那么百度翻译,是如何通过十年时间进阶到如此的呢?
百度翻译进化之路我们不妨先来简单回顾一下机器翻译的发展。
“机器翻译”这件事,早在1946年第一台计算机ENIAC诞生之后的一年,便由信息论先驱、美国科学家Warren Weaver提出:
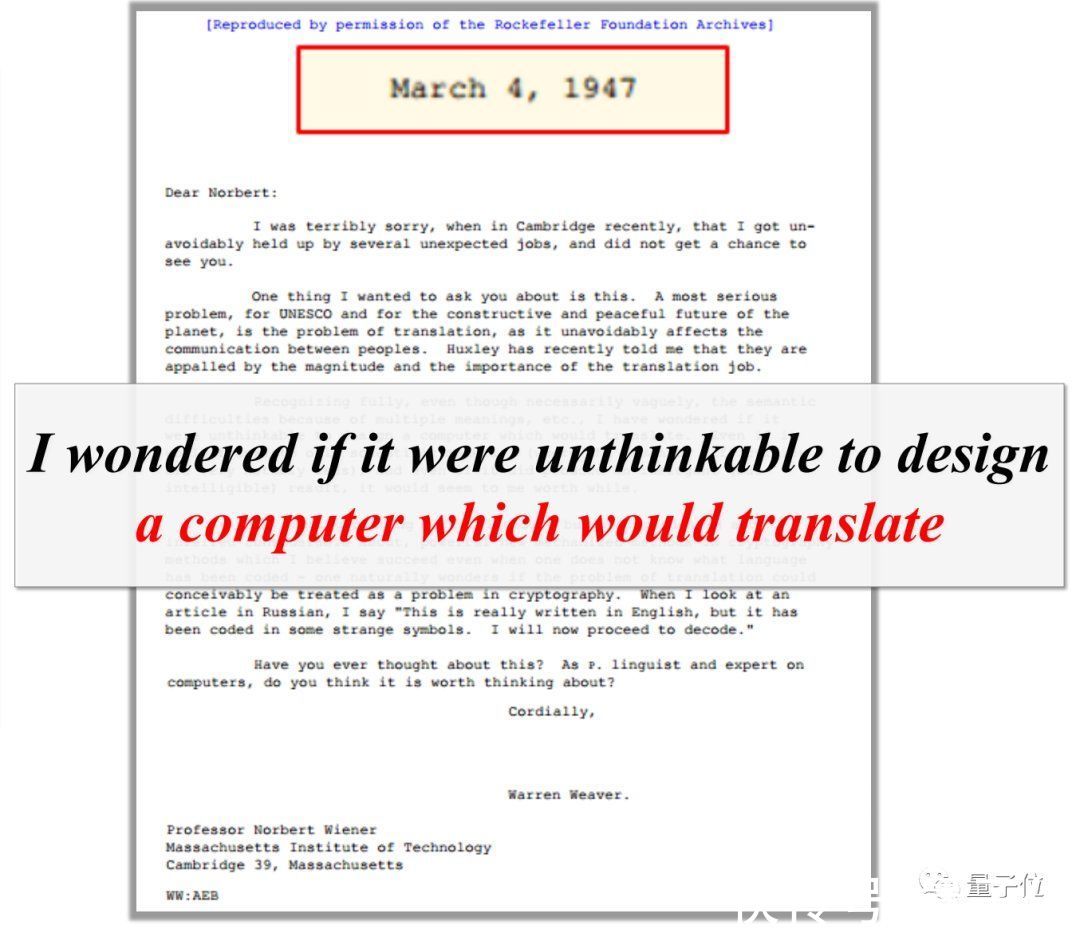
文章插图
而至此之后,机器翻译先是进入到了“基于规则方法”的时代。
这个方法本质上将专家的翻译知识采用规则形式写下来,然后采用软件的方式利用翻译规则来实现机器翻译过程。
但这种方法的缺点也是显而易见,那就是构建成本、维护成本过高,动辄还要将整个程序重写。
而到了上世纪80年代末90年代初,IBM提出了另一种机器翻译的方式——统计机器翻译,这便开启了机器翻译时代的第二个大门。
与基于规则的机器翻译不同,统计机器翻译不再需要从人工书写翻译规则,而是转换到了数据驱动的机器学习方法。
最大的优点在于机器可以按照人工定义的特征进行“自学”,而之前的基于规则方法,需要人类专家手把手的。
百度翻译上线之初,主要用的就是基于统计机器翻译的方法,同时研发了融合已有方法的多策略模型,以便应对互联网上复杂多样的翻译请求。
2010年百度翻译自建了研发团队,仅时隔一年,便上线了网页版。
但此时统计机器翻译已经诞生了20多年时间,其发展的瓶颈也是越发明显——在经历了基于短语的方法、基于句法的方法等一系列技术迭代之后,统计机器翻译逐渐遇到天花板,翻译质量难以进一步提升,尤其在长距离调序、译文流畅度方面。
即便摸石头过河,也要身先士卒到了2013年,一篇名为《Recurrent Continuous Translation Models》的研究横空出世。
而伴随着研究人员们所提出的新方法,机器翻译也就步入到了神经机器翻译 (NMT)时代。
虽然这种神经网络的方法确实是一种理想的“替代品”,但非常现实的问题也摆在百度翻译团队的面前。
那就是“无从参考”,建模的方式完全是新的,没有经验可循。
再则以当时的技术水平,通过神经网络模型来做机器翻译还是一件非常“伤资源”的事。
翻译效果提升的代价,就是消耗大量的计算资源,往往翻译一个句子就得花个十几秒的时间。
时间拉到2015年,即便是在这种大背景的情况下,百度翻译团队依旧做了一个“敢为人先”的决定:
上线基于神经网络的机器翻译。

