模型|10分钟帮你清晰理解「Inmon数据仓库建设」( 二 )
数据建模分为三个层次:高层模型、中间层模型、底层模型。
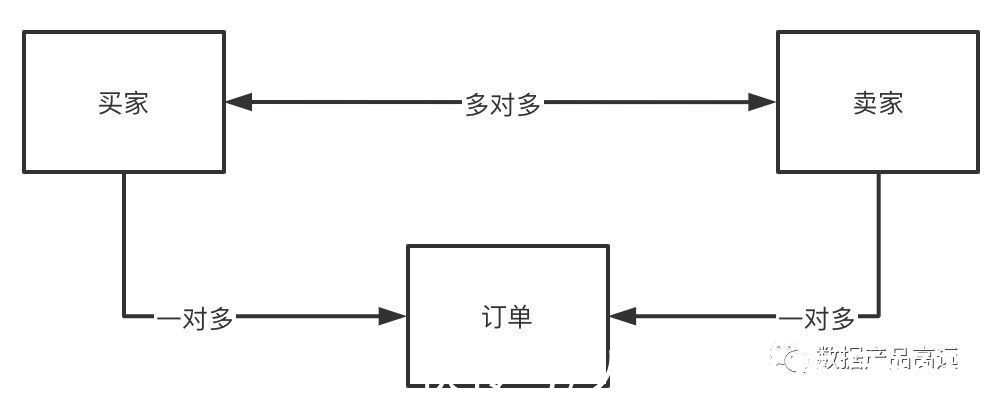
(1)高层模型(实体关系)
最抽象原始的一层,整个业务环境中最显著的关系。例如:我们现在要进行电商业务的实体关系抽象(买家、卖家、订单)。简化一下这个模型,并且表明实体之间的关系是:一对一、一对多、多对多。
文章插图
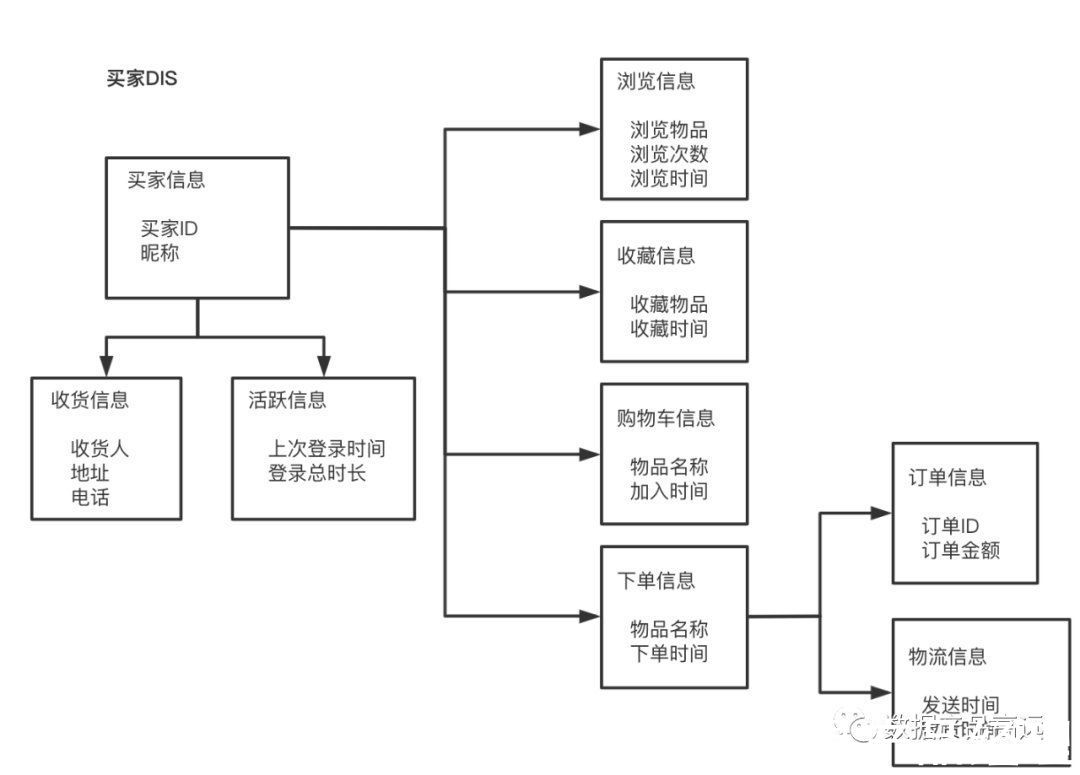
(2)中间层模型(数据项集或者DIS)
对高层模型中每个实体建一个中间层模型。即:上述模型中每一个实体(卖家、买家、订单)都对应一个DIS。中间层模型的4个基本构造:
- 主要数据分组:每个主题域有且只有一个主要数据分组。例如:下图中的买家信息
- 二级数据分组:每个主题域存在多次的属性。例如:下图中的收货信息
- 连接器:表示各个主题域之间关联的外键。
- 数据的类型:这里可以理解为某个分组中具体的分类。例如:买家信息可以拆分为他的浏览信息、收藏信息、购物车信息、下单信息。而下单信息又可以分为订单信息和物流信息
文章插图
(3)底层模型(物理模型)
从中间层模型细化而来,有时也称物理模型为关系表。如果要搭建好这一层,你需要进行如下两步操作:
第一步:确定数据粒度。
啥是“数据的粒度”?数据粒度:数据最小的单元和数据汇总的单元,粒度越小表示越细,粒度越大表示越粗。例如:分钟级别的数据粒度一定比月级别的数据粒度小。
????为啥要预估数据的粒度?好处是啥?
要回答好这个问题,首先要回忆一下上篇文章讲解的「3层6类」数据分层。数据分层的方式有很多,针对不同体量、不同业务需求的数据会有不同的设计架构。并且数据粒度的预估同时可以带来如下的好处:
- 多视角分析数据:可以通过不同的粒度对数据进行分析。
- 低粒度数据灵活:有了最小粒度的数据,可以定位到根本的原因
- 高粒度数据概括:对于高度概括的数据,可以对整体业务进行把控
