文章图片
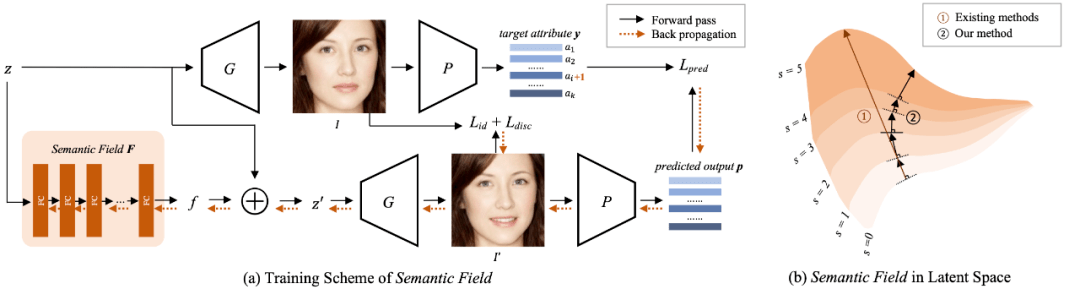
该研究所用方法抛开了 「走直线」 这一假设 , 在「走动」过程中不断根据此刻的隐向量寻找当前最优的前进方向 (如上图 (b) 中黑色路径 (2)) 。 于是 , 研究者在隐空间中构建一个向量场来表示每个隐向量的最佳「前进方向」 , 沿着当前隐向量的最佳「前进方向」 移动隐向量 , 从而改变图片的某一个语义特征 。 称这个向量场为语义场 , 即 Semantic Field 。 该研究的编辑方式等价于沿着向量场的场线 (field line) , 向势(potential) 增加得最快的方向移动 。 这里的势指的就是某一特征的程度 , 比如在编辑「刘海」这一特征时 , 隐向量沿着场线 , 向刘海变长最快的方向移动 (如上图(b) 中黑色路径(2)) 。
Semantic Field 具有两个特性:1) 对同一个人来说 , 不断改变某一个属性 , 需要的 “最佳前进方向” 是不断变化的 。 2)在编辑同一个属性时 , 对于不同人 , 对应的 「最佳前进方向」 也是不同的 。 该研究用一个神经网络来模拟 Semantic Field , 用如上图 (a) 所示的方法训练 Semantic Field 。 更多实现细节请参考论文和代码 。
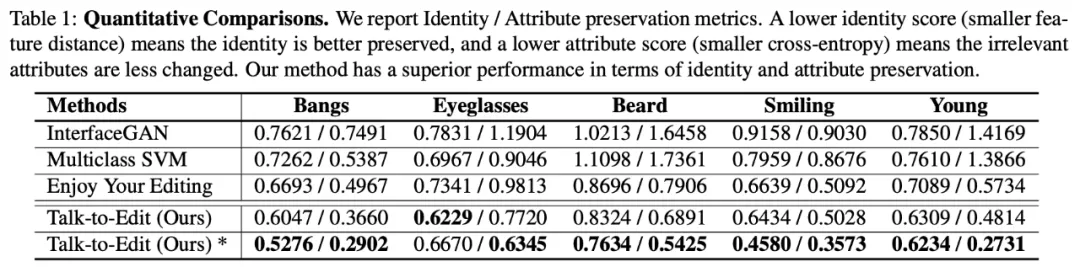
如下表 , 实验结果表明 , 相对于用 「走直线」 假设的 baselines , 该研究方法可以在人脸编辑的过程中更好的保留这个人的身份特征 , 并且在编辑某一个语义特征时减少对其他无关语义特征的改变 。
文章图片
如下图所示 , 对比很明显:

文章图片
(2) Language Encoder 和 Talk Module
为了给用户提供更便捷直观的交互方式 , 该研究使用对话的方式让用户实现编辑 。 Talk-to-Edit 用一个基于 LSTM 的 Language Encoder 来理解用户的编辑要求 , 并将编码后的编辑要求传递给 Semantic Field 从而指导编辑 。 Talk 模块可以在每轮编辑后向用户确认细粒度的编辑程度 , 比如向用户确认现在的笑容是否刚好合适 , 是否需要再多一档 。 Talk 模块也可以为用户提供其他编辑建议 , 比如系统发现用户从未尝试过编辑眼镜这个特征 , 于是询问用户是否想试一试给照片加个眼镜 。
CelebA-Dialog 数据集

文章图片
基于 CelebA [8] 数据集 , 该研究为研究社区提供了 CelebA-Dialog 数据集:
(1)研究提供了每张图片的高细粒度特征标注 。 如上图所示 , 根据笑容的灿烂程度 , 「笑容」这个语义特征被分为 6 档 。 CelebA-Dialog 精确地标注了每张图片中的「笑」 属于 6 个等级中的哪一个 。
推荐阅读







- 贷款|“扫码中大奖”?谁知领奖被“贷款”!
- AI|像谷歌地球一样用卫星图片重建洛杉矶3D模型 港中大团队提出CityNeRF
- 事业|哈尔滨理工大学大型话剧《永“珩”不灭的光》首次演出
- 张德强|聚焦OLED与Micro-LED两大主线 维信诺计划拓展笔电、车载等中大尺寸应用
- IT|理想ONE问鼎11月中国中大型SUV销量榜首 创始人李想:继续努力
- |上海理工大学实验室上演“未来乒乓球大战”
- IT|对标理想ONE:小鹏全新中大型SUV预告图发布,或取名G9
- 国际|西安理工大学荣获国家科技进步二等奖
- 国家|喜报!西安理工大学荣获国家科技进步二等奖
- 最新消息|产研联动:AWS和加州理工大学合作探索量子领域