自从2016年Alphago战胜李世石后 , 全球许多科技巨头都投入到AI的竞争中 。 我们也很快在我们的日常生活中用上了AI智能音箱 , 接触到AI智能客服 , 用上了AI的人脸识别 。
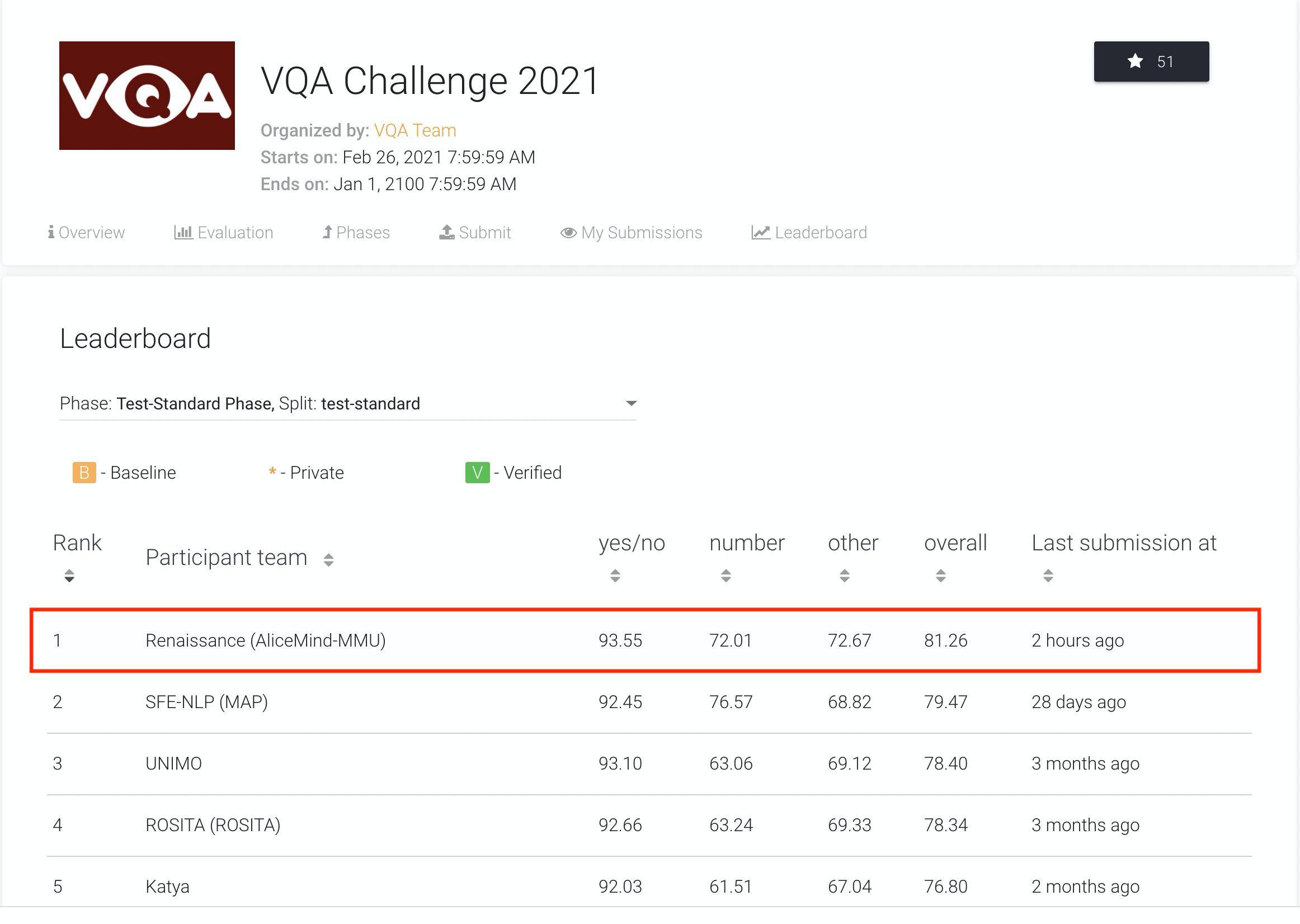
同时 , 众多科技公司追求AI技术进步的脚步也从未停歇 。 2021年8月12日 , 阿里巴巴达摩院的AliceMind团队刷新全球最权威机器视觉问答榜单VQA(Visual Question Answering), 并以81.26分的成绩让AI在“读图会意”上首次超越人类表现 。
文章图片
AI技术虽然发展很早 , 但是一度停滞了很多年 , 一直到新世纪深度神经网络复兴 , 应用到AlphaGo上击败顶级棋手李世石 , AI才开始重新进入快车道 。
AI的机器视觉 , 是一个非常重要而且有实用性的分支 , 通过CNN卷积模型 , AI在2015年实现了视觉分类超越人类 。 但是应用到真实世界 , AI仅仅能识别是不够的 。
所以 , 全球计算机视觉顶会ICCV及CVPR从2015年起先后举办VQA挑战赛 , 聚集微软、Facebook、斯坦福大学、阿里巴巴、百度等众多世界最强AI研究机构 , 形成了国际上规模最大、认可度最高的VQA数据集 , 对视觉-文本多模态技术进行攻关 。
VQA测试 , 是给定一些图片 , 然后用自然语言针对图片中的内容提出问题 , 让AI理解自然语言提出的问题 , 识别图片 , 然后正确回答 。
我们看VQA的一道试题 , 给定下面这张玩具的图片 , 然后提出问题 。

文章图片
What are those toys there for?(这些玩具用在什么地方?)正确答案是Wedding(婚礼) 。
