import|GitHub 7.5k star量,各种视觉Transformer的PyTorch实现合集整理好了
机器之心报道
编辑:杜伟
这个项目登上了今天的GitHub Trending 。近一两年 , Transformer 跨界 CV 任务不再是什么新鲜事了 。
自 2020 年 10 月谷歌提出 Vision Transformer (ViT) 以来 , 各式各样视觉 Transformer 开始在图像合成、点云处理、视觉 - 语言建模等领域大显身手 。
之后 , 在 PyTorch 中实现 Vision Transformer 成为了研究热点 。 GitHub 中也出现了很多优秀的项目 , 今天要介绍的就是其中之一 。
该项目名为「vit-pytorch」 , 它是一个 Vision Transformer 实现 , 展示了一种在 PyTorch 中仅使用单个 transformer 编码器来实现视觉分类 SOTA 结果的简单方法 。
项目当前的 star 量已经达到了 7.5k , 创建者为 Phil Wang , ta 在 GitHub 上有 147 个资源库 。

文章图片
项目地址:https://github.com/lucidrains/vit-pytorch
项目作者还提供了一段动图展示:

文章图片
项目介绍
首先来看 Vision Transformer-PyTorch 的安装、使用、参数、蒸馏等步骤 。
第一步是安装:
$ pip install vit-pytorch
第二步是使用:
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
【import|GitHub 7.5k star量,各种视觉Transformer的PyTorch实现合集整理好了】dropout = 0.1,
emb_dropout = 0.1
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
第三步是所需参数 , 包括如下:
- image_size:图像大小
- patch_size:patch 数量
- num_classes:分类类别的数量
- dim:线性变换 nn.Linear(..., dim) 后输出张量的最后维
- depth:Transformer 块的数量
- heads:多头注意力层中头的数量
- mlp_dim:MLP(前馈)层的维数
- channels:图像通道的数量
- dropout:Dropout rate
- emb_dropout:嵌入 dropout rate
- ……
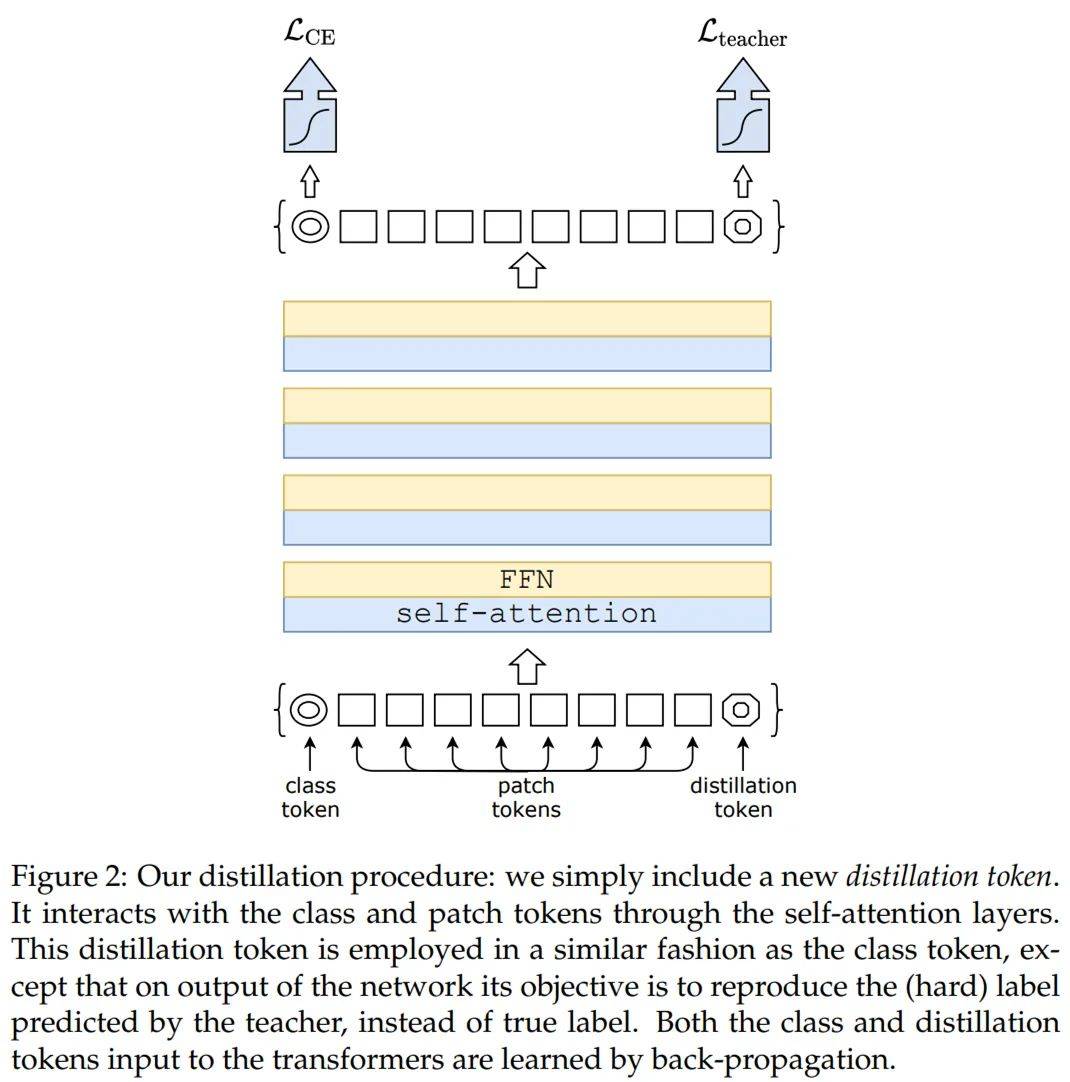
文章图片
推荐阅读







- GitHub|国产老牌 PDF 工具“PDF 补丁丁”宣布开源,代码已托管至 GitHub
- GitHub|小米 12 / Pro / X 系列内核源码已公开,基于 Android 12
- 用户|全新微软 Win11 WSA 开源工具上线 GitHub:支持双击 APK 安装
- AI|女神青涩时纤毫毕现:腾讯AI模型GFPGAN火上GitHub热榜第一
- 代码|微软 GitHub 大幅改进代码搜索功能,已发布技术预览版
- Microsoft|微软旗下GitHub更换CEO 由产品主管接手
- 市场资讯|微软旗下GitHub更换CEO 由产品主管接手
- GitHub|GitHub:30%的新增代码由AI工具Copilot完成
- 软件和应用|GitHub Copilot现在开始支持Neovim和JetBrains IDE
- Microsoft|GitHub:30%的新写代码都是在AI编程工具Copilot帮助下完成的