机器之心报道
机器之心编辑部
用神经网络给视频解码 , 效率居然还挺高的 。随着通信和互联网技术的进步 , 特别是智能手机的普及以及 4G、5G 移动通信技术的成熟与发展 , 视频聊天、视频游戏等多样化的视频娱乐方式层出不穷 , 普通用户对视频的消费需求也在不断增长 。 2018 年思科 CISCO《视觉网络指数》报告预测 , 到 2022 年 , 82% 的互联网流量将由视频创造 。
除了日常生活中的娱乐交流用途之外 , 视频也正在更多行业场景中大显身手 。 比如 , 以视频技术为核心的安防领域、智能工厂中对工人行为的视频监控与识别、辅助与自动驾驶中通过摄像头记录视频画面实时检测环境、以及近年来越来越多明星也下场参与的视频直播营销 , 等等 。 与此同时 , 随着 AI 领域计算机视觉(CV)技术的蓬勃发展 , CV + 视频的技术组合将会在越来越多的应用场景中发挥不可或缺的作用 。

文章图片
然而 , 海量的视频数据对视频的传输、存储和其他处理带来了巨大的挑战 。 视频压缩、编解码等视频处理技术也就变得至关重要 。 在观看视频时 , 用户想要体验更高的画质和流畅度 , 这些都依托更高效的视频处理技术 。 多年来 , 计算机中视频解码的工作多由 CPU 来完成 , 这种方式易于使用但效率算不上很高 。 利用 GPU 解码视频是另一种选择 。 随着短视频等应用的兴起 , 在手机等移动端借助专用解码单元进行实时视频解码也成为了一种新的发展方向 , 对于视频直播等实时性视频服务具有重要意义 。
与此同时 , 随着 AI 领域深度神经网络的发展 , 越来越多的企业探索如何使神经网络赋能自身产品 。 高通骁龙 SoC 中的 AI 引擎就充分融入了神经网络能力 , 其中的硬件组件 Hexagon 向量处理器支持 8 位定点加速神经网络运行 , 软件组件骁龙神经处理(SNP)SDK 支持 CNN、LSTM 与自定义层 。
旗舰 SoC 骁龙 888 集成的第六代高通 AI 引擎更是实现了 26 TOPS 的 AI 算力 , 神经网络处理 SDK 带来一系列改进 , 增加了对 RNN 模型的支持 , 助力手机端侧 AI 性能提升至了全新水平 。
【技术|手机上用AI实时、流畅解码视频:高通研发出首个神经视频解码器】那么 , 有没有可能将 AI 引擎蕴含的巨大算力更广泛、更深入地应用于视频领域呢?最近 , 高通就在这方面做了更多的尝试 , 利用骁龙 888 内置的 AI 引擎和 CPU 进行视频解码 。 结果发现:基于神经网络的神经视频解码效果还不错 。
高通 AI 研究院的新工作 , 实现了业界首款在商用智能手机端实时运行、基于软硬件结合的神经视频解码器 , 在接近 720p HD 分辨率的视频上实现了 30 fps 以上的实时解码 。