这个问题 , 对人类来说似乎不太难 , 但是对AI来说非常大的挑战 。
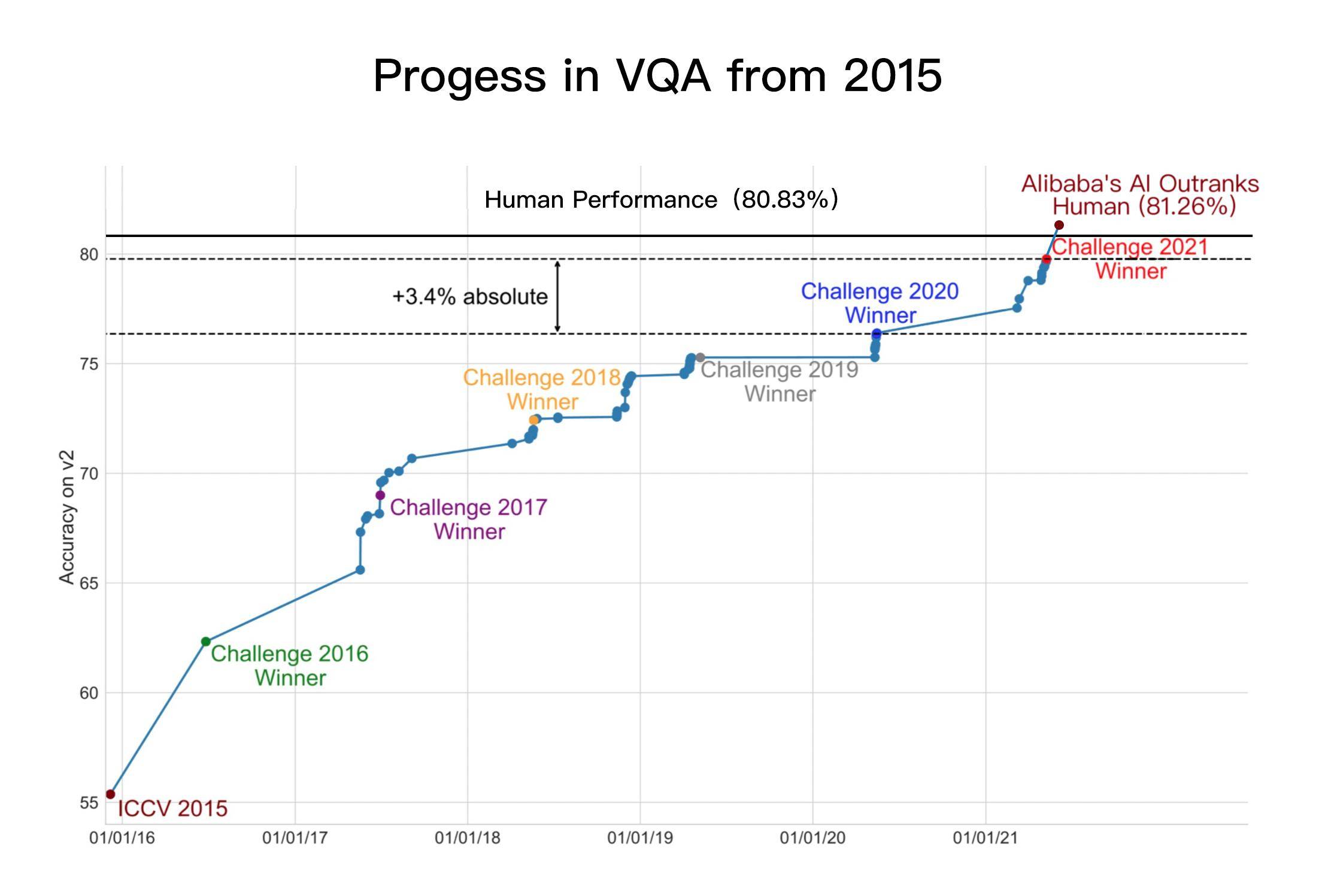
整个测试都是各种各样不同的图和各种各样不同的问题 , 2016年水平的AI , 在进行VQA测试的时候 , 分数很低 , 最高准确率仅能达到55% 。
而经过多年的努力 , 2021年 , 阿里在这个测试中取得了非常好的成绩 , 这是与微软、Facebook、伯克利、百度等一流公司、一流大学、一流研发机构竞争 , 取得高分来之不易 。
而且 , 这也是VQA测试以来 , AI第一次超过人类水平 , 是标志性的重大突破 。
文章图片
最近几年 , AI的成果一直在转化 , 今天 , 我们用自然语言可以给智能音箱下命令 , 让AI像管家一样帮我们控制联网的家电 。
这在短短十年前 , 都是科幻片的情景 。 但我们和音箱的交互技术主要是语音语义识别 , 仍然是单模态的 。
那么 , 这次阿里达摩院在VQA这个高难度领域突破 , 超越人类 , 又会给我们带来什么?
皇冠上的明珠
过去几年 , 人类在AI上有很多突破 , 这些突破主要都是单模态的 , 也就是替代人类一种感官 。 譬如机器视觉用于人脸识别、物体识别 。 语音识别用于识别人类语音 , 判断语义 。 这些都依赖深度神经网络的发展 。
从DNN(深度神经网络)到RNN(循环神经网络) , CNN(卷积神经网络) , GAN(生成式对抗网络) , Transformer(机器翻译模型) , AI在最近10多年中取得了巨大进步 。
我们用上了智能音箱 , 普及了基于AI技术的人脸识别 , 有了能够交谈的AI客服 , 但AI与人类跨模态的交互问题一直没有解决 。
VQA给AI一幅图像 , 一个用自然语言描述的问题 , 让AI用自然语言回答 , 要求多模态的技术能力 。
