机器之心专栏
追一科技
2021 年以来 , 中文预训练语言模型进入井喷式发展的阶段 , 相继出现了百亿和千亿参数规模的大模型 , 中文 NLP 社区似乎也迈入了「练大模型」时代 。 追一科技在大型预训练模型上都做了什么?目前又取得了哪些成果呢?本文将详细剖析这家公司大型 NLP 预训练模型的发展概况 。在实际场景中 , 许多 AI 业务的冷启动往往会面临数据量不足 , 启动效果差等问题 , 这导致在引入智能机器人时需要耗费大量的前期人力标注 , 增加用户的使用成本和项目上线的初期投入 。 大型预训练模型作为当前 NLP 技术的基底 , 不仅能够大幅提高模型在下游不同业务应用场景的效果 , 还能降低标注数据的需求量 , 降低业务场景冷启动的成本投入 。
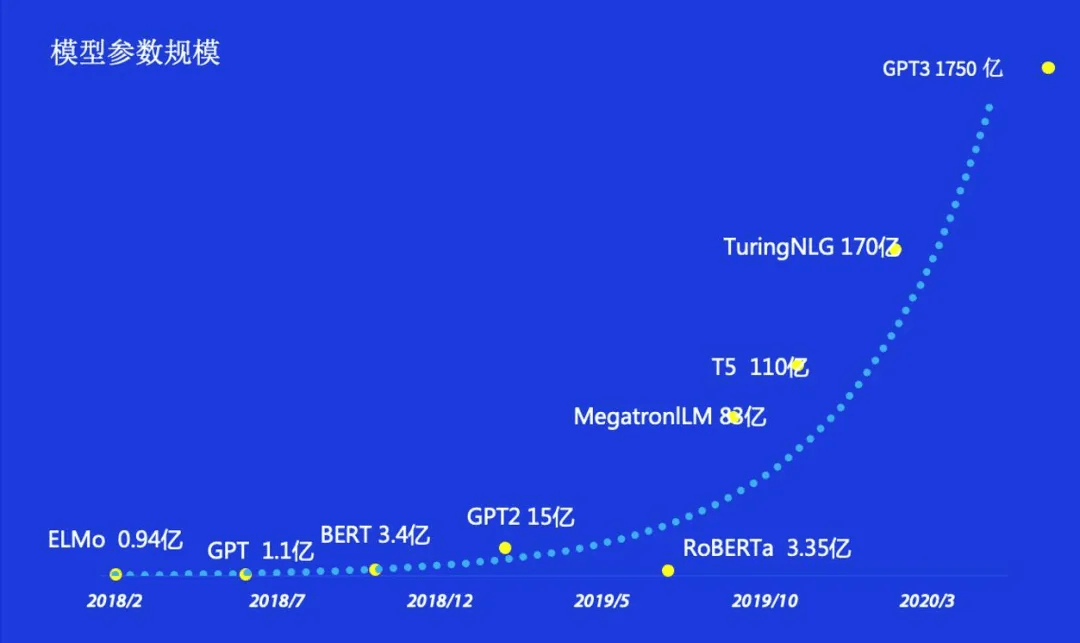
自从 2018 年 BERT 预训练模型被提出并刷新各大 NLP 任务榜单后 , 基于深度学习的 NLP 算法就逐渐过渡到采用大型预训练模型来对下游不同任务进行微调的范式上 。 这种方式借助大型的模型以及大规模的预训练语料 , 让模型对自然语言的理解能力提升了一个档次 , 从而也大幅提高了 NLP 模型在下游任务上的表现 。
所谓的大型预训练模型 , 是指在大量的预训练数据上采用体积非常大的模型进行训练而得到的 。 在 NLP 领域中 , 预训练步骤采用的大多是语言模型任务这一无监督的方式 , 因此通常不需要对数据进行标注 , 从而在预训练时便可以方便地获得大量的无监督数据 。 随着模型体量和预训练数据量的不断增大 , 模型在下游任务上的效果也不断提高 , 从 2018 年至今 , 这种大型的预训练模型在体量和预训练数据量上一直在持续增长 。
文章图片
追一科技成立 5 年来 , 始终专注于 NLP 领域的前沿技术创新与最佳方法实践 , 在大型预训练模型的研究与研发上一直持续进行投入 。 我们将研发力量集中在通用预训练模型以及业务预训练模型两个大方向上 。
通用预训练模型
通用预训练模型指的是在公开语料上进行的预训练模型 。 因为是在大量的非限定性领域语料上进行训练 , 因此对下游任务的领域没有严格的限制 , 可以被用在不同的领域和任务中 。 追一科技在通用预训练模型上进行了持续的投入 , 主要集中在三个方向上的研究:
- 中文还未覆盖的各类模型:主要目的在于研究模型在中文上的表现 , 并加以改进以进一步提升效果;
- 针对自身业务特点进行的通用预训练模型:主要目的在于采用不同的语料构建方式与模型结构、训练任务的设计 , 以便模型在业务领域中的下游任务能够有更好的表现;