文章图片
从软 / 硬解码到 AI 神经视频解码
作为一项重要的视频处理技术 , 视频编解码广泛应用于通信、计算机与广播电视领域 , 并催生了网络电视、广播电视、数字影院、远程教育和会议电视等一系列实际应用 。
就主要作用而言 , 视频编解码技术是在可用的计算资源内 , 追求尽可能高的视频重建质量和尽可能高的压缩比 , 以达到带宽和存储容量的要求 。 视频编解码器则是一种能够对数字视频进行压缩或者解压缩的程序或者设备 。
很长时间以来 , 基于 CPU 的软件编解码技术(也称软解码)一直主导着市场 , 如英特尔内置于其 CPU 中的视频编解码引擎以及开源软件 FFmpeg 中的 libavcodec 解码器 , 虽然易于使用 , 但会占用 CPU 资源 , 提升功耗 , 编解码效率不高 , 容易出现卡顿、花屏等异常 , 影响其他应用的正常运行 。
因此 , 利用 GPU 或者专用处理器来对视频进行编解码(也称硬解码)成为另一种选择 , 如英伟达推出的基于 GPU 的硬件解码器模块 NvCodec , 不仅可以实现良好的编码性能 , 而且使用显卡编码不会占用太多系统资源 , 也就不会影响应用的使用性能 。
但是 , 日益增长的视频消费需求对未来的视频编解码器提出了更高的要求 , 应该具备以下功能:
- 比特率和感知质量指标的直接优化
- 简化的编解码器开发
- 内在的大规模并行性
- 高效执行和更新已部署硬件的能力
- 可下载的编解码器更新
在这种潜力的驱动下 , 过去几年神经网络视频编解码器成为了研究热门 , 如 2017 年谷歌提出的 Hyperprior 自编码器、18 年上海交通大学等机构提出的端到端深度视频压缩(Deep Video Compression )框架以及 2020 年谷歌研究院感知团队提出的用于端到端优化视频压缩的扩展空间流(Scale-Space Flow) 。 这类神经视频编解码器展现出了令人瞩目的压缩性能 , 并缩小了与传统编解码器之间的差距 。

文章图片
基于 AI 的压缩具有绝对优势 。
但还应看到 , 将 AI 研究从实验室带到实际应用场景往往并不容易 。 这也意味着 , 神经视频编解码器的实际部署面临着很大的挑战 。 大多数相关研究利用具有浮点计算的壁式驱动的高端 GPU , 并且神经网络模型架构往往没有针对快速推理进行优化 。 因此 , 对于具有固定计算、功率和温度约束的移动设备而言 , 在这类神经网络解码器模型上运行实时推理不切实际或不可行 。
在骁龙 888 SoC 的商用智能手机上 , 高通 AI 研究院在基于软硬件结合的神经网络视频解码器方面实现了新的突破 。
利用骁龙 888 的 CPU 和 AI 引擎 , 实现 30+fps 的高清视频解码
凭借在节能 AI 方面的专业知识以及骁龙 888 平台的强大 AI 算力 , 高通在商用智能手机上实现了实时帧内神经视频编码 。 高效率视频编码(HEVC)中的帧内编码可以视为高端视频编码(AVC)的扩展 , 它们利用空间上的取样预测来编码 。 帧内编码过程与帧间编码共用部分的处理步骤包含转换、量化、熵编码等 。 为此 , 高通 AI 研究院在以下几个方面进行了优化:
重新设计网络架构以降低复杂度;
在 AI 推理引擎上量化和加速神经网络;
利用并行熵编码 。
基于以上几个方面的优化 , 高通利用骁龙 888 移动平台上的 CPU 和 AI 引擎 , 开发出了一种基于软硬件结合的神经视频解码器 , 以超过 30fps 的速度解码了分辨率 1280×704 的高清视频 , 并且无需视频解码单元的任何帮助 。 骁龙 888 集成第六代高通 AI 引擎 , 作为一整套处理器协作系统 , 这代 AI 引擎包含了重新设计的 Hexagon 780 处理器 , 将 AI 全方位赋能极速通信、专业影像、游戏体验等诸多方面 。

文章图片
具有高效解码性能的 8 比特模型
解码器架构优化、并行熵解码(PEC)和 AIMET 量化感知训练是高通 AI 研究院实现智能手机端高效神经编码的三个重要步骤 。