首先 , 要让AI非常准确地理解图像和问题 , 这是第一步 。
人类理解自然语言描述的一个问题 , 首先要懂语言 , 譬如一个英文问题 , 你先得懂英语才行 。 要懂英语 , 你得学单词 , 背语法 , 了解固定搭配 , 知道句型 。 而AI要看懂也得经历这个过程 。 除此之外 , AI还要像人一样拥有常识和推理能力 。
就图像识别来说 , 目前人工智能技术已经比较成熟 , 毕竟2015年AI已在图像分类上超过人类 , 识别单一物体人工智能已经不再是难事 。
但是对VQA任务来说 , 问题往往并不是关于整张图片 , 而是针对图片中某一个或者某几个物体 。 人工智能要根据对问题的理解 , 把目标物体从复杂影像中聚焦出来 , 这是第二步 。
譬如 , 图片中可能有10个人 , VQA所提出的问题只与一个人有关 , AI要从10个人中聚焦到问题相关的人 , 这就难了 。

文章图片
准确理解问题、聚焦信息还不够 , 还得根据问题的意思作出回答 , 你能够聚焦出来一幅图的重点物体是衣服 , 但是要回答的问题是衣服的文字代表什么球队 。
因此AI还要学会推理 , 看衣服上什么文字和球队相关 , 然后根据球队标识回答 。
最后 , AI推理完毕了 , 还要产生自然语言的回答 。 这才算是完成任务 。
我们现在日常用的AI识别 , 还属于感知级别的AI , 譬如认个人脸 , 认个身份证 , 听懂语音 。 而VQA是多种AI技术的集成 , 已接近认知层面 , 可以算AI技术皇冠上的明珠之一 。
所以 , 一开始这类测试 , 尽管参加者都是世界一流的科技公司 , 大学 , 研发机构 , 但是得分都很低 , 后来一年年随着技术和算力的进步才逐渐提升 。
今天 , 阿里已经取得了80多分 , 超过人类的分数 , 这是非常不容易的 。