- 针对特定下游任务形式进行优化的预训练模型:虽然通用型预训练模型可以在不同的下游任务上直接使用 , 但在预训练步骤中如果针对下游任务进行特定的设计 , 可以更好地提升下游任务的表现 。
文章图片
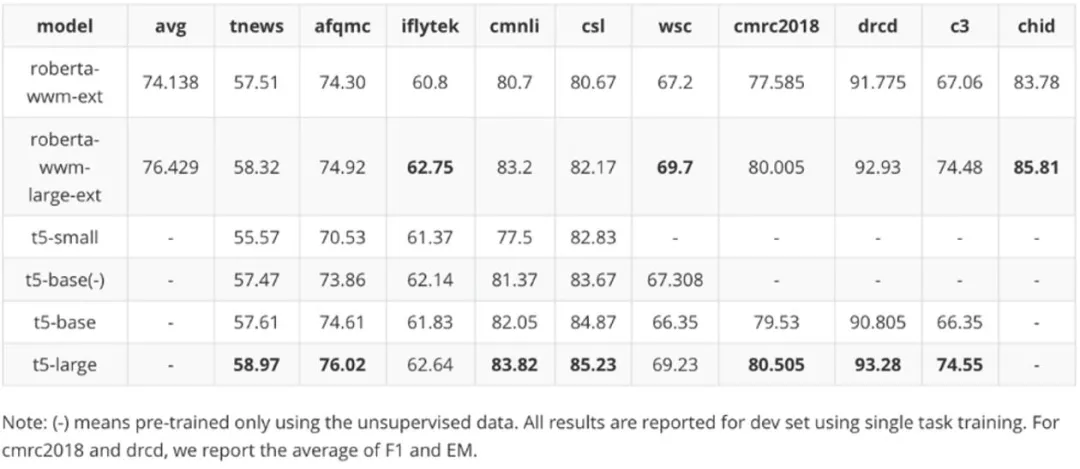
我们针对 T5 训练了大中小三个版本 , 利用我们收集的数据 , 设计了「有监督数据」与「有监督 + 无监督数据混训」两种方式 , T5 模型共 7 个版本 。 针对 BART 模型 , 我们训练了小(small)与中(base)共两个版本 。 针对上面两种模型 , 其中小版本的模型(small)训练时长为 2 周、中型模型(base)训练时长为 3 周 , 大版本(large)训练时长为 4 周 。
除了按照原版 T5 模型进行训练外 , 我们针对模型结构进行了相应的调整 (attention 增强版本) 以提升模型的表现 。 同时 , 我们在当时的测试榜单 Chinese GLUE 的 10 个不同 NLP 任务数据集上测试了中文 T5 模型 , 并与当时最优的中文 RoBERTa-wwm-large 进行了比较 。
文章图片
除了上述的大型预训练模型以外 , 我们还训练了一些小型的模型与一些针对特定下游任务使用的预训练模型 。 例如在下表中的 RoBERTa Tiny、Small 版本和 BERT Tiny、Small 版本 , 对应的是 RoBERTa 与 BERT 的微型版本和小型版本 , 而 RoBERTa + 则是对模型中的 attention 部分进行了修改以增强模型的效果 。
这些小型的模型体积较小 , 可以在资源较少的情况下使用 , 我们将这些模型进行开源以提供给研究者学习使用 , 共同促进中文 NLP 社区的发展 。
SimBERT
2020-2021 年 , 我们又相继开源了 SimBERT、WoBERT 以及 RoFormer 三个大型预训练模型 。 SimBERT 采用的是与 BERT 相同的模型结构 , 但在训练时使用了不同的任务 。 我们采用抓取的开源数据构建相似句子对 , 并采用生成与匹配两种方式进行多任务训练 , 目的是让模型学会自动生成同义句 , 具体的方式如下图:

文章图片