文章图片
第一步 , 基于一个 SOTA 帧对压缩网络 , 通过剪枝通道和优化网络操作实现了解码器架构优化 , 依靠骁龙 888 内置的 AI 引擎进行加速 , 降低了计算复杂度 。
第二步 , 创建一种快速并行化熵解码(fast parallel entropy decoding)算法 。 该算法可以利用数据级和线程级并行化 , 从而可以实现更高的熵编码吞吐量 。 在高通的方案中 , 骁龙 888 的 CPU 用来处理并行熵解码 。
第三步 , 优化后模型的权重和激活量化至 8 比特 , 然后通过量化感知训练来恢复速率失真带来的损失 。 这里用到了高通创新中心开源的 AI 模型效率工具包(AI Model Efficiency Toolkit, AIMET) , 该工具于 2020 年 5 月推出并开源 , 是一个支持神经网络模型训练的高级量化和压缩技术的库 。
通过这三个步骤 , 高通 AI 研究院构建了一个具有高效解码性能的 8 比特模型(8-bit model) 。
AI 解码的效果
在 Demo 设置中 , 高通 AI 研究院选取了分辨率为 1280×704(接近 720p HD)的视频 , 通过离线运行解码器网络和熵解码生成压缩的比特流 。 接着 , 压缩的比特流通过骁龙 888 移动设备(商用智能手机)上运行的并行熵解码和解码器网络来处理 , 其中并行熵解码在 CPU 上运行 , 解码器网络在第六代高通 AI 引擎进行加速 。
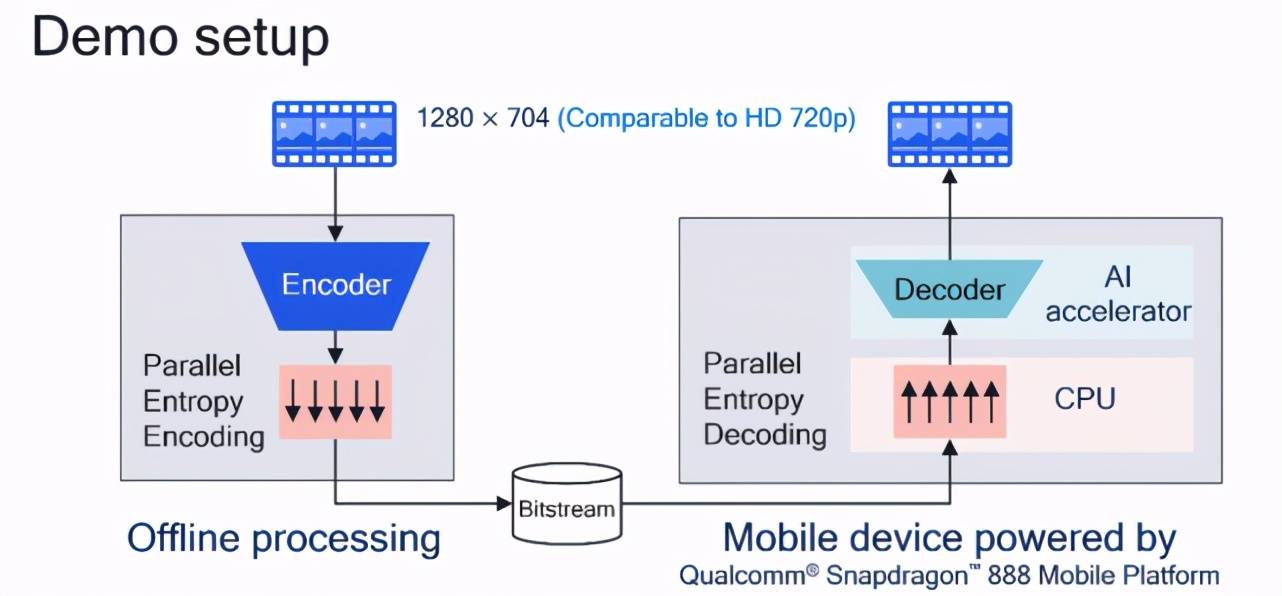
文章图片
最终 , 高通 AI 研究院得到了一个神经解码算法 , 在 1280×704 分辨率的视频中实现了每秒 30 帧以上的解码速度 。 如下为商用智能手机上神经视频解码的动态演示 , 右上角为视频解码速度(Speed)和同一视频帧内的迭代次数(Loop) , 右边为运行时平均比特率(Bit Rate)和视频每帧图像中每单位像素的平均码流(Bits per Pixel per Frame, BPF) 。
在 Demo 演示中 , 视频和解码参数被设置为高质量 , 并选取了一系列具有挑战性和精细纹理的自然场景 。 在实现 30 帧以上解码速度的同时 , 丰富的视觉结构和纹理都借助神经解码网络准确地保留了下来 , 实现了非常好的场景重现 。 比特率符合全帧内(all-intra)配置和选取的质量 , 表明这一神经视频解码器能够支持高质量视频流所需的数据吞吐量 。

