文章图片
PLATO-XL 模型:更高参数性价比 , 大幅提升训练效果
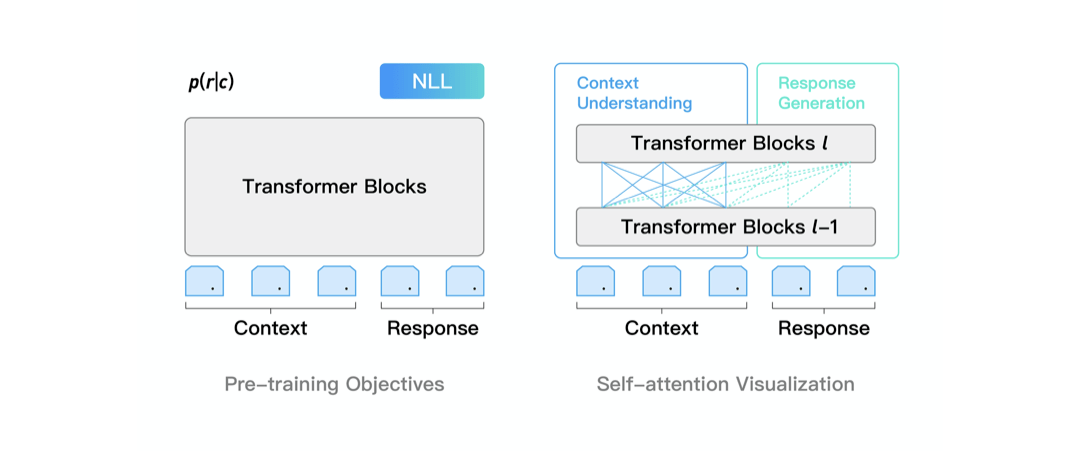
PLATO-XL 网络架构上承袭了 PLATO unified transformer 结构 , 可同时进行对话理解和回复生成的联合建模 , 参数性价比很高 。 通过灵活的注意力机制 , 模型对上文进行了双向编码 , 充分利用和理解上文信息;对回复进行了单向解码 , 适应回复生成的 auto-regressive 特性 。 此外 , unified transformer 结构在对话上训练效率很高 , 这是由于对话样本长短不一 , 训练过程中 padding 补齐会带来大量的无效计算 , unified transformer 可以对输入样本进行有效的排序 , 大幅提升训练效率 。
文章图片
为了进一步改善对话模型有时候自相矛盾的问题 , PLATO-XL 引入了多角色感知的输入表示 , 以提升多轮对话上的一致性 。 对话模型所用的预训练语料大多是社交媒体对话 , 通常有多个用户参与 , 表述和交流一些观点和内容 。 在训练时 , 模型较难区分对话上文中不同角度的观点和信息 , 容易产生一些自相矛盾的回复 。 针对社交媒体对话多方参与的特点 , PLATO-XL 进行了多角色感知的预训练 , 对多轮对话中的各个角色进行清晰区分 , 辅助模型生成更加连贯、一致的回复 。
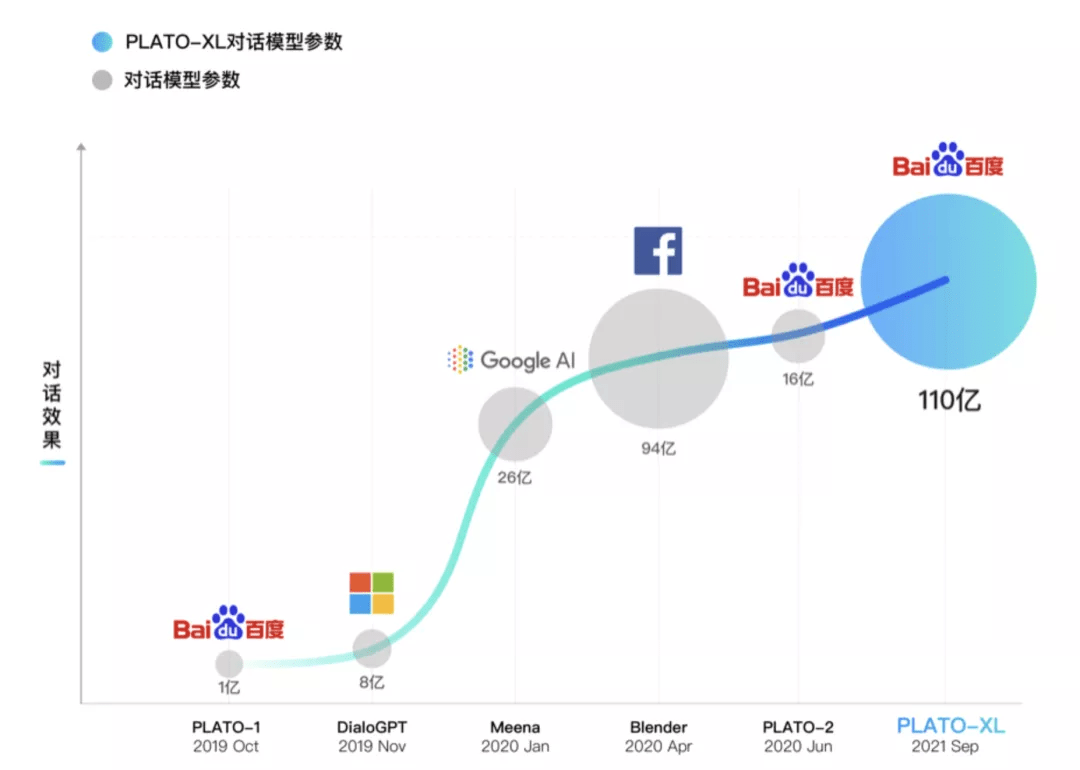
PLATO-XL 包括中英文 2 个对话模型 , 预训练语料规模达到千亿级 token , 模型规模高达 110 亿参数 。 PLATO-XL 也是完全基于百度自主研发的飞桨深度学习平台 , 利用了飞桨 FleetX 库的并行能力 , 使用了包括 recompute、sharded data parallelism 等策略 , 基于高性能 GPU 集群进行了训练 。