SimBERT 的生成任务构建方式采用 UniLM 的训练方式 , 不同点在于训练时单个样本由近义句子对构成 , 假设 SENT_a 和 SENT_b 是一组近义句 , 那么在同一个批次(batch)中 , 将 [CLS] SENT_a [SEP] SENT_b [SEP] 和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练 , 作为序列到序列(sequence-to-sequence)式的近义句生成任务 。
而在生成任务的基础之上 , 我们加入了「分类」任务来增强模型对近义句的学习 。 具体的构建方式如下 , 设每个批次中有 b 个样本 , 而模型最后一层 [CLS] 的特征维度为 h, 那么对于一个批次的样本 , 我们将每个样本的 [CLS] 特征取出可以得到 H∈R^(b×h)的特征 , 然后按行进行归一化得到 H'然后按如下方式一个批次的计算损失:

文章图片
其中 S_cos 为同一批次样本相互之间的余弦距离 , s 为一个标量超参数(我们在训练时设为 30) , ⊙为元素对应相乘 , M_mask 为对角矩阵掩码 , 用来屏蔽样本与自身的距离 。 P∈R^(b×b)且 P_i,j 代表矩阵 P 的第 i 行的第 j 个元素 , 而其中 j 为同一批次中与 i 互为相似句的样本的序号 。 这个损失实际上是在同一个批次中拉近两个互为相似句的样本的距离 , 采用这样的方式可以让模型更加明确的学习相似句之间的特征关系 。 生成同义句这一任务形式有广泛的运用空间 , 其中最典型的运用是可以用来扩充文本分类任务的训练数据 。
WoBERT
WoBERT 同样也是采用 BERT 的结构 , 但区别是在训练中加入的词 , 这是一个专门为生成式下游任务训练的模型 。 中文 BERT 模型原本的词表只包含字(词会被拆解成字进行编码) , 而采用以字为编码的模型在用作生成的时候也是以字为粒度来进行生成的 。
但这种以字为粒度的生成方式有两个主要的弊端 , 第一是对于相同长度的句子 , 字粒度式的生成比词粒度式的生成需要更长的序列 , 这导致生成的时间过长 , 并且过长的生成序列还容易造成在解码阶段带来的累积误差 。 第二个问题是中文的词很多时候是固定搭配 , 拆为字来进行生成增加了模型生成的难度 。
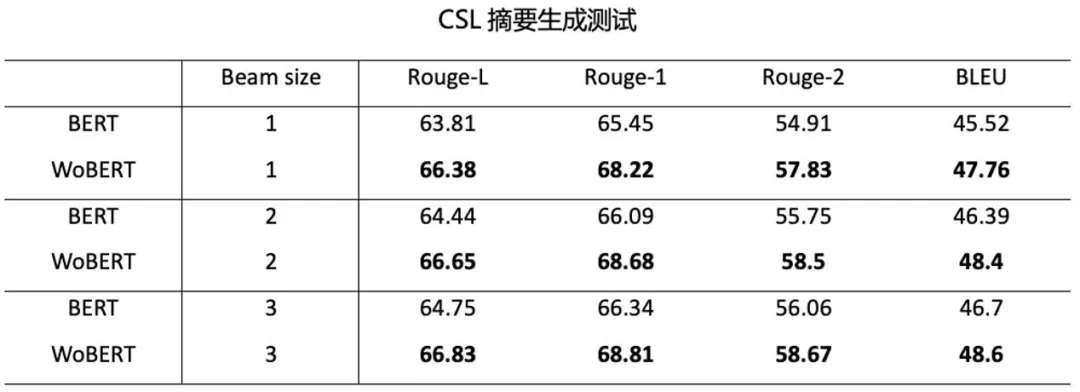
基于以上的原因 , 我们在保留原本 BERT 词表中的字的基础上 , 新增了一定数量的词 , 并进行再训练 。 我们对比了 WoBERT 与常规的 BERT 在生成式任务上的效果 , 其结果也表明以词粒度进行生成能取得更好的效果 。
文章图片
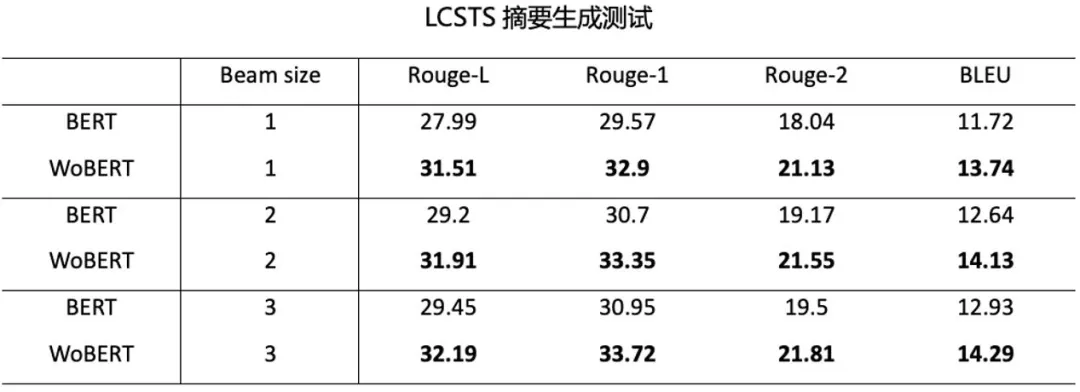
文章图片
