选自arXiv
机器之心编译
为了探究 CV 领域的自监督学习是否会影响 NLP 领域 , 来自加州大学伯克利分校和 Facebook AI 研究院的研究者提出了一种结合语言监督和图像自监督的新框架 SLIP 。近来一些研究表明 , 在具有挑战性的视觉识别任务上 , 自监督预训练可以改善监督学习 。 CLIP 作为一种监督学习新方法 , 在各种基准测试中都表现出优异的性能 。
近日 , 为了探究对图像进行自监督学习的势头是否会进入语言监督领域 , 来自加州大学伯克利分校和 Facebook AI 研究院的研究者调查了 CLIP 形式的语言监督是否也受益于图像自监督 。 该研究注意到 , 将两种训练目标结合是否会让性能更强目前尚不清楚 , 但这两个目标都要求模型对有关图像的质量不同且相互矛盾的信息进行编码 , 因而会导致干扰 。

文章图片
论文地址:https://arxiv.org/abs/2112.12750v1
项目地址:https://github.com/facebookresearch/SLIP
为了探索这些问题 , 该研究提出了一种结合语言监督和自监督的多任务框架 SLIP(Self-supervision meet Language-Image Pre-training) , 并在 YFCC100M 的一个子集上预训练各种 SLIP 模型 , 又在三种不同的设置下评估了表征质量:零样本迁移、线性分类和端到端微调 。 除了一组 25 个分类基准之外 , 该研究还在 ImageNet 数据集上评估了下游任务的性能 。
该研究通过对不同模型大小、训练计划和预训练数据集进行实验进一步了验证了其发现 。 研究结果最终表明 , SLIP 在大多数评估测试中都显著提高了性能 , 这表明在语言监督背景下自监督具有普遍效用 。 此外 , 研究者更详细地分析了该方法的各个组成部分 , 例如预训练数据集和数据处理方法的选择 , 并讨论了此类方法的评估局限性 。
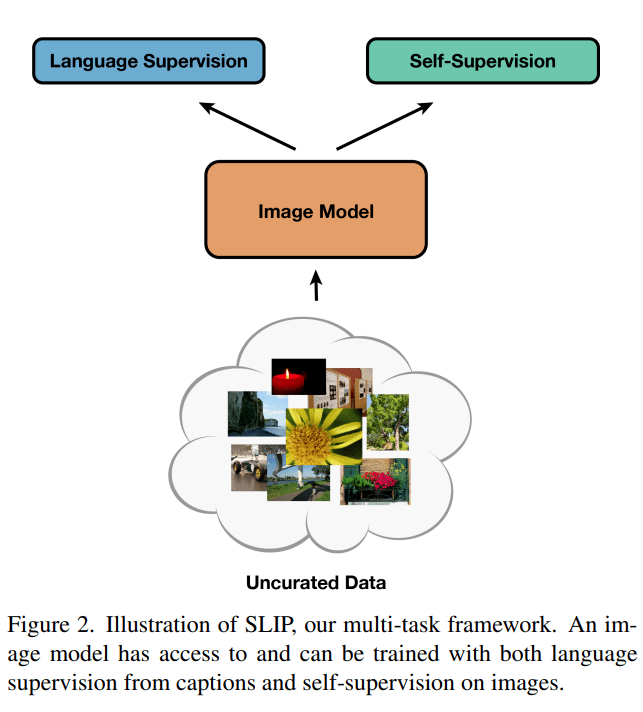
【训练|当自监督遇上语言-图像预训练,UC伯克利提出多任务框架SLIP】SLIP 框架