文章图片
由于基于 AI 的编解码器可以生成比特流中没有的视觉细节 , 因此与传统编解码器相比 , 相同或更高质量视频的比特率应该会低一些 。 这也意味着视频编解码器将变成软硬件结合驱动的 , 任何新的编解码器都可以由 SoC 中的 CPU 和内置 AI 加速器处理 , 只要它们足够强大 。
目前 , 这一神经视频解码器只支持帧内解码 , 这意味着每帧视频都是独立解码 , 不需要像其他视频编解码器那样考虑帧之间的微小变化 。 据悉 , 高通还将继续致力于研究移动设备上实时运行的帧间视频解码 。
就此项研究的意义而言 , 虽然在骁龙 888 SoC 上实现 30 fps + 高清视频实时解码依然有提升的空间 , 但手机端侧 AI 算力和影像能力的释放 , 能够为手机用户带来更丰富的视频应用以及更清晰流畅的观看体验 。 比如近期最新发布的骁龙 888 Plus 移动平台 , 虽然仅仅是在骁龙 888 基础上做出了部分升级 , 但其 AI 算力已经达到了惊人的 32TOPS , 进一步大幅度升级;再加上高通接下来的持续深入研究 , 可以预见的是 , AI 的高清视频实时解码能力将很快进一步提升 。
除了手机平台之外 , 高通也已将 AI 处理视频的各项能力引入了 PC、XR 和汽车等其他应用平台 。 比如全球首款 5G 扩展现实平台骁龙 XR2 的 AI 性能相较初代 XR 提升了 11 倍 , 大幅提升了视频处理能力;PC 端的第二代骁龙 8cx 5G 计算平台中 , AI 能力加持的 Spectra ISP 支持了 4K HDR 品质的视频拍摄和背景虚化;第 4 代骁龙汽车数字座驾平台 , 增强了图形图像、计算机视觉和 AI 等功能 , 可以为驾乘者提供更智能和舒适的视频服务等体验 。
因此 , 从更大的视角来看 , 利用 AI 算力进行视频处理代表了未来的一个发展方向 , 也势必会赋能更多应用场景 。
参考链接:
https://segmentfault.com/a/1190000038930366
https://cnx-software.cn/2021/06/28/neural-video-decoder-leverages/
https://finance.sina.com.cn/tech/2021-02-04/doc-ikftssap3428399.shtml
https://www.leiphone.com/category/industrynews/0YEJQiyu3umwEyjJ.html
推荐阅读







- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- 技术|“2”类医械有重大进展:神经介入产品井喷、基因测序弯道超车
- 手机|一加10 Pro宣传视频曝光:将于1月11日14点发布
- 手机|黑莓宣布 1 月 4 日起将终止 BlackBerry OS 设备服务支持
- 选型|数据架构选型必读:2021上半年数据库产品技术解析
- 技术|使用云原生应用和开源技术的创新攻略
- 手机|【直播纪要】VR/MR会吹响消费电子反攻的号角吗?| 见智研究
- 技术|聚光科技旗下临床质谱仪获批医疗器械注册证
- Apple|苹果高管解读AirPods 3代技术细节 暗示蓝牙带宽可能成为瓶颈
- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术