模型|深入了解 Azure 机器学习的工作原理
关注我们
(本文阅读所需 4 分钟)
通过阅读本文 , 您将会了解到 Azure 机器学习的架构和概念 , 并且深入了解一些组件 , 以及它们如何协同来协助构建、部署和维护机器学习模型的过程 。
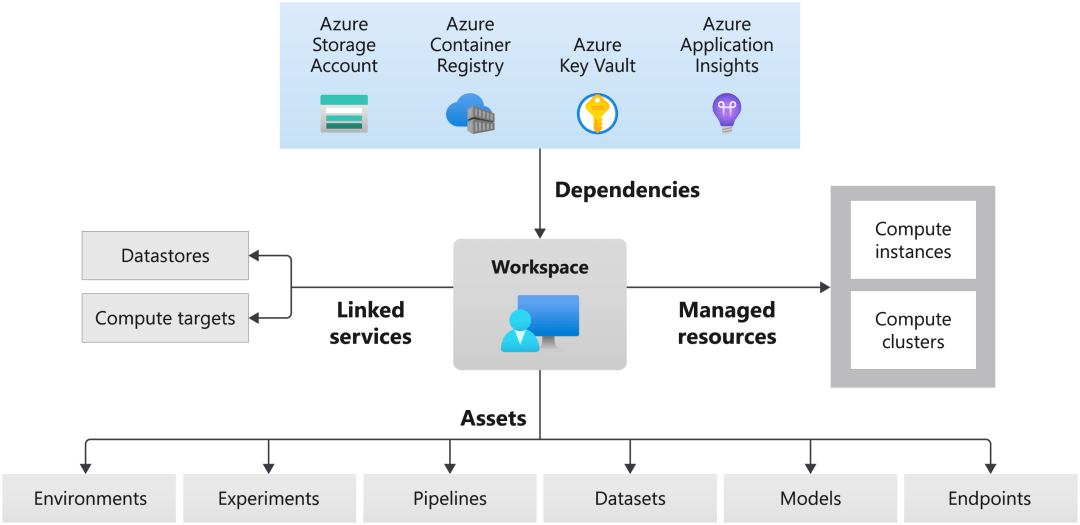
工作区
机器学习工作区是 Azure 机器学习的 top-level 资源 。 工作区可集中用于:
- 管理用于训练和部署模型的资源 , 例如:计算
- 存储使用 Azure 机器学习时创建的资产 , 包括:环境、实验、管道、数据集、模型、端点等等
文章图片
计算
计算目标是用于运行训练脚本或托管服务部署的任何一台机器或一组机器 。 您可以使用本地计算机或远程计算资源作为计算目标 。 您可以使用计算目标在本地机器上训练 , 然后扩展到云端 , 这个过程中无需更改训练脚本 。
Azure 机器学习引入了2个为机器学习任务配置的虚拟机 (VM) , 它们是完全托管且基于云的:
- 计算实例: 是一个 VM , 其中包括为机器学习安装的多个工具和环境 。 计算实例的主要用途是用于您的开发工作站 。 您无需设置即可开始运行示例 notebook 。 计算实例也可以用作训练和推理作业的计算目标 。
- 计算集群: 是具有多节点扩展能力的虚拟机集群 。 计算集群更适合大型作业和生产的计算目标 。 提交作业时 , 集群会自动扩展 。 它用作训练计算目标或用于开发/测试部署 。
Azure 机器学习数据集使您可以更轻松地访问和处理数据 。 通过创建数据集 , 您可以创建对数据源位置的引用及其元数据的副本 。 由于数据保留在其现有位置 , 因此您不会产生额外的存储成本 , 也不会面临数据源完整性的风险 。
数据存储将连接信息(例如您的订阅 ID 和 token 授权)存储在与工作区关联的 Key Vault 中 , 因此您可以安全地访问您的存储 , 而无需在脚本中对其进行 hard code 。
环境
环境是对机器学习模型进行训练或评分的环境的封装 。 环境指定了围绕训练和评分脚本的 Python packages、环境变量和软件设置 。
实验
实验是来自指定脚本的许多运行的分组 。 它始终属于工作区 。 当您提交运行时的时候 , 需要提供一个实验名称 。 运行信息存储在该实验下 。 如果您提交实验时该名称不存在 , 则系统会自动创建一个新实验 。
文章图片
模型
最简单的模型是一段接受输入并产生输出的代码 。 创建机器学习模型涉及选择算法、为其提供数据和调整超参数 。 训练是一个生成训练模型的迭代过程 , 它封装了模型在训练过程中学到的东西 。
您可以引入在 Azure 机器学习之外训练的模型 , 也可以通过向 Azure 机器学习中的计算目标提交实验运行来训练模型 。 有了模型之后就可以在工作区中注册模型 。
