Pre-LN|归一化提高预训练、缓解梯度不匹配,Facebook的模型超越GPT-3( 三 )
对于预训练数据 , 研究者在包含 CC100 英语语料库以及由 BookCorpus、英文维基百科和 Common Crawl 过滤子集组成的 Liu et al. (2019)的数据英语文本集合上对所有模型进行预训练 。
在下图 2 中 , 研究者将 CLM 和 MLM 的预训练困惑度表示训练时间 , 即 GPU days 。 可以看到 , NormFormer 的训练速度明显更快 , 并且在给定训练计算预算下实现了更好的验证困惑度 。
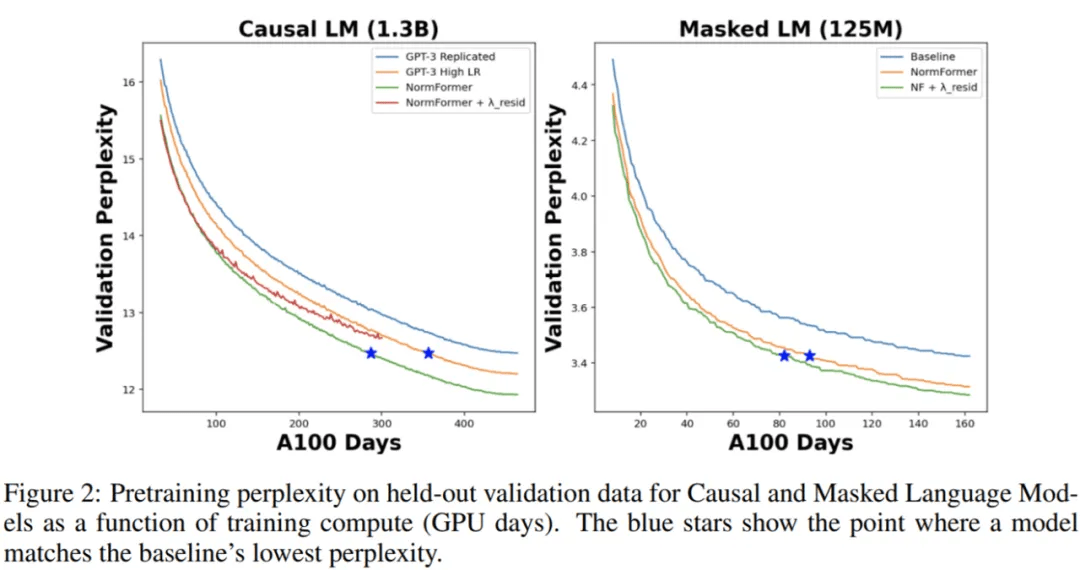
文章图片
研究者在下游任务上也观察到了类似的趋势 。 如下表 2 所示 , 研究者使用 Brown et al. (2020)中的任务和 prompt 来观察 CLM 模型的零样本准确率 。 同样地 , NormFormer 在所有大小上均优于 GPT-3 。

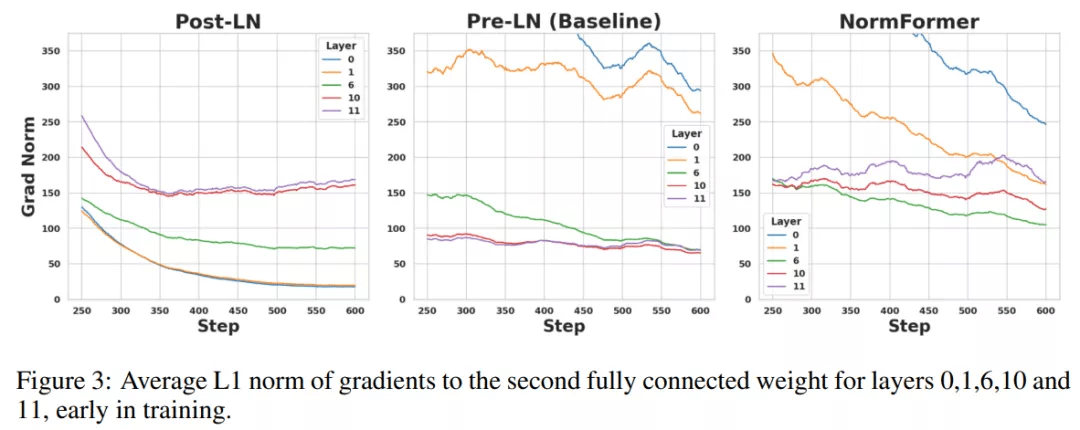
文章图片