该研究提出了一种结合语言监督和图像自监督的框架 SLIP , 以学习没有类别标签的视觉表征 。 在预训练期间 , 为语言监督和图像自监督分支构建每个输入图像的单独视图 , 然后通过共享图像编码器反馈 。 训练过程中图像编码器学会以语义上有意义的方式表征视觉输入 。 然后该研究通过评估它们在下游任务中的效用来衡量这些学得表征的质量 。
文章图片
方法
下图算法 1 概述了用于自监督的 SLIP-SimCLR 。 在 SLIP 中的每次前向传递期间 , 所有图像都通过相同的编码器进行反馈 。 CLIP 和 SSL 目标是在相关嵌入上计算的 , 然后再汇总为单个标量损失 , 可以通过重新调整 SSL 目标来平衡这两个目标 。 该研究将 SLIP-SimCLR 简称为 SLIP 。

文章图片
SLIP 增加了图像的处理数量 , 这导致产生约 3 倍多的激活 , 因此会扩大模型的内存占用并减慢训练过程中的前向传递速度 。
改进的训练过程
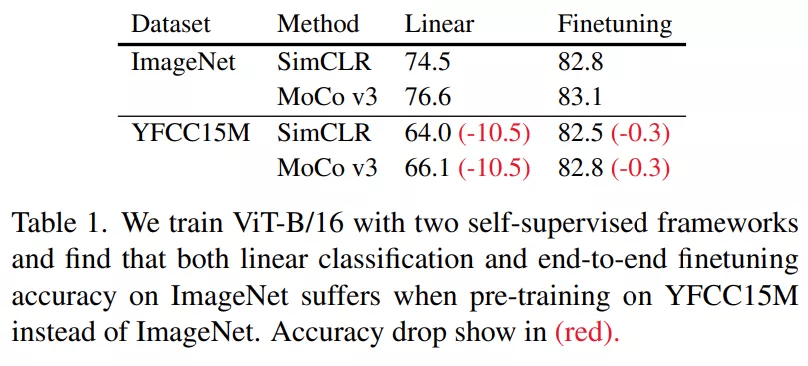
CLIP 的作者主要使用包含 400M 图像 - 文本对的大型私有数据集进行训练 , 这减少了正则化和数据增强的需求 。 在复现 CLIP 时 , 研究者发现了一些主要针对数据增强的简单调整 。 当在 YFCC15M 上进行预训练时 , 这些调整显著提高了性能 。
该研究对训练过程进行了改进 , 使用改进后的 ResNet-50 实现了 34.6% 的零样本迁移到 ImageNet , 超过了原始结果的 31.3% , 相比之下 , 另一项研究的 CLIP 复现在 ImageNet [29] 上实现了 32.7% 的准确率 。 该研究的实验主要关注视觉 Transformer 模型(ViT)系列 , 因为它们具有强大的扩展行为 [17] 。 并且该研究使用改进后的过程训练所有 ViT 模型 , 以便为该研究所提方法的评估比较设置强大的基线 。
评估实验
ImageNet 分类任务
该研究在三种不同的设置下评估了模型在 ImageNet 上的性能:零样本迁移、线性分类和端到端微调 。