目前 , 我们在 WoBERT 的基础上进一步地增强了词表的构建方式 , 训练了增强版模型 WoBERT+ , 目前正在进行内部测评 。
结果表明 , 在文本分类任务上 , WoBERT + 比 WoBERT 有更加优秀的表现 。

文章图片
T5 PEGASUS
T5 PEGASUS 是我们今年开源的基于 T5 模型、采用文本摘要式任务进行预训练的大型模型 。 我们采用「伪摘要」的方式来构建数据 , 并进行摘要生成的方式进行训练 。
具体来说 , 假设一个文档有 n 个句子 , 我们从中挑出大约 n/4 个句子(可以不连续) , 使得这 n/4 个句子拼起来的文本 , 跟剩下的 3n/4 个句子拼起来的文本 , 最长公共子序列尽可能长 。 然后我们将 3n/4 个句子拼起来的文本视为原文 , n/4 个句子拼起来的文本视为摘要 , 构成了一个「(原文, 摘要) 」的伪摘要数据对 , 并进行序列生成的训练 。 选取句子的方式采用如下的贪心算法进行:
- 从全部的 n 的句子中找出 1 句 , 使得其与剩下的 n-1 句有最大公共子序列;
- 设已经找出 k 个句子 , 我们从剩下的 n-k 个句子中找出第 k+1 个句子 , 使得组成的所有 k+1 个句子与剩下的 n-k-1 个句子有最大公共子序列;
- 重复执行第二步 , 直到找出的句子的总长度满足一定的设定要求 。

文章图片
经过预训练后 , 我们测试了 T5 PEGASUS 模型在生成式摘要任务上的效果 , 结果表明经过专门的生成式预训练 , T5 PEGASUS 的表现确实能够超过基于语言模型式预训练的模型:
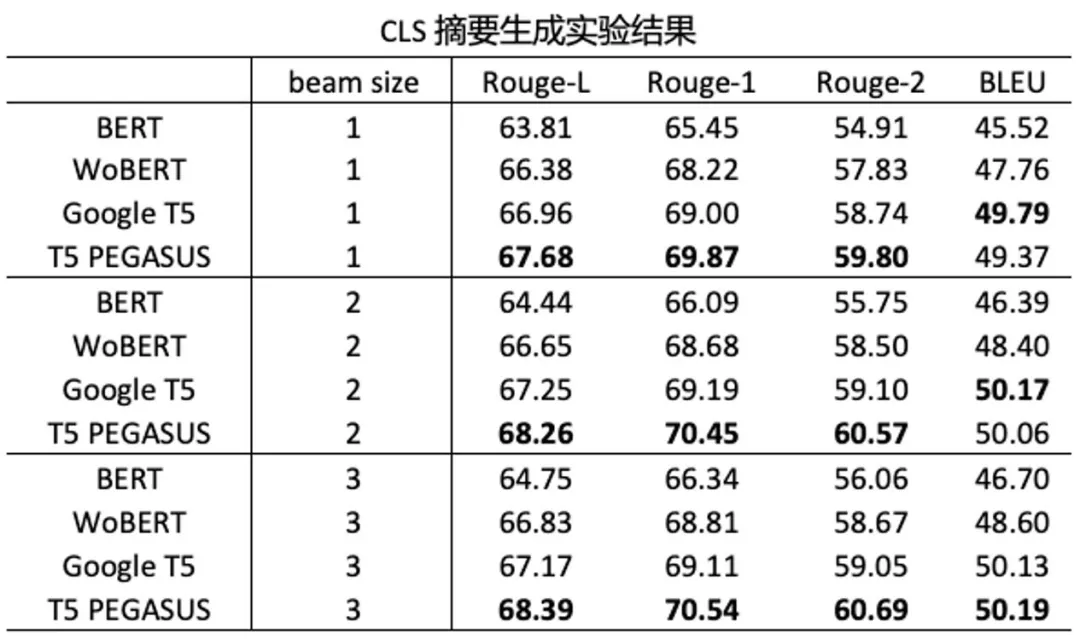
文章图片
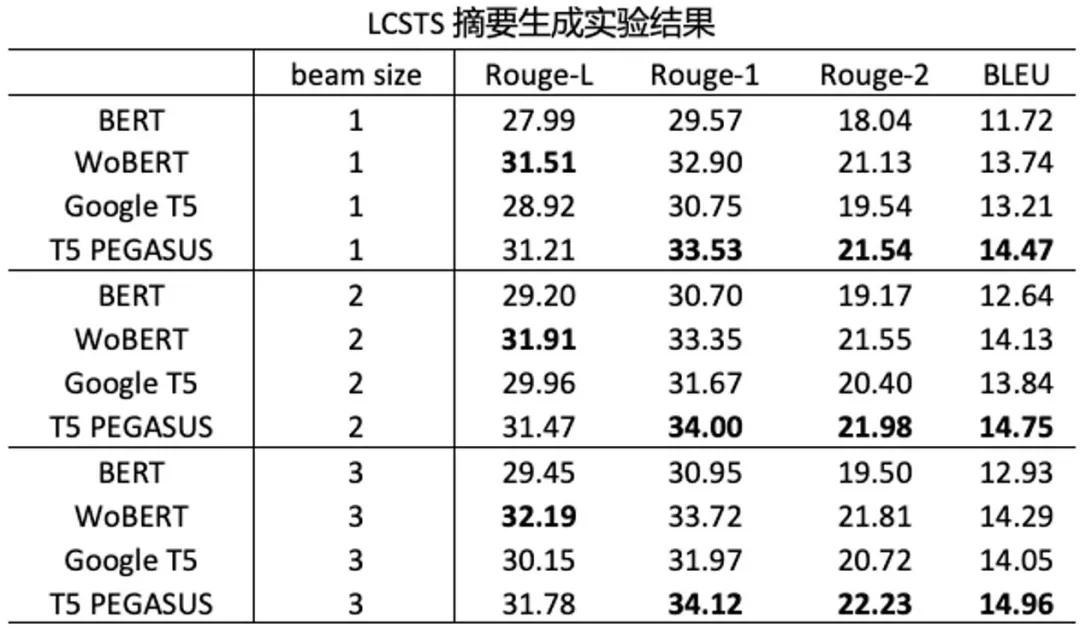
文章图片
同时 , T5 PEGASUS 还具有出色的小样本学习能力 , 也就是说 , 在只有少量标注数据的情况下 , 同样能获得不错的摘要生成效果 。
【模型|从通用型到业务型,中文大模型时代下NLP预训练的创新与实践】
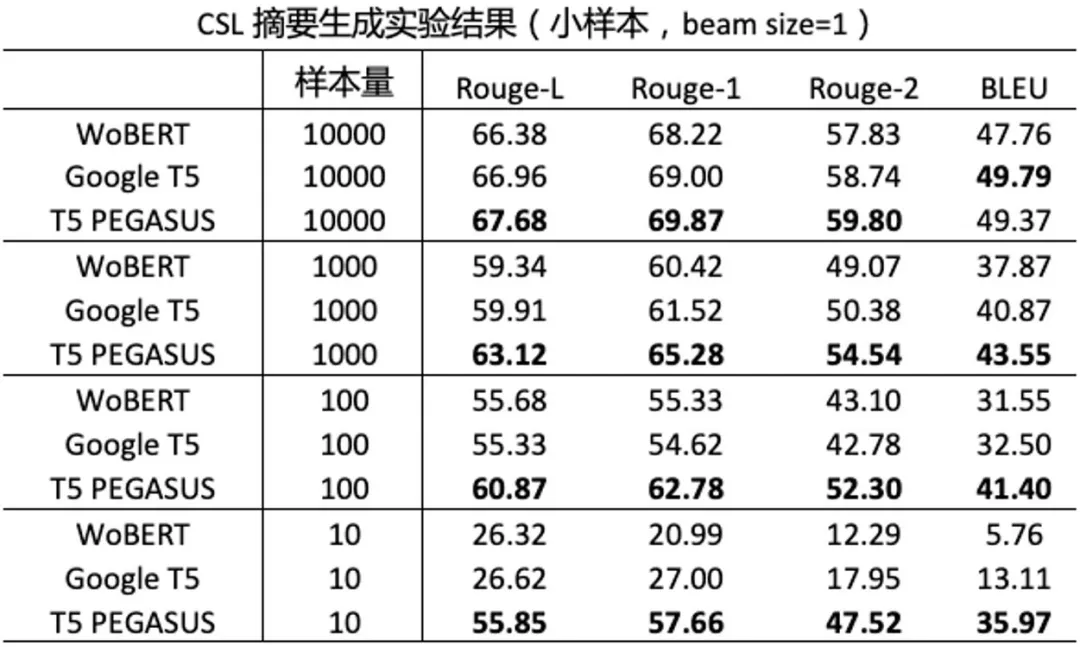
文章图片
从结果上可以看出 , 当样本量越少时 , T5 PEGASUS 的优势越明显 。
RoFormer
目前基于 Transformer 结构的预训练模型在位置编码上大多可以分为函数式编码、绝对位置编码以及相对位置编码三类 。 函数式编码的代表则是原版 Transformer 采用的 Sinusoidal 位置编码;绝对位置编码的代表则是 BERT 采用的每个位置设置一个向量 , 并通过预训练参与学习的位置编码方式;相对位置编码的代表则是在 XLNET 与 T5 中采用的编码方式 。
