接下来 , 本章展示了如何让神经网络解决棘手的逆问题 , 即 Navier-Stokes 模拟的长期控制问题 , 遵循 Holl 等人研究 。 这项任务需要长期规划 , 因此需要两个网络 , 一个用于预测演变过程 , 另一个用于实现预期目标 。
粗糙和参考流形的视觉概述
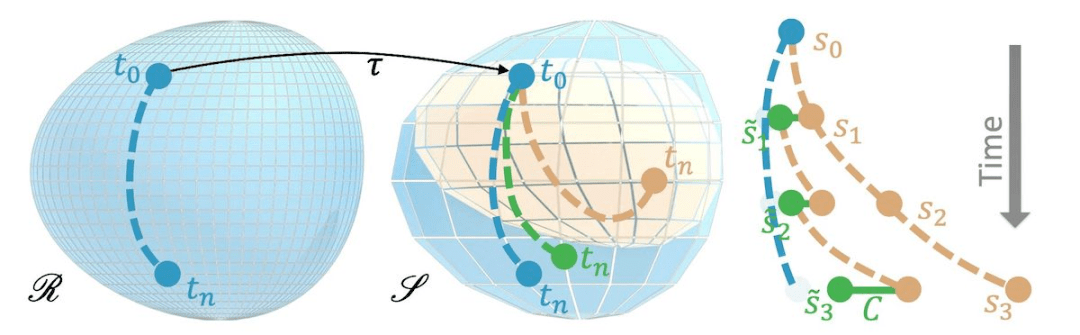
文章图片
强化学习
本章主要分两个小节:强化学习概述、用强化学习控制伯格斯方程(Burgers equation) 。
深度强化学习(DRL)是深度学习领域中的一类方法 , 它可以让人工智能体与周围环境进行交互 。 在执行此操作过程中 , 智能体接收其行为奖励信号 , 并尝试辨别哪些行为有助于获得更高的奖励 , 从而相应地调整自身行为 。 强化学习在围棋等游戏方面非常成功 , 并且在机器人技术等工程应用方面也非常重要 。
RL 的设置通常由两部分组成:环境和智能体 。 环境从智能体接收动作 a , 同时以状态 s 的形式向 a 提供观察 , 并奖励 r 。 观察结果代表了智能体能够感知来自各个环境状态的信息的一部分 。 奖励是由预定义的函数提供的 , 通常是根据环境量身定制的 , 可能包括游戏分数、错误行为的惩罚或成功完成任务的奖励 。
强化学习、环境与智能体相互影响
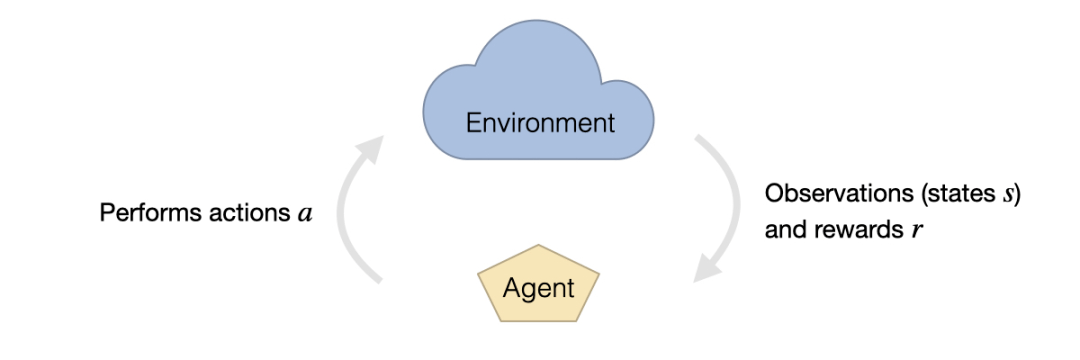
文章图片
本小节将 Burgers 方程的逆问题作为强化学习 (RL) 的实验平台 。 该设置类似于针对可微物理 (DP) 训练的逆问题 。 与之前类似 , Burgers 方程简单但非线性 , 具有有趣的动力学 , 因此是 RL 实验的良好起点 。 本小节目标是训练一个控制力估计器网络 , 该网络应该预测在两个给定状态之间产生平滑过渡所需的力 。
可微物理方法似乎比 RL 智能体产生更少的噪声轨迹 , 而两者都设法近似真值
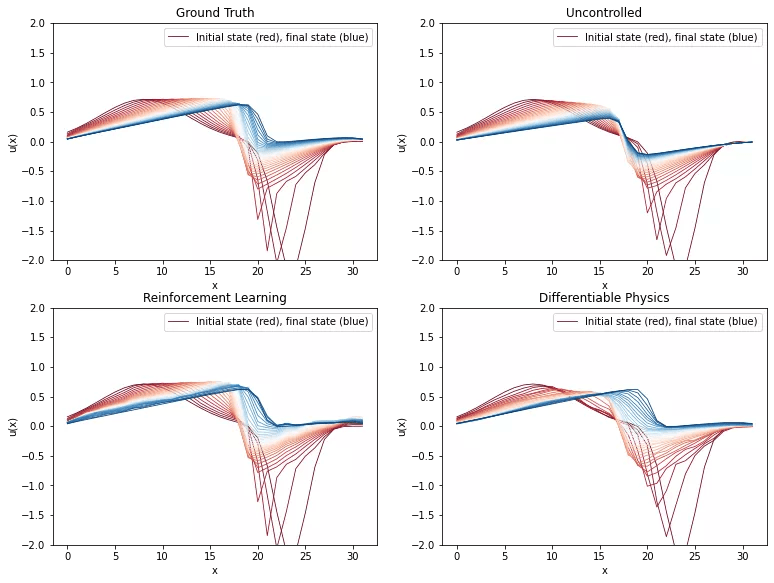
文章图片
PBDL 和不确定性
本章主要分两个小节:后验推理介绍、RANS Airfoil Flows 与贝叶斯神经网络 。
所有的测量、模型和离散化 , 都有其不确定性 。 对于测量 , 通常以测量误差的形式出现 。 另一方面 , 模型方程通常只包含我们感兴趣的一部分(剩余部分是不确定性的) , 而对于数值模拟 , 则引入了离散化误差 。 所以这里要问的一个非常重要的问题是 , 我们如何才能确保我们得到的答案是正确的 。 从统计学家的角度来看 , 后验概率分布捕获了我们对模型或数据可能存在不确定性的一些信息 。
书籍完整目录如下:

推荐阅读







- 硬件|Yukai推Amagami Ham Ham机器人:可模拟宠物咬指尖
- 传统|联想预热 135W 充电器,新款拯救者笔记本有望支持 PD 3.1
- 模拟|(图文+视频)C4D野教程:Windows11的壁纸动效是如何制作的?
- 规格|英伟达笔记本端 RTX 3080 Ti 最新爆料,功耗可达 175W
- Lenovo|联想2022年笔记本阵容曝光:运行Windows 11系统
- 全银|联想新款 ThinkPad Z13 / Z16 笔记本曝光,有望在 CES 2022 亮相
- 最新消息|当代笔记本电脑性能和60年代计算机性能比较
- 散热|由液晶屏到笔记本:静、动之间感受科技之美
- 手机|华为发布全新旗舰笔记本华为MateBook X Pro 2022款 一拉开启超级模式
- 操作|用最顶级硬件模拟最经典的掌机,是什么体验?这操作让我直呼内行