学习用于可视化内容的离散 Codebook
该研究利用 VQ-VAE 将连续图像内容转换为离散 token 形式 。 图像表示为 x∈ R^H×W×3 , VQ-VAE 用离散视觉 Codebook 来表示图像 , 即
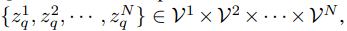
文章图片
其中 , VQ-VAE 包含三个主要部分:编码器、量化器和解码器 。 编码器负责将输入图像映射到中间潜在向量 z = Enc(x);量化器根据最近邻分配原则负责将位置 (i, j) 处的向量量化为来自 Codebook 对应的码字(codewords):
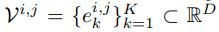
文章图片
然后得到如下公式:
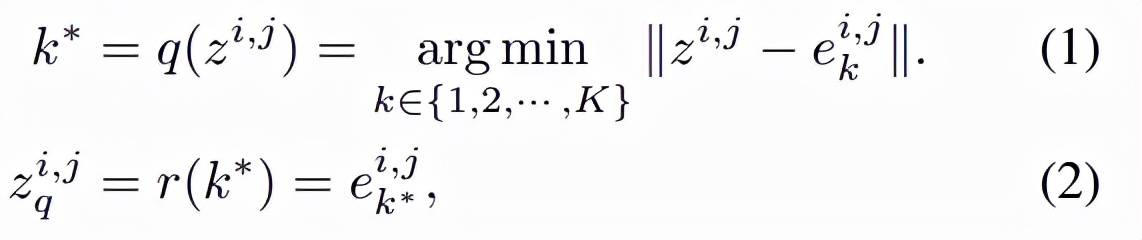
文章图片
其中 q 是量化编码器 , 可以将向量映射到 codebook 索引 , r 是量化解码器 , 可以从索引重构向量 。 基于量化的码字为 z_q , 解码器旨在重构输入图像 x 。 VQ-VAE 的训练目标定义为:
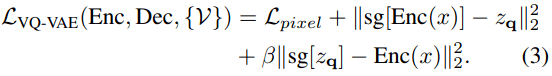
文章图片
学习用于视觉内容的 PeCo
该研究提出 , 在不包含像素损失的情况下 , 对模型强制执行原始图像和重构图像之间的感知相似性 。 感知相似性不是基于像素之间的差异得到的 , 而是基于从预训练深度神经网络中提取的高级图像特征表示之间的差异而得到 。 该研究希望这种基于 feature-wise 的损失能够更好地捕捉感知差异并提供对低级变化的不变性 。 下图从图像重构的角度展示了模型使用不同损失的比较 , 结果表明图像在较低的 pixel-wise 损失下可能不会出现感知相似:

文章图片
图 1. 不同损失下的图像重构比较 。 每个示例包含三个图像 , 输入(左)、使用 pixel-wise 损失重构图像(中)、使用 pixel-wise 损失和 feature-wise 损失重构图像(右) 。 与中间图像相比 , 右侧图像在感知上与输入更相似 。
在形式上 , 假设输入图像 x 和重构图像
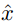
文章图片
的感知度量可以表示为:
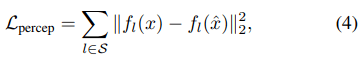
文章图片
其中 S 表示提取特征的层数 , 总的目标函数为:
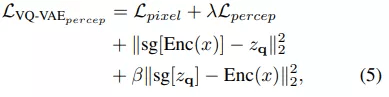
文章图片
BERT objective 执行掩码图像建模
该研究采用 BERT objective 在离散视觉 token 上执行掩码图像建模任务 , 如 BEiT 。 对于给定的图像 x , 输入 token 为不重叠的图像 patch , 输出 token 是通过学习方程 (5) 获得的离散感知视觉单词 。 设输入为 {x_1 , x_2 , · · · , x_N } , 并且真值输出为
推荐阅读







- 视觉|超高色准打破行业天花板,创维S82还原真实世界
- 训练|华为运动健康 Beta 新版本测试:新增健身课程分享、血压挑战计划
- 视觉|下瓦房“钻石壹号”品牌区 ——全新升级 耀世登场
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- Windows|微软正为Windows 11开发新Mica视觉效果
- 模型|神经辐射场去掉「神经」,训练速度提升100多倍,3D效果质量不减
- 硬件|瑞芯微智能视觉芯片RV1126荣获CPSE安博会最高殊荣:金鼎奖
- 检测|基于双目视觉的目标检测与追踪方案详解
- 训练|腾讯云副总裁吴运生:AI落地出现新变化,对细分行业需要深入理解
- 最新消息|视觉中国成立元视觉拍卖公司 注册资本5000万