- 零样本迁移任务在预训练后直接在分类基准上评估模型性能 , 而无需更新任何模型权重 。 通过简单地选择字幕嵌入与输入图像最接近的类 , 可以将使用对比语言监督训练的模型用作图像分类器;
- 线性分类 , 也称为线性探测 , 是一种用于评估无监督或自监督表征的标准评估方法 。 训练随机初始化的终极分类层 , 同时冻结所有其他模型权重;
- 最后 , 另一种评估表征质量的方法是 , 在对模型进行端到端微调时 , 评估预训练模型是否可以提高监督学习的性能 。
文章图片
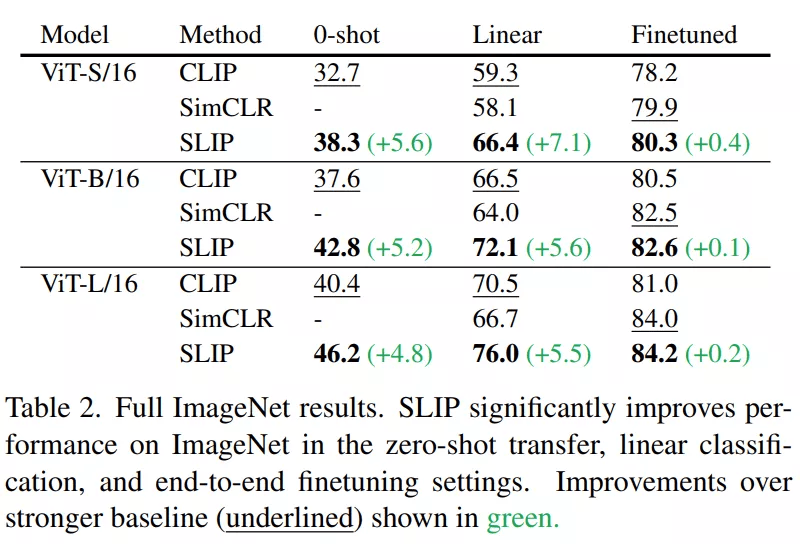
下表 2 提供了三种尺寸的 Vision Transformer 和所有三种 ImageNet 设置的 CLIP、SimCLR 和 SLIP 的评估结果 。 所有模型都在 YFCC15M 上训练了 25 个 epoch 。 该研究发现语言监督和图像自监督在 SLIP 中建设性地相互作用 , 单独提高了这两种方法的性能 。
文章图片
模型规模和计算量扩展
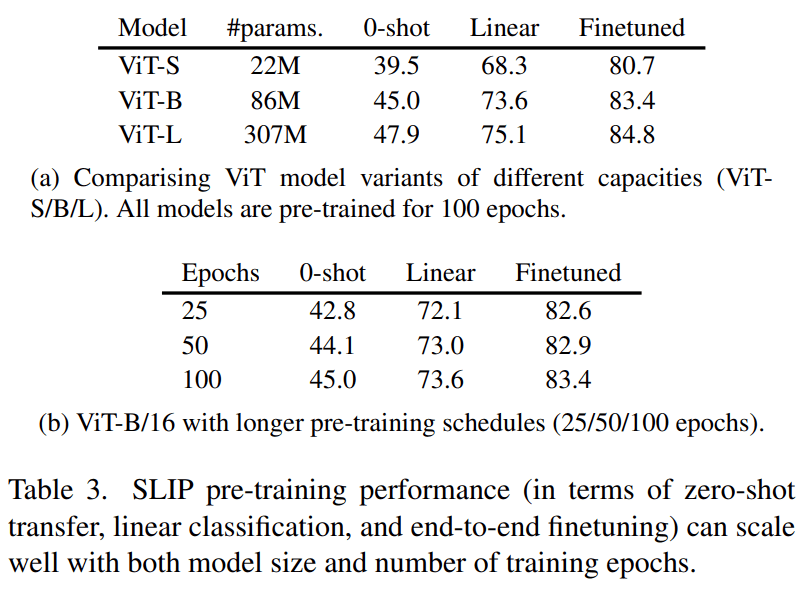
在这一部分 , 研究者探索了使用更大的计算量(训练更久)和更大的视觉模型之后 , SLIP 的表现有何变化 。 他们注意到 , YFCC15M 上的 100 个训练 epoch 对应着 ImageNet1K 上的 1200 个训练 epoch 。
下表 3 的结果表明 , 无论是增加训练时间 , 还是增大模型尺寸 , SLIP 都能实现良好的扩展 。
文章图片
其他基准
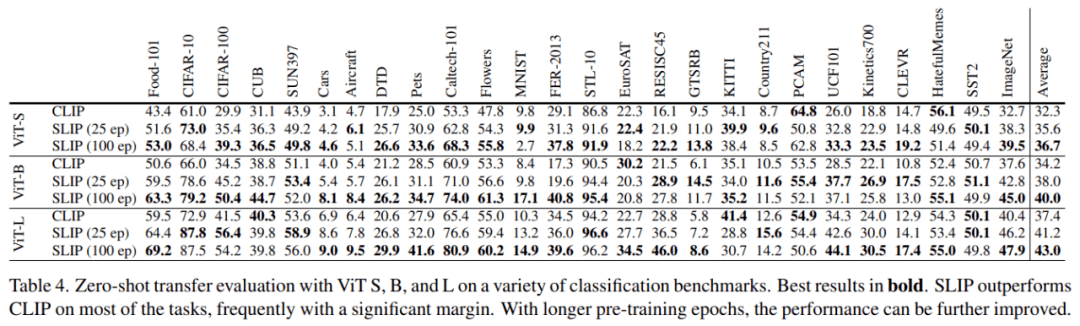
在下表 4 中 , 研究者评估了一组下游图像分类任务上的 zero-shot 迁移学习性能 。 这些数据集跨越许多不同的领域 , 包括日常场景(如交通标志)、专业领域(如医疗和卫星图像)、视频帧、带有或不带有视觉上下文的渲染文本等 。
在这些数据集上 , 我们看到 , 更大的模型和使用 SLIP 进行更长时间的训练通常可以提高 zero-shot 迁移学习的准确性 。
文章图片
其他预训练数据集
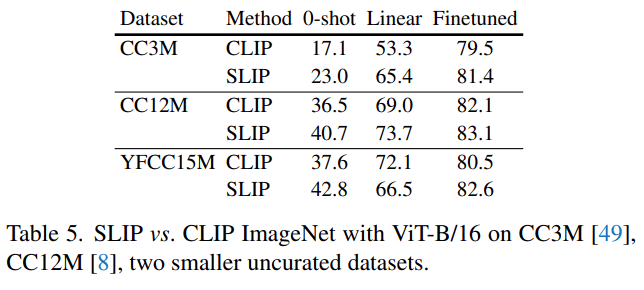