总体来说 , 绝对位置编码比函数式编码有相对较好的效果 , 但由于是预先定好总的编码长度 , 因此在下游任务上使用时对序列长度有限制 , 而相对位置编码则可以解决这个问题 。
除此以外 , 学界还提出了一些较为特殊的位置编码方式 , 如 Encoding word order in complex embeddings 中提出的采用复数形式去编码位置 。 我们同样借助复数的思路 , 提出采用复数运算的法则可以得出将绝对位置与相对位置相结合的编码方式 , 但同时模型依然保持在实数范围内运算的方法 。 通常认为在文本任务中 , 词的相对位置信息是最有作用的 , 因此通常来说任务位置编码的体现主要是在进行 Attention 计算时 , 考虑如下的 Attention 计算:

文章图片
其中 V = [V_1…, V_M]当采用绝对位置编码时 , 位置信息的计算会体现在内积
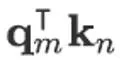
文章图片
部分以及 V_n 中 。 而在一些相对位置编码方式中 , V_n 的位置信息会被舍弃 , 我们也采用这种思路 , 只考虑在内积部分引入位置信息来体现位置 m 与位置 n 的关系 。 简单起见我们先假设 q_m,k_n 为二维向量的情况 , 那么其内积的运算过程可以从复数的角度来看:
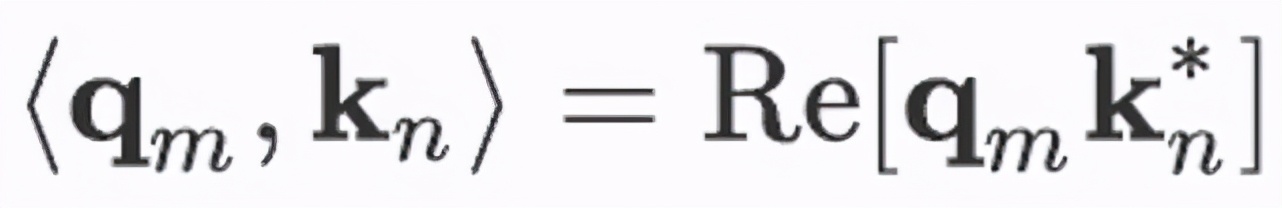
文章图片
其中 Re [?]为取实部 , k_n^* 为 k_n 的共轭复数 。 那么我们就可以在这里分别加入依赖 m,n 的绝对位置信息 , 即将其变为, 这样以来上述的内积则变为:
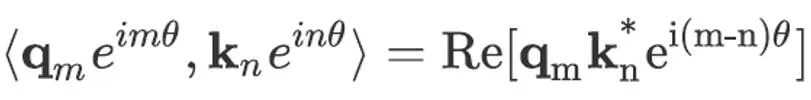
文章图片
从上式的右边可以看到 , 加入的绝对位置信息在内积后变为了只依赖其相对值 m-n 。 虽然整个过程是从复数的视角来进行推导的 , 但实际上在实现的过程中并不需要引入复数的神经网络 。 假设某个位置 n 上的二元向量为[x,y] , 那么对其乘上
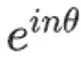
文章图片
的过程可以根据欧拉公式写为:

文章图片
即将 [x,y] 通过引入 "sin" nθ,"cos" nθ , 用如下的形式加入位置信息:
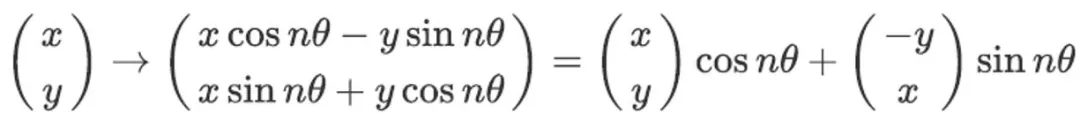