攻克VQA难题
如同我们前面说的 , VQA挑战的核心难点在于 , 需在单模态精准理解的基础上 , 整合多模态的信息进行联合推理认知 , 最终实现跨模态理解 。
这相当于人类通过多个认知途径获取信息 , 最后综合判断做出结论 。
对于这个挑战 , 阿里达摩院的NLP和视觉团队联手 , 对AI视觉-文本推理体系进行了系统性的设计 , 融合了大量算法创新 , 做出一个整体的解决方案 , 具体包括四个方面:
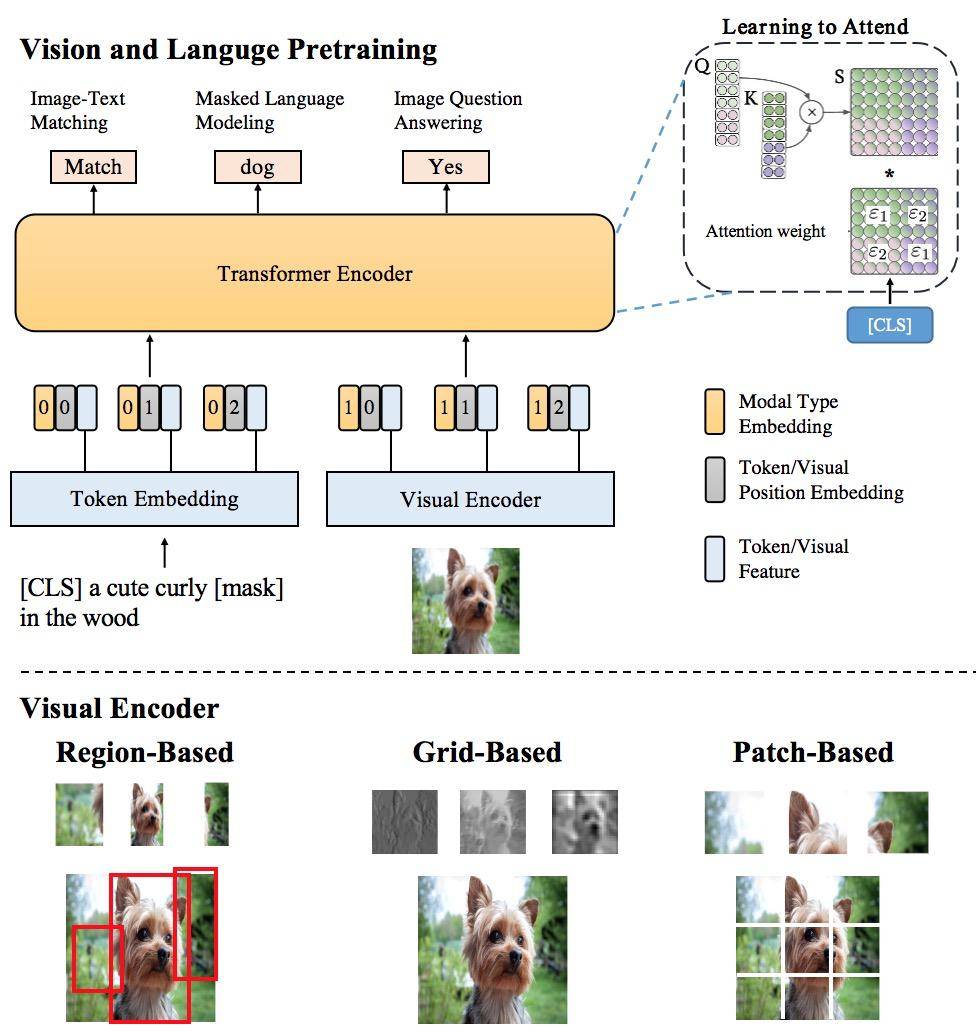
一是先尽可能地提升单模态理解的精度 。 主要是对图片识别的精确 。 阿里从多个方面刻画图片的局部和全局的语义信息 , 同时使用Region , Grid , Patch等视觉特征表示 , 更清楚的把图片上的东西都识别清楚了 , 这样可以更精准地进行单模态理解 。 相当于人类在识别物体的时候看得更清楚 , 为后续打下基础 。
二是做大量多模态预训练 。 达摩院团队基于海量的图文数据和多粒度视觉特征做多模态预训练 , 用于更好地进行多模态信息融合和语义映射 , 发展出了SemVLP , Grid-VLP , E2E-VLP和Fusion-VLP等预训练模型 。
这个相当于人类上学学基础知识 , 你有了基础知识 , 才能对看到的东西做个判断 , 古代人不认识汽车 , 现代人因为学过什么是汽车 , 所以看到汽车就知道这是汽车 。 计算机也得学习 , 多模态的预训练就是这样的学习过程 。 学习得越多 , 识别得越准 。
三是研发自适应的跨模态语义融合和对齐技术 , 创新性地在多模态预训练模型中加入Learning to Attend机制来进行跨模态信息地高效深度融合 。 就是说AI不能只会扫描大图 , 还要能聚焦到与问题相关的视觉信息上 。