除了 YFCC15M 之外 , 研究者还用另外两个图像 - 文本数据集——CC12M 和 CC3M——进行了实验 。 如下表 5 所示 , 他们在 CC12M 和 CC3M 上同时使用 SLIP 和 CLIP 训练 ViT-B/16 , 并与他们之前在 YFCC15M 上得到的数据进行比较 。 在所有的 ImageNet 评估设置中 , SLIP 都比 CLIP 有改进的余地 。 值得注意的是 , 在 CC12M 而不是 YCC15M 上预训练 SLIP 会产生较低的 zero-shot 准确率 , 但实际上会带来较高的线性和微调性能 。 CLIP 让人看到了更惊艳的 1.6% 的微调性能提升 。
文章图片
其他自监督框架
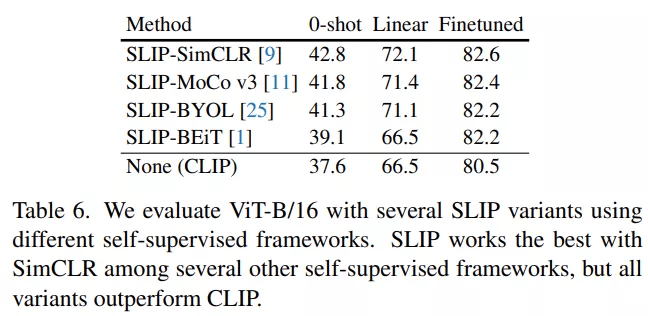
作者在论文中提到 , SLIP 允许使用许多不同的自监督方法 。 他们用 SimCLR 的不同替代方法——MoCo v3、BYOL 和 BeiT 在 ViT-B/16 上进行了几次实验 。
下表 6 显示 , 三种替代方法的表现都比不上 SLIP-SimCLR 。 最令人惊讶的结果是 , 尽管 BEiT 是这里测试的最强的自监督方法 , 但 SLIP-BEiT 的表现最差 。 这可能是由于预训练和部署阶段之间的输入差异较大 。 尽管如此 , 所有这些次优的 SLIP 变体仍然比 CLIP 性能要高 。
文章图片
推荐阅读







- 社交|Meta监督委员会称Facebook需要改变其人肉搜索规则
- IT|揭秘中国首金背后训练“神器”:冠军从这里“吹”出来
- 技术|CA 训练营|MLOps in Action
- 时代|用大数据助力军事训练
- 训练|擅长爬山的机器狗登Science,比人类徒步速度快4分钟
- 商汤|亚洲最大超算中心临港投运,可完成10000亿参数模型训练
- 新闻网|复旦大学研发智能冰上运动训练分析系统 助力冬奥健儿训练
- 教练|专家研发智能冰上运动训练分析系统 智能教练赋能训练
- 训练室|湖南高铁职院:指尖跳跃成就技能梦想
- 最新消息|中消协:今年将围绕新能源汽车、网游、校外培训等领域开展监督活动