文章图片
上述式子表明在进行 Attention 运算之前按照其方式加入依赖绝对位置的信息 , 通过内积运算后得到的结果反映出了相对位置 。 而上述的推导是在二维向量上进行的 , 通常在 Transformer 中的特征维度都很大 , 但我们可以将所有特征维度看作每两个元素为一组的多组二维向量 , 并在每组上采用不同的 θ即可 , 具体的流程如下图:
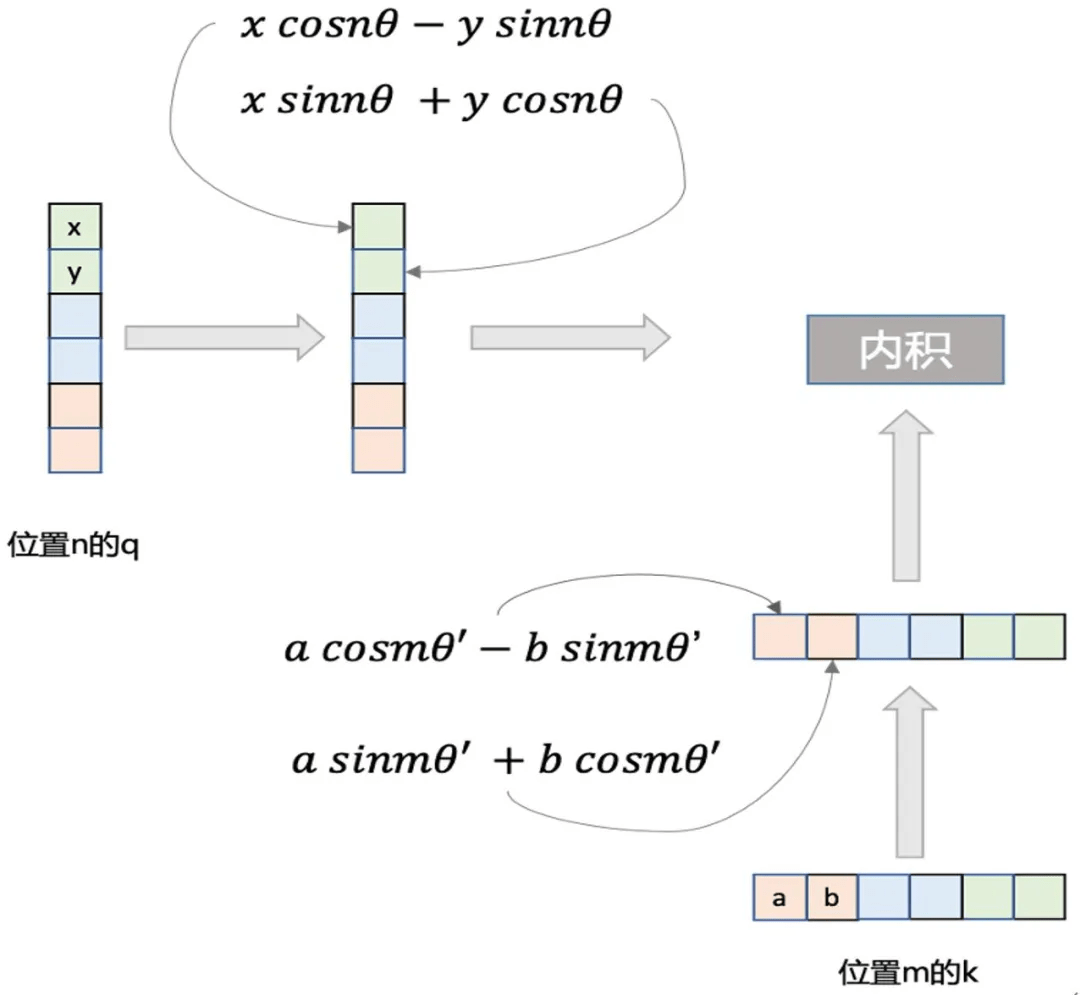
文章图片
由于其特殊的位置编码方式 , RoFormer 可以编码任意长度的文本 。 我们在 Call2019-SCM 任务上对比了 RoFormer 与 BERT 以及 WoBERT 的效果:
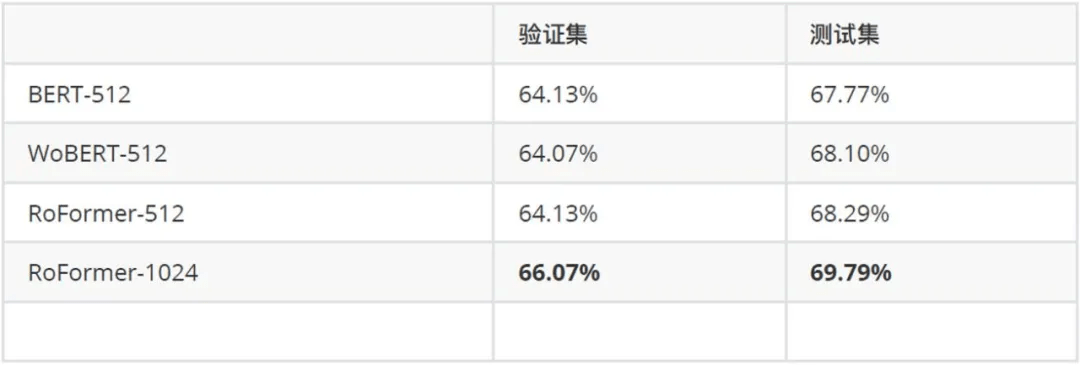
文章图片
其中 , 后面的参数是微调时截断的最大序列长度 , 可以看到 RoFormer 确实能较好地处理长文本语义 。 未来我们还将对 RoFormer 做进一步的研究实验 , 在更多的场景中测试其效果 。
业务型预训练模型
业务型预训练模型是针对追一科技一些列产品形式专门设计的大型预训练模型 。 在实际的业务场景中 , 往往会面数据量少、数据质量低、行业专有概念多以及语义粒度细等一系列问题 。 而通用的大型预训练模型 , 由于其非限定语料以及语言模型任务的训练方式 , 虽然可以在开放领域上的大多下游任务中有着不错的平均表现 , 但在特定的专业领域和特定的任务上的表现却并不是最优的 。
针对这一情况 , 我们希望在业务中使用的预训练模型能够在拥有大型通用预训练模型的整体能力外 , 还能针对领域专业词汇理解、数据效率、模型鲁棒性等方面有专门的优化与提升 。
我们将用在业务中的大型预训练模型命名为 ZOne(Zero-shot Language Encoder) , 它在业务场景中的表现不仅比开源的通用大型预训练模型有更好的效果 , 有更高的数据利用效率 , 同时还具有零样本的能力(即在没有相关业务标注数据的情况下进行语义理解) 。
ZOne 以我们的通用预训练模型为基础 , 在预训练阶段除了使用公开数据外 , 还加入了追一科技多年积累的行业数据 , 并融合了 SimBERT 近义句建模与 WoBERT 融入词粒度的特点 。 除此以外 , ZOne 还结合下游任务形式设计了多个损失函数进行多任务联合训练 。
我们在 8 个不同行业的业务数据上对比了 ZOne 模型与 BERT、RoBERTa 等的大型预训练模型的效果:

文章图片