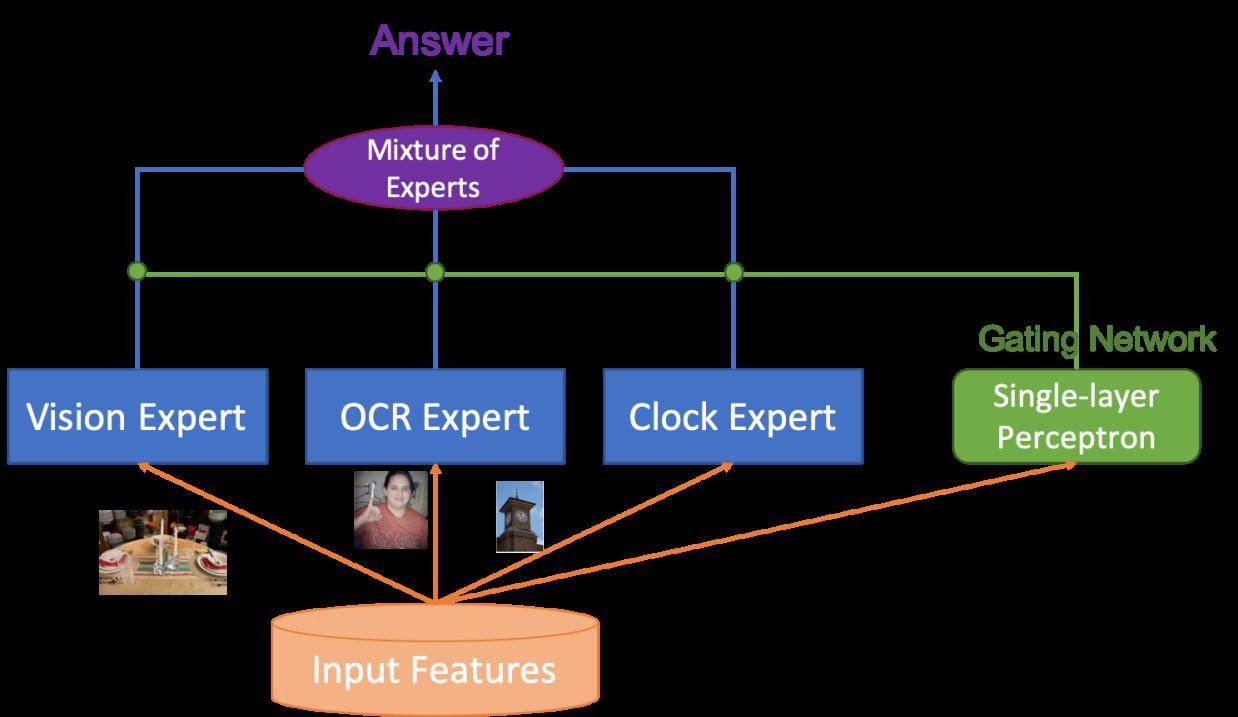
四是采用Mixture of Experts (MOE)技术进行知识驱动的多技能AI集成 。 因为VQA本身是多模态的 , 人工智能的神经网络当然不能只用一个 , 也得多个一起来 , A神经网络适合算A , 就去算A 。 B神经网络适合算B , 就去算B 。 把这些神经网络集成起来 , 可以取得最好的效果 。
文章图片
文章图片
至于看懂问题 , 阿里达摩院前身IDST早在2018年就在斯坦福SQuAD挑战赛中历史性地让机器阅读理解首次超越人类 , 当时轰动全球 。 2021年阿里开源了历时三年打造的深度语言模型体系AliceMind , 包含通用语言模型、多语言、生成式、多模态、结构化、知识驱动等领域 , 能力已经很全面 。
所以 , 阿里VQA超越人类不是一朝一夕之功 , 而是多年技术积累的结果 。
VQA的未来
AI技术史上许多不起眼的进步 , 最终都给我们的生活带来了便利 。 自动驾驶的突破虽然没有让无人驾驶普及 , 但是自动泊车、自动跟车、高速路自动巡航已非常普及 。
【识别|达摩院VQA首超人类,会带给我们什么?】VQA技术拥有广阔的想象空间 , 可以用于图文阅读、跨模态搜索、盲人视觉问答、医疗问诊、智能驾驶、虚拟主播等领域 , 有可能将变革人机交互方式 。
目前 , VQA技术已在阿里内部应用于商品图文理解、智能客服等场景 。
据报道 , 数万家淘宝天猫商家开通了店小蜜客服VQA视觉问答功能 , AI帮助提升了提问解决率 , 优化了买家体验 , 降低了商家配置工作量 。 盒马、考拉的客服场景 , 闲鱼的图文同款匹配场景也接入了VQA能力 。
当然 , 这些VQA相关的应用仅仅是牛刀小试 。