【模型|深入了解 Azure 机器学习的工作原理】Azure 机器学习与框架无关 。 您可以使用任何流行的机器学习框架来创建模型 , 例如 Scikit-learn、XGBoost、PyTorch、TensorFlow 和 Chainer 。
部署
将已注册的模型部署为服务端点需要以下组件:
- 环境: 此环境封装了运行模型进行推理所需的依赖项
- 评分: 该脚本接受请求 , 使用模型对请求进行评分 , 并返回结果
- 推理配置: 推理配置指定将模型作为服务运行所需的环境、entry 和其他组件
▌Azure 机器学习 CLI
Azure 机器学习 CLI 是Azure CLI 的扩展 , Azure 平台的跨平台命令行界面 。 此扩展提供了自动化机器学习活动的命令 。
▌机器学习管道
您可以使用机器学习管道来创建和管理将机器学习阶段拼接在一起的工作流 。 例如 , 一个管道可能包括数据准备、模型训练、模型部署和推理/评分阶段 。 每个阶段可以包含多个步骤 , 每个步骤都可以在各种计算目标中自动运行 。
此外 , 管道的步骤是可重复用的 , 如果这些步骤的输出没有改变 , 可以在不重新运行之前步骤的情况下运行 。 例如 , 如果数据没有更改 , 您可以重新训练模型而无需重新运行繁琐的数据准备步骤 。 有了管道 , 数据科学家在机器学习工作流的不同环节工作时进行协作 。
▌监控和日志记录
Azure 机器学习提供以下监控和日志记录功能:
- 对于数据科学家 , 您可以监控您的实验并记录训练运行的信息
- 对于管理员 , 您可以使用 Azure Monitor 监控有关工作区、相关 Azure 资源以及资源创建和删除等事件的信息
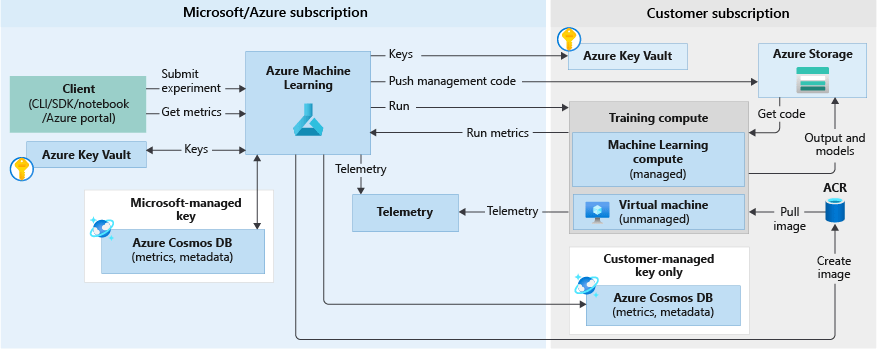
Azure 机器学习的工作原理
推荐阅读







- 研究院|AI大模型:为产业智能化升级“开闸放电”
- 趋势|[原]“通用大模型”趋势下,AI未来当如何?
- 动力学|【研发】Phoenix WinNonlin,你了解多少?
- Adobe|Adobe深入NFT领域 Behance正添加对Polygon区块链的支持
- 模型|中考数学图形旋转难?用5个模型就能搞定
- 手表|女神节最值得入手的数码好物:OPPO领衔,这些性价比产品了解下
- 分割|打打字就能指挥算法视频抠图,Transformer掌握跨模态新技能,精度优于现有模型丨CVPR 2022
- 示范|发改委:提高超大型数据中心能效指标,深入开展5G网络节能示范
- 模型|一举打败16个同类模型,视频超分比赛冠军算法入选CVPR 2022,来自商汤&南洋理工大学
- 模型|机器学习理论基础到底有多可靠?