- 未知数据需求:对于未来的各种预测场景,可以通过所搭建的各类数据建设去进行解决

文章插图
数据粒度的分档有哪些?
数据粒度的预估过程如下:对数仓中将来的数据行数和所需的DASD(直接存取存储设备)数进行粗略估算。分档可以按照如下进行分档:
- 少量数据:数据有10000行:啥粒度都可以,闭眼建粒度
- 中等数据:数据有10000000行:需要一个低粒度级别,例如:天和周比起来就是低粒度,秒和分钟比起来就是低粒度
- 大量数据:数据有100亿行:需要高粒度级+数据移到溢出存储器。
对一个已知的表,预估的方式如下:
- 一张表的总空间=每行空间的大小*行数*时间+索引数据的大小*时间
- 总空间=表1的空间+表2的空间+….+表N的空间每行空间的大小要分别从最大和最小考虑:
- 每行空间的大小 = [每行的最小估计值(下限),每行的最大估计值(上限)]行数的预估,同样需要需要预估下时间范围内的最大和最小值:
- 行数=[最小行数(下限),最大行数(上限)]
注意:
溢出存储器中的数据。一年内总行数超过100000000,需小心设计,可以把一部分数据转移到溢出存储器中,从而应对数据量过大对性能造成的影响
确定粒度级别。首先要靠常识和行业处理经验进行合理的推断,接着要考虑对数据仓库获取数据的各个不同的体系结构实体的需求进行预测
推荐阅读







- 人货匹配模型没搞懂?互联网行业都在讨论它
- 销售额|从AIPL到GROW,谈互联网大厂的营销分析模型
- 聊天记录|男子买苹果手机却收到模型机,商家不负责建议报警,又改口是旧机
- profile|2021运营人年度工作总结——常用模型篇
- 季节性|不会写模型代码?可以这么来做销量预估
- 模型|京东电器将推出带电品类数智化增长模型 12月29日正式发布
- 策略|从战略到执行:业务领先模型 BLM 战略篇「市场洞察」
- 一个操作帮你在京东省下一大笔钱!
- 度小满|登顶CLUE榜首,度小满“轩辕”刷新预训练模型纪录
- 销售|私域电商AIPL增长模型,打造销售转化闭环