因为VQA其实并不是理解一张图片那么简单 。 未来的人机交互输入 , 可能不是图片而是现实世界的影像 。 而解决方案 , 也未必是语言回答 , 也可以是控制行动 。 VQA的技术成熟以后 , 我们可以通过自然语言发出指令 , 让AI在现实世界中完成更复杂的操作 。
比如 , 我们给机器人下命令 , 机器人理解你的语言意图后 , 然后扫描周边环境 , 找到符合你意图的东西 , 执行行动 。
可能 , 未来有一天 , 你对机器人说 , “给我洗衣服 。 ”
机器人理解你的意图 , 然后扫描房间内环境 , 聚焦到脏衣篮这个物体 , 移动到脏衣篮 , 然后聚焦到脏衣服这个物体 , 把脏衣服用机械手拿起来 。
然后再聚焦到洗衣机这个物体 , 把衣服放进去 。 它通过常识和逻辑判断洗衣机如何操作 , 给你完成洗衣、甩干、烘干 , 最后拿出衣服 , 聚焦到你的衣柜 , 把衣服放进衣柜整理好 。
整个过程的识别都需要VQA技术作为基础 , 这可能是VQA技术未来的一个应用方向 。
推荐阅读







- 识别|沈阳地铁重大变化!能摘口罩吗?
- 识别|天津滨海机场RFID行李全流程跟踪系统完成建设 行李标签识别成功率可提升至99%
- 研究院|传统行业搭上数字化快车,施工现场变“智造工厂”
- 机器|戴森达人学院 | 戴森HP09空气净化暖风扇测评报告
- 美容|升级扩业 中家医·家庭医生医疗美容医院引爆广州
- 文化|【“用数赋智”系列宣讲】苏州工艺美术职业技术学院探索传统工艺的跨界创新
- IT|南非研究显示两剂强生新冠疫苗可大幅降低Omicron导致的住院
- 团队|深信院41项科研项目亮相高交会 11个项目获优秀产品奖
- 索尼|索尼推出两款无线低音炮、环绕音箱,适配家庭影院
- 生命科学学院|科技馆内感受科技魅力