对于 MLM 模型 , 研究者在下表 3 中报告了在 GLUE 上的微调准确率 。 再次 , NormFormer MLM 模型在每个任务上都优于它们的 Pre-LN 模型 。
文章图片
为了度量架构的稳定性 , 研究者使用具有极大峰值学习率的学习率计划对其进行训练 , 使得学习率每个 step 增加一点 , 直到损失爆炸 。 图 5 显示了与基线相比 , NormFormer 模型在此环境中可以承受更多的更新 。
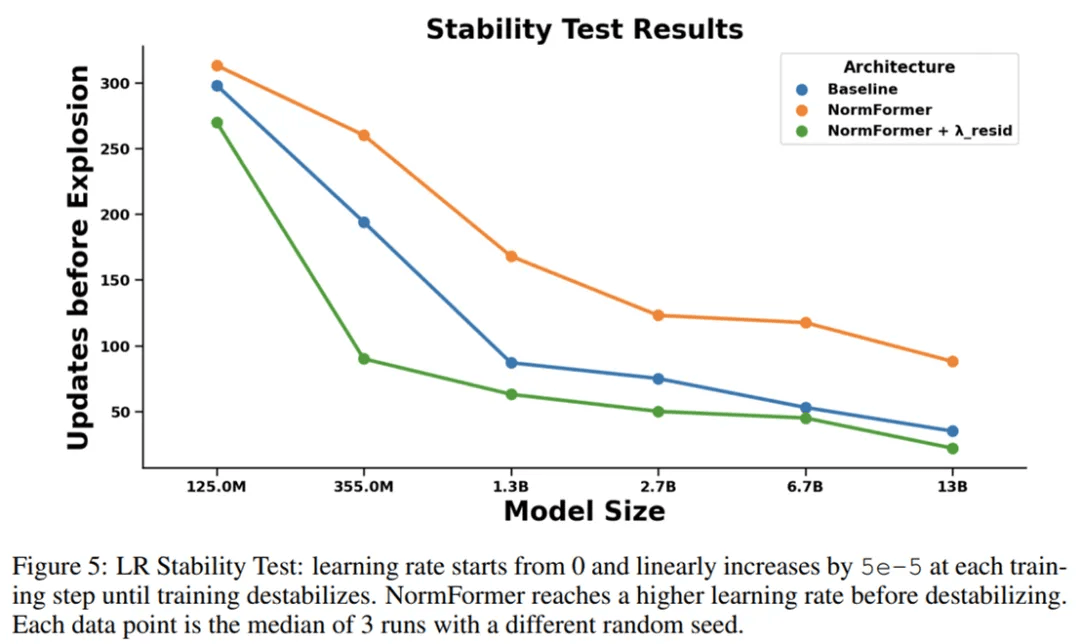
文章图片
推荐阅读







- 浦峰|冬奥纪实8k超高清试验频道开播,冬奥结束后转入常态化运转
- 数字化|零售数字化转型显效 兴业银行手机银行接连获奖
- 建设|这一次,我们用SASE为教育信息化建设保驾护航
- 智能化|适老化服务让银行更有温度
- 苏宁|可循环包装规模化应用 苏宁易购绿色物流再上新台阶
- |南安市交通运输局强化渣土 运输安全专项整治
- 测试|图森未来完成全球首次无人驾驶重卡在公开道路的全无人化测试
- 网络化|工信部:2025年建成500个以上智能制造示范工厂
- 识别|沈阳地铁重大变化!能摘口罩吗?
- 智能化|龙净环保:智能型物料气力输送系统的研究及应用成果通过鉴定