GitHub|Transformer拿下CV顶会大奖,微软亚研获ICCV 2021最佳论文( 二 )
其一 , 引入 CNN 中常用的层次化构建方式构建分层 Transformer;
其二 , 引入局部性(locality)思想 , 对无重合的窗口区域内进行自注意力计算 。
首先来看 Swin Transformer 的整体工作流 , 下图 3a 为 Swin Transformer 的整体架构 , 图 3b 为两个连续的 Swin Transformer 块 。
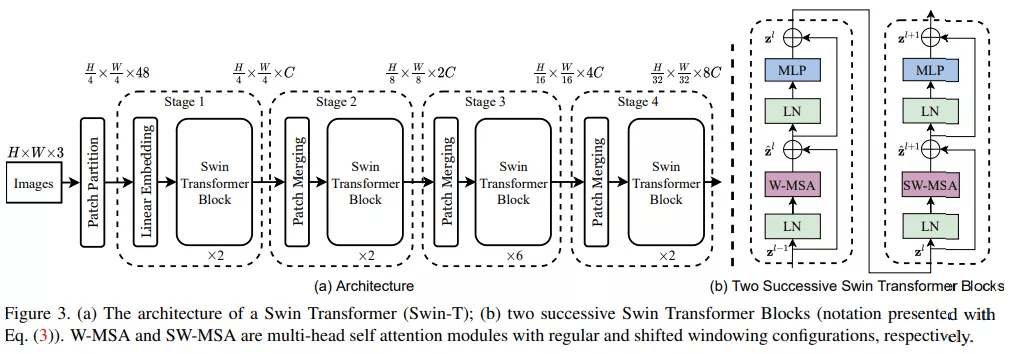
文章图片
该研究的亮点在于利用移动窗口对分层 Transformer 的表征进行计算 。 通过将自注意力计算限制在不重叠的局部串口 , 同时允许跨窗口连接 。 这种分层结构可以灵活地在不同尺度上建模 , 并具有图像大小的线性计算复杂度 。 下图 2 为在 Swin Transformer 架构中利用移动窗口计算自注意力的工作流:
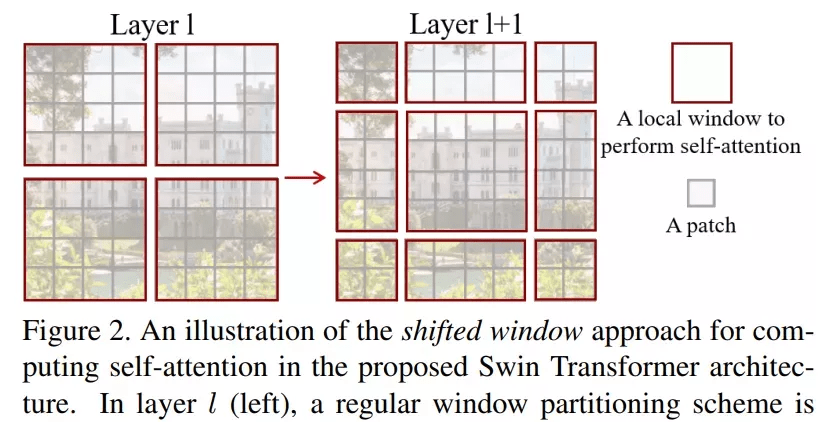
文章图片
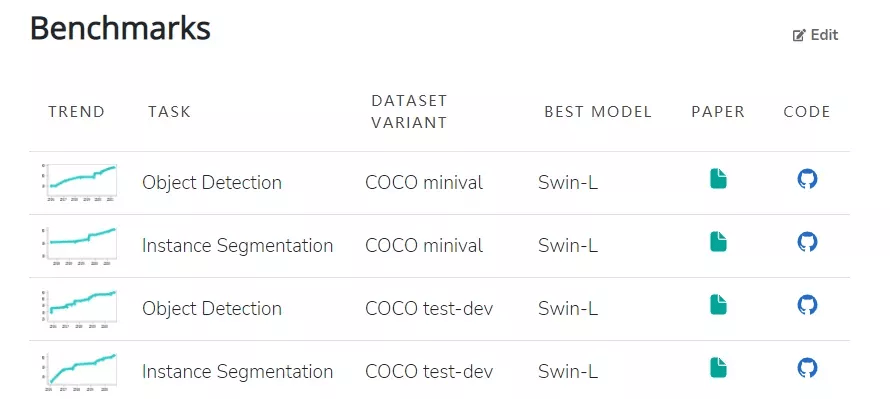
模型本身具有的特性使其在一系列视觉任务上都实现了颇具竞争力的性能表现 。 其中 , 在 ImageNet-1K 数据集上实现了 86.4% 的图像分类准确率、在 COCO test-dev 数据集上实现了 58.7% 的目标检测 box AP 和 51.1% 的 mask AP 。 目前在 COCO minival 和 COCO test-dev 两个数据集上 , Swin-L(Swin Transformer 的变体)在目标检测和实例分割任务中均实现了 SOTA 。
文章图片
此外 , 在 ADE20K val 和 ADE20K 数据集上 , Swin-L 也在语义分割任务中实现了 SOTA 。
最佳学生论文奖
- 获奖论文:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
- 作者机构:苏黎世联邦理工学院、微软
- 论文地址:https://arxiv.org/pdf/2108.08291.pdf
- 项目地址:github.com/cvg/pixel-perfect-sfm (http://github.com/cvg/pixel-perfect-sfm)

文章图片
论文摘要:在多个视图中寻找可重复的局部特征是稀疏 3D 重建的基础 。 经典的图像匹配范式一次性检测每个图像的全部关键点(keypoint) , 这可能会产生定位不佳的特征 , 使得最终生成的几何形状出现较大错误 。 研究者通过直接对齐来自多个视图的低级图像信息来细化运动恢复结构(structure-from-motion , SFM)的两个关键步骤:首先在任何几何估计之前调整初始关键点位置 , 然后细化点和相机姿态作为一个后处理 。 这种改进对大的检测噪声和外观变化具有稳健性 , 因为它基于神经网络预测的密集特征优化了特征度量误差 。 这显著提高了相机姿态和场景几何的准确性 , 并适用于各种关键点检测器、具有挑战性的观看条件和现成的(off-the-shelf)深度特征 。 该系统可以轻松扩展到大型图像集合 , 从而实现像素完美的大规模众包定位 。 该方法现已封装为 SfM 软件 COLMAP 的附加组件 。
推荐阅读







- GitHub|小米 12 / Pro / X 系列内核源码已公开,基于 Android 12
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- 用户|全新微软 Win11 WSA 开源工具上线 GitHub:支持双击 APK 安装
- 手机|四季度5G手机出货已超4G:苹果iPhone拿下销量、收入双料第一
- Tesla|三星拿下特斯拉订单打造全新车载电脑芯片
- 硬件|郭明錤:最坏时间已过 大立光专利战胜出 可望拿下中国一线品牌客户长单
- 王雅|一波三折后成功“拿下”!又一项世界级大会落地成都!
- 查尔斯·巴贝奇|曾遥不可及的机械美学,如今被OPPO用7699元拿下了。
- Huawei|华为申请元OS商标:此前已拿下鸿蒙元服务
- Alibaba|Gartner:阿里云拿下四个全球第一 超越亚马逊、微软