建模|该把优惠券发送给哪些用户?一文读懂Uplift模型( 二 )
这种建模方法较简单且易于理解,可以直接用回归、GBDT等模型实现。但也存在一些局限性:对照组和实验组分别建模,两个模型完全隔离,可能两个模型各有偏差从而导致预测的误差较大。其次建模的目标是Response而不直接是Uplift,因此模型对Uplift的预测能力较有限;策略只能是离散值,不能是连续变量,因为有几种策略就需要建几个模型。
所以当干预条件只有‘是否发优惠券’时,此建模方法可行,但是当涉及到‘多种优惠券面额/文案组合策略’或者‘发多大面额优惠券这种连续变量策略’时,本种建模方法可能并不非常work;
2. Single-LearnerSingle-Learner在Two-Learner的基础上,将对照组数据和实验组数据放在一起建模,使用一个模型对处理效果进行估计,然后计算该样本用户进入实验组和对照组模型预测的差异作为对实验影响的估计。
与Two-Learner不同的是,本模型将实验分组(干预项)作为一个单独特征和其他变量一起放入模型中对用户购买行为进行建模,干预项可以是多种组合策略或者连续变量。
训练样本共用可以使此模型学习更加充分,通过单个模型的学习也可以避免双模型打分累积误差较大的问题。此外模型可以支持干预项为多策略及连续变量的建模,实用性较强。但此模型在本质上依然还是对Response建模,对Uplift的预测还是比较间接。
3. Class Transformation MethodClass Transformation Method模型既可以将实验组与对照组数据打通,同时它又是直接对Uplift score进行预测,计算用户在实验组中购买概率与在对照组中购买概率的差值,其核心思想是将实验组和控制组样本混合并创建新的变量z满足:
- 当用户在实验组(发券)且用户最终购买时,z=1
- 当用户在对照组(无干预)且用户最终未购买时,z=1
- 当用户在实验组(发券)且用户最终未购买时,z=0
- 当用户在对照组(无干预)且用户最终购买时,z=0
三、Uplift模型评估根据Uplift Score的定义,分数越高的用户即所谓的营销增益就越大。增益模型由于不能同时观测同用户在不同干预项下的真实增量,通常是通过划分十分位数来观测实验组用户和对照组用户样本来进行间接评估。