上表以谷歌的开源中文 BERT 为基准 , 对比了其它开源的中文模型以及 ZOne 模型在业务上的效果 。 从结果中可以看出 , 在 BERT 之后提出的预训练模型 , 例如 BERT WWM、ELECTRA、RoBERTa 等均要比 BERT 模型有更好的表现 , 而我们专门为业务定制的 ZOne 模型则在所有被测业务数据上均好于其它开源的通用大型预训练模型 。 这表明 BERT、RoBERTa 等开源的大型预训练模型在专业领域中的特定任务上的效果虽然能高于非预训练模型 , 但其效果依然不如专门为业务场景设计的 ZOne 模型 。
文章图片
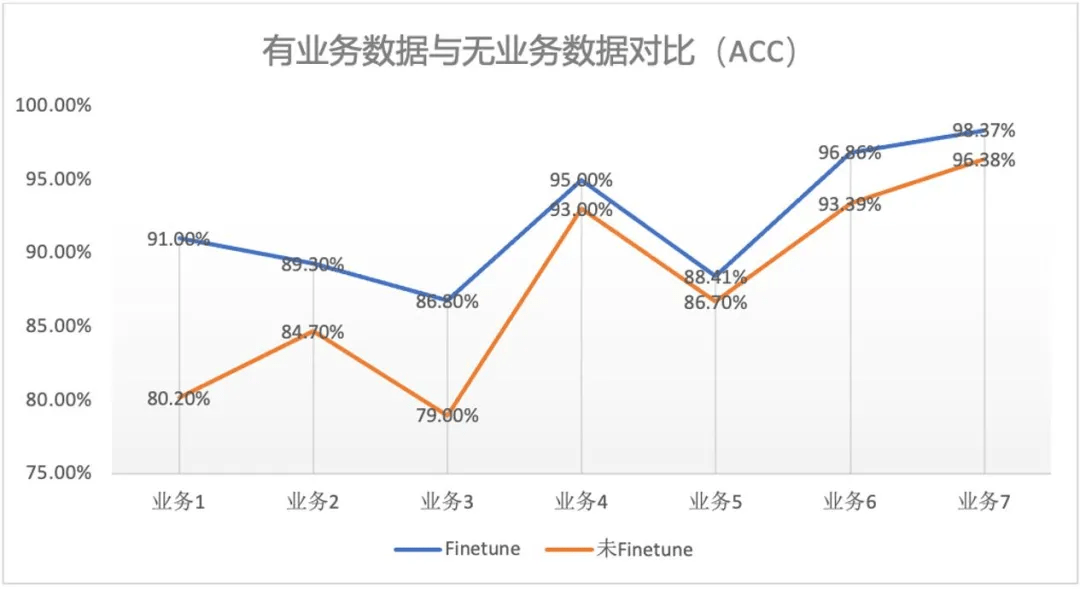
另一方面 , 不同业务场景的数据质量与数量参差不齐 , 特别是在冷启动时通常会面临缺少数据的问题 , 因此我们希望 ZOne 模型在全量数据下有更好表现的同时 , 也需要兼顾数据使用效率 。
ZOne 模型采用了特殊的预训练方式 , 具有在业务领域进行零样本的预测能力 。 零样本预测指的是在业务没有标注数据时 , 在不用标注数据对 ZOne 模型进行微调的情况下 , 直接只用预训练好的 ZOne 模型进行直接预测 。 上图中我们对七个业务进行了零样本能力的测试 , 其中 Finetune 对应有标注数据的情况 , 未 Finetune 对应零样本情况 。 从结果中可以看到即便是在没有数据的情况下 , ZOne 模型在 7 个业务上的效果也都基本达到 80% 以上的准确率 。
除了零样本能力外 , 我们还测试了 ZOne 模型在业务数据上的准确率与微调数据量之间的关系 , 以此来反映模型在微调阶段对数据量的需求情况:
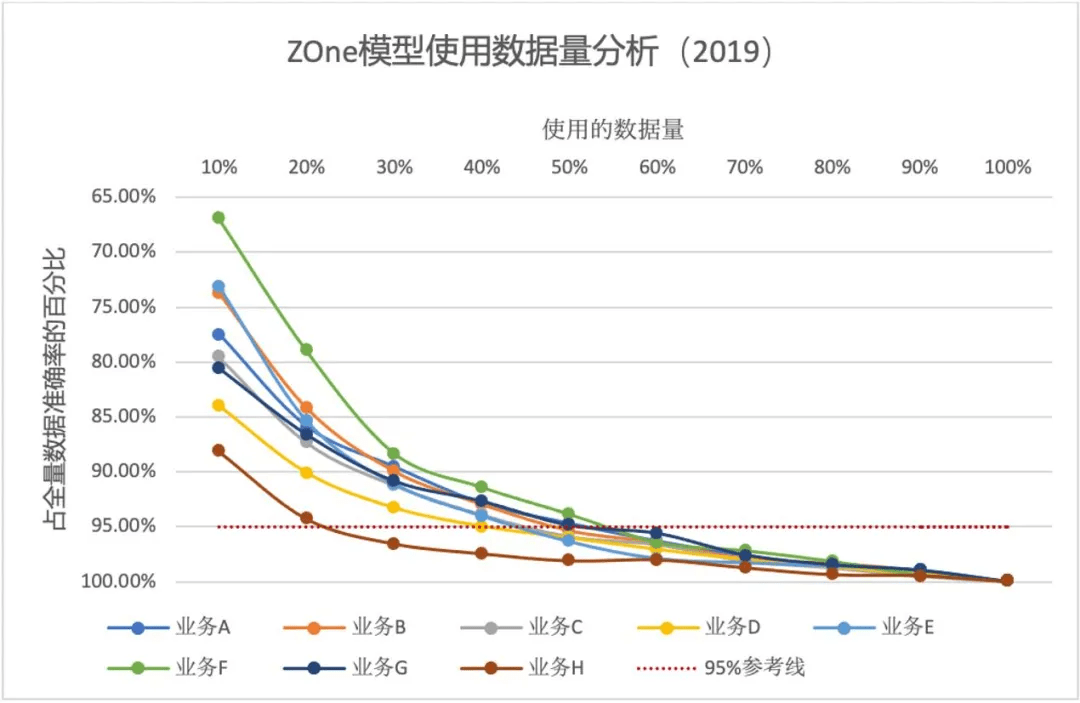
文章图片
上图以全量数据时各业务的准确率为基准 , 对比 8 个业务在微调数据量逐步增加的情况下准确率的变化 。 从图中可以看到 , 随着数据量的增加 , 准确率不断上升 , 而所有的业务都在只使用 60% 的数据量的情况下 , 可以达到使用全量数据时 95% 的效果 , 该结果表明在面对业务数据时 , ZOne 模型有较高的数据利用率 。
2020 年我们对 ZOne 模型进行了两次升级迭代(分别对应下表黄色与橙色部分) , 改进了预训练的损失函数计算方式 , 以及训练时的样本采样策略 , 同时引入的文本检索任务 , 以提高 ZOne 提取文本特征的能力 。 这一系列改动提高了模型在单个业务上的表现 , 同时也将模型微调阶段对数据的需求量进一步降低 。