文章插图
在技术方法上,百度翻译团队针对NMT所存在的缺点,将上一代统计机器翻译的特性融入了进来。
具体而言,就是将n-gram语言模型、短语表特征、长度特征等,融合到NMT模型中。
实验结果表明,这种“新旧结合”的方法,显著提升了NMT在中英互译方面翻译的性能。
而从立项到发布全球首个互联网神经网络机器翻译系统,百度翻译仅仅花了不到半年的时间。
这个节奏要比谷歌翻译提早了整整16个月的时间。
然而百度翻译却并不满足于此。
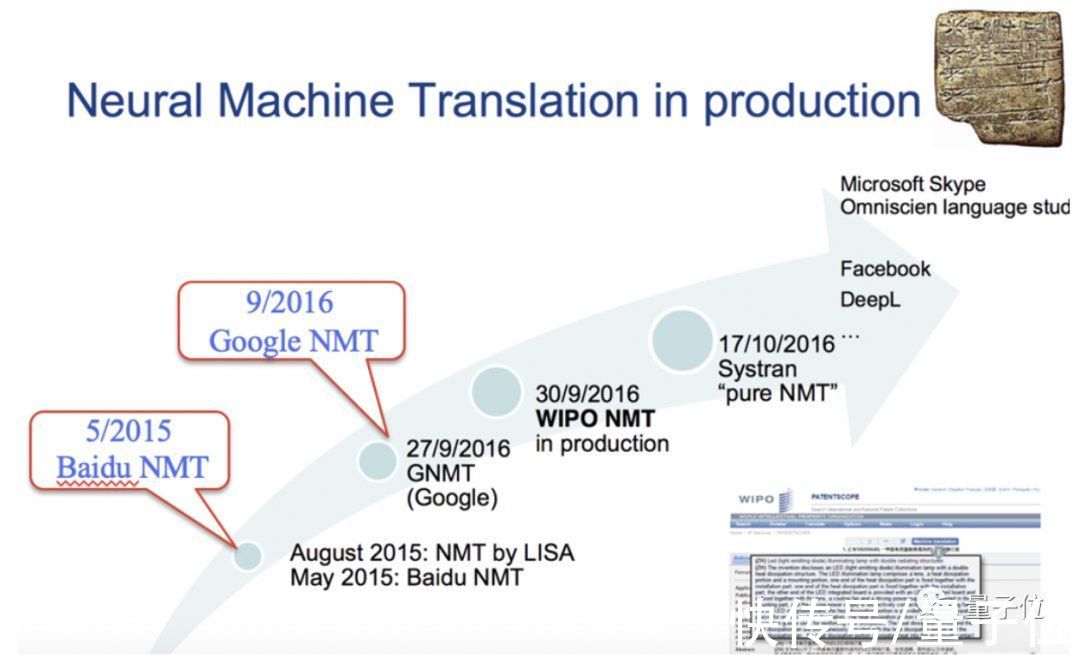
文章插图
△ Bruno Pouliquen,世界知识产权组织机器翻译负责人,MTSUMMIT-2017
还要做更多方向上的“领头羊”为了能够进一步翻译出更多的语言,百度翻译还提出了《Multi-Task Learning for Multiple Language Translation》。

文章插图
在这项研究中,百度翻译提出了共享编码器的多任务学习神经网络翻译模型,建立了基于神经网络的多语言翻译统一框架。
推荐阅读







- 知识店铺|百度文库:知识店铺开店量突破50万家,发布亿元优质内容激励计划
- 搜索引擎|百度起诉人工刷量平台我爱网干扰搜索引擎算法,获赔200万元
- 向海龙|百度前搜索总裁加入传音,担任移动互联总裁
- 向海龙|百度前搜索总裁向海龙加入传音
- 百度竟然出了一款良心产品?
- 百度知道|如何利用百度赚钱?分享十个普通人可以利用百度赚钱的方法
- 购物|逛超市也有“窍门”?逛了几十年,你知道如何在购物时省钱吗?
- 微信|视频号,拉开微信新十年序幕
- 电商|时隔十年,淘宝天猫"分久必合"?
- 百度|“跳转APP查看完整内容”谁在给用户使绊子?