1. Uplift 十分位柱状图将测试集预测出的用户按照Uplift Score由高到低平均分为10组,分别是top 10%用户,top 20%用户……top 100%用户。分别对每个十分位内的用户求实验组和对照组预测分数的均值,然后相减,计算不同分段中真正的实验提升收益。然后根据每个分组得出的实验收益,绘制十分位柱状图。这样,即可较直观观察到有多少的用户大概可以获得多少的营销增益。
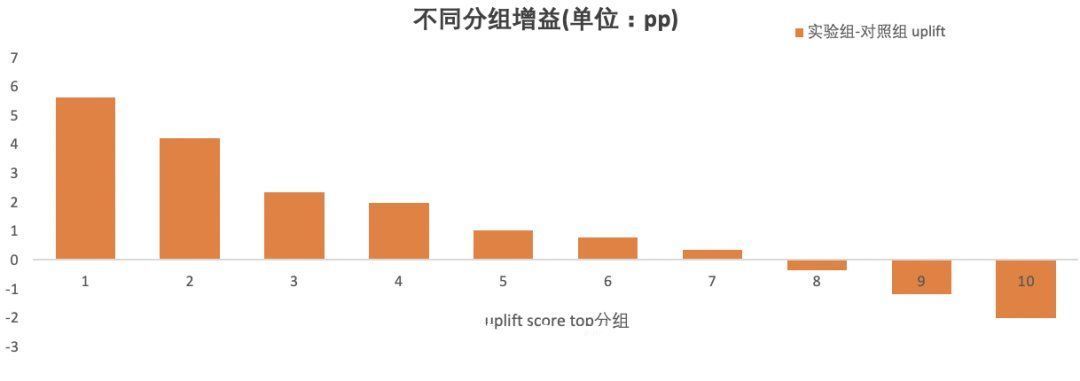
文章插图
2. qini曲线(qini curve)计算每组用户百分比的qini系数,将这些系数连接起来,得到一条qini曲线。qini系数公式如:
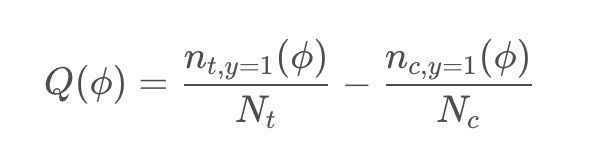
文章插图
?是按照Uplift Score由高到低排序的用户数量占实验组或对照组用户数量的比例,?= 0.3即表示实验组或对照组中前30%的用户。nt,y=1(?)表示在前百分比多少用户中,实验组中预测结果为购买的用户数量。nc,y=1(?)表示在同样百分比用户中,对照组预测结果为购买的用户数量。Nt和Nc则分别代表实验组和对照组总用户样本数。
文章插图
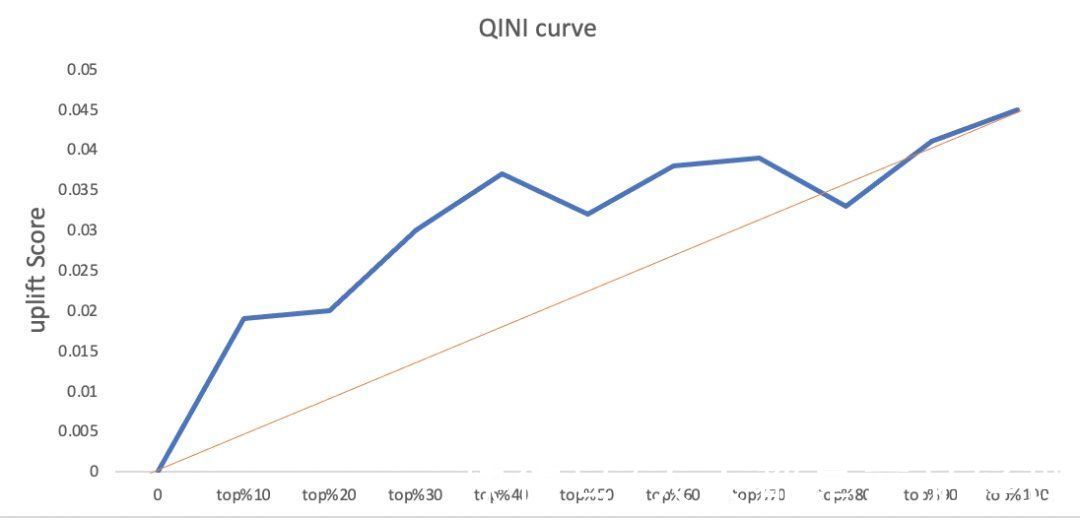
上图橙色线是随机曲线,qini曲线与随机曲线之间的面积作为评价模型的指标,面积越大表示模型结果远超过随机选择的结果。可以看到当横轴为top40%时,qini曲线与随机曲线之间距离最大,对应的纵轴大概是0.037,表示uplift score等于0.037可以覆盖前40%的用户数量,这部分用户也就是我们可以对其进行营销干预的persuadable用户。
推荐阅读







- 加班|360 周鸿祎:程序员不应该 35 岁被抛弃
- 恕我直言|“恕我直言,应该没人能驾驭的了这件衣服,哈哈哈哈哈太好笑了”
- 王璐|直播电商下一轮,该考验平台服务能力了
- 角度看|线上二手交易突破万亿规模 平台须严把质量关
- 东莞|马云刘强东投资百亿,华为把总部搬过去,这座城市现在如何?
- vr|「盘中宝」腾讯迈出元宇宙关键一步,该领域或为元宇宙入口最确定赢利点,这家公司已有产品应用于科技冬奥会
- 和尚|把梳子卖给和尚就是好销售吗马云告诉你正确答案
- 趋势报告|2022年,消费品牌如何把握新的商业脉络?
- 商家|戴珊上任“第一把火”:淘宝和天猫合体,利好中小商家
- 颗粒度|业务想大多全,用户要精准简,首页设计该如何破局?