新版本的 ZOne 模型在整体 8 个业务上的平均准确率比旧版本的 ZOne 模型提升了 4% 。 同时从下图可以看到新版本的 ZOne 模型对数据的需求量进一步降低 , 即使用 20%~40% 的数据量便可以达到全量数据的 95% 准确率 。
另一方面 , ZOne 作为大型的预训练模型 , 对微调与推理的资源有一定的要求 。 考虑到实际生产环境的资源限制与性能要求的不同 , 我们用模型蒸馏的方式来最大限度保留模型效果的前提下 , 压缩模型的大小并加快模型的微调与推理速度 。 上表中的 ZOne-distill(绿色部分)模型为 ZOne 的蒸馏版本 , 其体积为原模型的四分之一 , 微调与推理速度的提升在 3 倍以上 , 而模型效果只比原模型下降 1% 。 蒸馏的小型 ZOne 模型目前正用于追一科技的一些轻量级产品线上 。
结语
追一科技是国内最早将深度学习技术用于自然语言处理场景 , 并进行工业化落地的公司之一 。 我们从成立至今 , 一直致力于使用最前沿的技术解决现实中的实际问题 。
在 2016 年我们便使用基于 RNN 的模型进行语义理解的任务 , 2017 年在模型中引入多任务的训练方式 , 进一步提高多个核心模式的效果 。 2018 年我们开始尝试 Transformer 结构的模型 , 并在 2019 年开始进行自研的大型预训练模型研发 。 从 2019 年至今 , 我们研发了多个通用领域的大型预训练模型 , 并结合预训练与迁移学习的思路 , 结合自身的业务领域特点 , 设计了专门的预训练模型供给公司的不同业务产品线中使用 , 大幅提高了产品的效果与实际的体验 。
在大型预训练模型这一方向上 , 我们会保持持续投入 , 在保持业务效果优势的同时也会为中文 NLP 社区提供更多的开源模型 , 共同促进中文 NLP 技术的发展 。
推荐阅读







- 样儿|从太空看地球新年灯光秀啥样儿?快看!绝美风云卫星图来了
- the|美监督机构:从煤电厂捕获二氧化碳的计划浪费了联邦资金
- Pro|价格相差1000块钱 买小米12还是小米12 Pro?很多人选错了
- 最新消息|被骂“从未见过如此厚颜无耻之书” 中华书局回应称即日下架
- 趋势|[转]从“智能湖仓”升级看数据平台架构未来方向
- 刘思远|从1到100 这座“塔”不断创造中国航天奇迹
- 成功|从1到100 托举大国重器的“功勋塔架”
- 大叔|从治愈到共振,网易云音乐的刷屏套路升级了
- 大脑|从抗疫到治堵,AI成行业智能化“大底座”
- 画质|六款主流5G手机视频体验测评