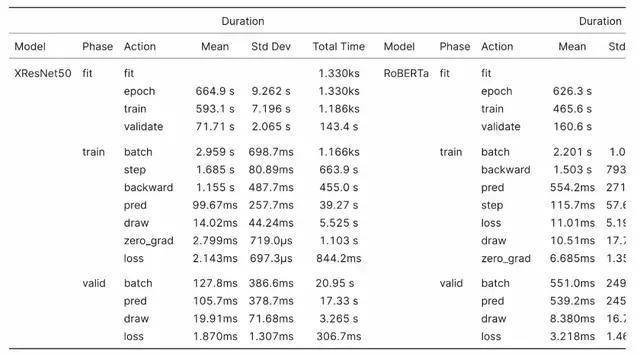
文章图片
XResNet & RoBERTa Colab K80 基准结果
总的来说 , 我认为 SageMaker Studio Lab 是免费计算资源领域一个强有力的竞争对手 。 特别是对于一直在 K80 上使用免费 Colab 和训练模型的用户来说 , SageMaker Studio Lab 将给你全面的升级体验 。
SageMaker Studio Lab 可以作为机器学习工作流程的有用补充和 Kaggle 或 Colab Pro 的增强版 。 混合精度的训练速度比 Kaggle 或 Colab Pro 快了 17.4% 到 32.1% , 这意味着迭代时的等待时间更少 。
此外 , 更快的训练速度和持久存储让 SageMaker Studio Lab 对于深度学习初学者也非常友好 , 因为这意味着环境只需要设置一次 , 让学生能够专注于学习而不是持续的包管理 。
【实例|新入坑的SageMaker Studio Lab和Colab、Kaggle相比,性能如何?】原文链接:https://benjaminwarner.dev/2021/12/08/testing-amazon-sagemaker-studio-lab
推荐阅读







- 安全|CISA发布Apache Log4j漏洞扫描器 以筛查易受攻击的应用实例
- 文化|三星堆6个新埋藏坑有何未解之谜?
- Tesla|售16-20万元 特斯拉全新入门车型渲染图曝光:2023年亮相售
- 通信技术|一文看懂HDMI 2.1虚标门:用户被坑不是第一次了
- 设计|有猫腻?为什么功能一样,充电器价格相差十万八千里?看完别再被坑
- 功能|适老化改造避坑指南!老年用户喜欢这样的手机银行
- 实例|一日一技 | 让 Windows 沙盒更好用:wsb 文件配置实例
- 核工业|把高放废物深埋地下 科学“挖坑”有讲究
- AI|Meta新AI工具Few-Shot Learner可通过较少或无实例就能检测错误信息
- Huawei|麒麟9000库存用尽?曝华为Mate 40新入网机型搭载麒麟990 支持5G