【中英文|超越Facebook,谷歌、微软,百度发布全球首个百亿参数对话预训练生成模型】PLATO-XL 效果:多种类型、多种任务 , 对话效果全面领先
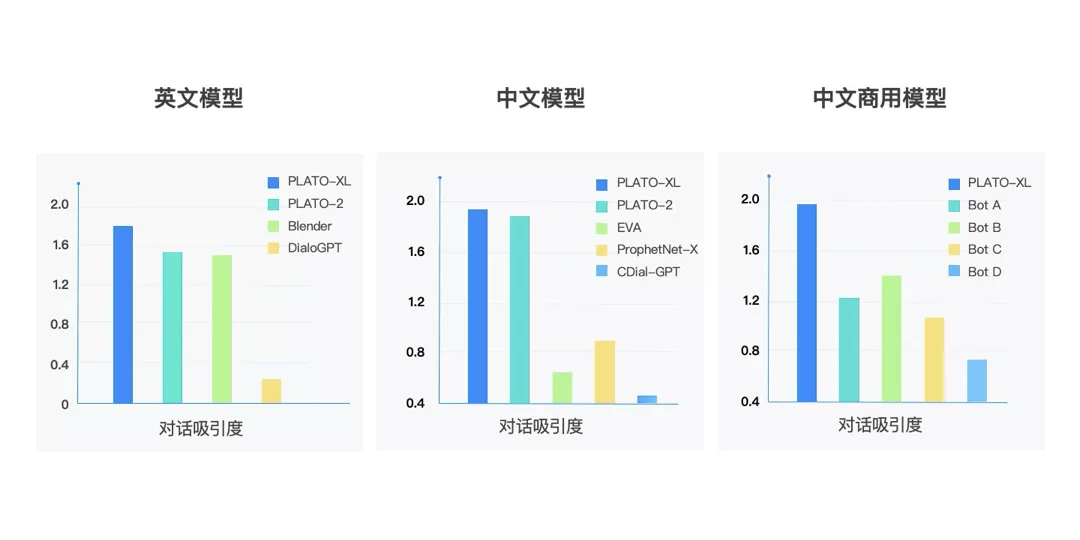
为了全面评估模型能力 , PLATO-XL 与当前开源的中英文对话模型进行了对比 , 评估中采用了两个模型针对开放域进行相互对话(self-chat)的形式 , 然后再通过人工来评估效果 。 PLATO-XL 与脸书 Blender、微软 DialoGPT、清华 EVA 模型相比 , 取得了更优异的效果 , 也进一步超越了之前 PLATO-2 取得的最好成绩 。 此外 , PLATO-XL 也显著超越了目前主流的商用聊天机器人 。
文章图片
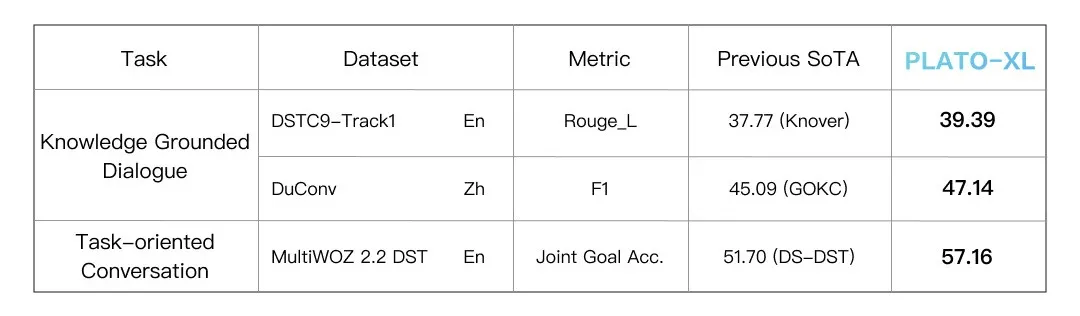
除了开放域闲聊对话 , 模型也可以很好的支持知识型对话和任务型对话 , 在多种对话任务上效果全面领先 。
文章图片
PLATO 系列涵盖了不同规模的对话模型 , 参数规模从 9300 万到 110 亿 。 下图可以看出 , 模型规模扩大对于效果提升也有显著作用 , 呈现较稳定的正相关关系 。
推荐阅读







- 社交|Facebook被指试图在美政客中抹黑前雇员Frances Haugen声誉
- Tesla|马斯克也要效仿谷歌Facebook 为特斯拉设立控股母公司?
- 手机|1千亿让小米超越苹果?别被雷军的障眼法,忽悠了
- 苹果|小米12系列手机发布,雷军:要在未来一步步超越苹果
- 雷军|小米史上最强、最小、最薄手机!3699起售…雷军:超越苹果
- 超越|小米12正式发布!雷布斯首次对标苹果,售价3699元起
- 社交|Signal创始人:Telegram并不安全,甚至还不如Facebook
- 赵明|【品牌】荣耀X30开售 | 赵明放话MagicV超越市面上所有折叠屏
- Media|澳大利亚要求谷歌和Facebook为新闻付费 但新闻网站可能造假
- 榜首|最新!TikTok超越谷歌,成2021年全球访问量最大的互联网网站