百度这次发布的工作是基于强化学习的控制算法 。 强化学习应用在四足机器人领域并不是新的技术 , 但是之前发表的强化学习工作大部分都只能穿越一些比较简单的场景 , 在高难度的场景 , 比如通过独木板、跳隔板中 , 表现并不好 。 主要的原因是四足机器人中复杂的非线性控制系统使得强化学习探索起来十分困难 , 机器人经常还没走几步就摔倒了 , 很难从零开始学习到有效的步态 。
为了解决强化学习在四足控制上遇到的问题 , 百度团队首次提出基于自进化步态生成器的强化学习框架 。
文章图片
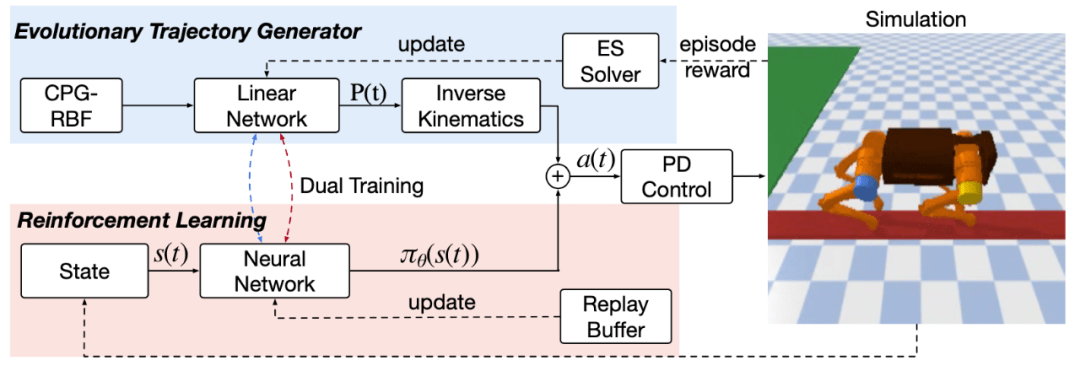
图二、ETG-RL 架构 。
该框架的概览图如上图 , 算法的控制信号由两部分组成:一个开环的步态生成器以及基于强化学习的神经网络 。
步态生成器可以提供步态先验来引导强化学习进行训练 。 以往的工作一般采用一个固定的步态生成器 , 这种方式只能生成一种固定的步态 , 没法针对环境进行特定的适配 。 特别是当预置的生成器并不适合环境的情况下 , 反而会影响强化学习部分的学习效果 。 针对这些问题 , 百度首次提出在轨迹空间直接进行搜索的自进化步态生成器优化方式 。 相比在参数空间进行搜索的方式 , 它可以更高效地搜索到合理的轨迹 , 因为在参数层面进行扰动很可能生成完全不合理的轨迹 , 并且搜索的参数量也大很多 。
强化学习部分的训练通过目前主流的 SAC 连续控制算法进行参数更新 , 在优化过程中 , 强化学习的策略网络需要输出合理的控制信号去结合开环的控制信号 , 以获得更高的奖励 。 需要注意的是 , 该框架在更新过程中 , 是采用交替训练的方式 , 即独立更新步态生成器以及神经网络 。 这主要的原因是其中一个模块的更新会导致机器人的行为发布发生变化 , 不利于训练的稳定性 。
最后 , 为了提升样本的有效利用率 , 该框架还复用了进化算法在优化步态生成器的数据 , 将其添加到强化学习的训练数据中 。
文章图片
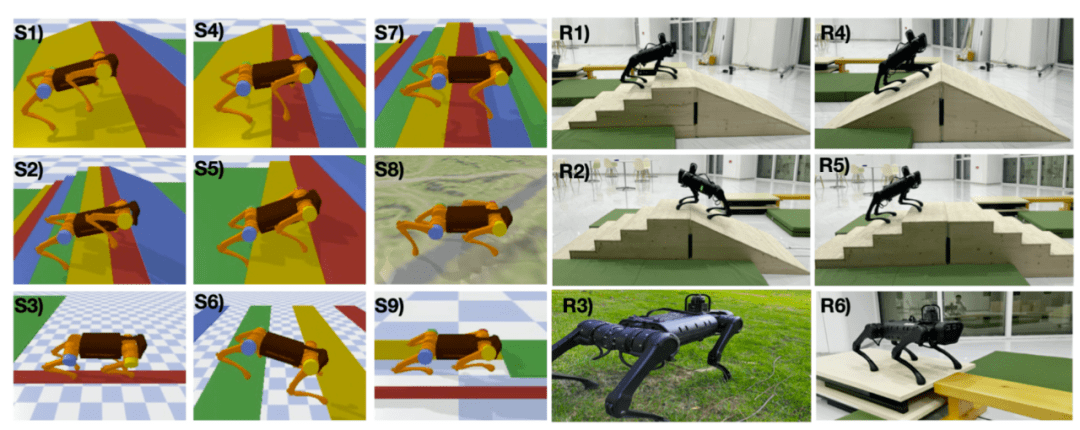
图三、实验场景(仿真 + 真机)
接下来看文章中的实验部分 。 如上图所示 , 百度基于开源的 pybullet 构建了 9 个实验场景 , 包括了上下楼梯、斜坡、穿越不规整地形、独木板、洞穴、跳跃隔板等场景 。 其算法效果与经典的开环控制器、强化学习算法相比 , 提升相当大 。 可以看到百度提出的框架(绿色曲线)遥遥领先于别的算法 , 并且是唯一一个能完成所有任务的算法 。 完整的仿真效果以及真机视频可以参考文末链接 。
推荐阅读







- 相关|科思科技:无人机地面控制站相关设备产品开始逐步发力
- Baidu|百度抢跑元宇宙 却默认“输给”字节?
- 华能|全球首座!华能百兆瓦级分散控制储能电站投运
- Tencent|继百度网盘后腾讯微云也已解除限速 不用单独下载App
- 词条|百度百科上线2500万词条,超750万用户参与共创科普知识内容
- Baidu|百度网盘青春版正式上线 只能传3次文件被吐槽是“一次性App”
- 青春|百度网盘青春版正式上线:免费空间 10GB,支持无差别速率下载
- Create|什么是元宇宙游戏?百度《希壤》成国内第一个吃螃蟹的人
- 量子|百度量子平台2.0重磅发布!推动构建量子计算领域繁荣生态
- 汽车|Apollo迎来7.0重大升级,百度自动驾驶开放平台迈向工具化时代