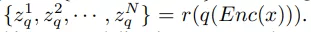
文章图片
。掩码图像建模的目标是从掩码输入中恢复相应的视觉 token , 其中一部分输入 token 已被掩码掉 。 准确地说 , 令 M 为掩码索引集合 , 掩码输入
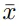
文章图片
表示为:
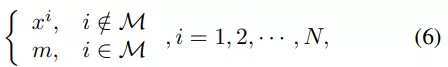
文章图片
其中 , m 是与非掩码 token 相同维度的可学习掩码 token 。 掩码(masked)输入 token 被送入 L 层视觉 Transformer , 最后一层的隐藏输出表示为 {h^1 , h^2 , · · · , h^N } 。
实验
该研究将预训练模型应用于各种下游任务 , 包括 ImageNet-1K 分类、COCO 目标检测和 ADE20k 分割 。
与 SOTA 模型比较
首先该研究将 PeCo 与 SOTA 研究进行比较 。 研究者使用 ViT-B 作为主干并在 ImageNet-1K 上进行预训练 , epoch 为 300。
图像分类任务:在 ImageNet 1K 上进行分类任务的 Top-1 准确率如表 1 所示 。 可以看出 , 与从头开始训练的模型相比 , PeCo 显着提高了性能 , 这表明预训练的有效性 。 更重要的是 , 与之前自监督预训练模型相比 , PeCo 模型实现了最佳性能 。 值得一提的是 , 与采用 800 epoch 的 BEiT 预训练相比 , PeCo 仅用 300 epoch 就实现了 0.9% 的提高 , 并比 MAE 采用 1600 epoch 预训练性能提高 0.5% 。 这验证了 PeCo 确实有利于预训练 。
文章图片
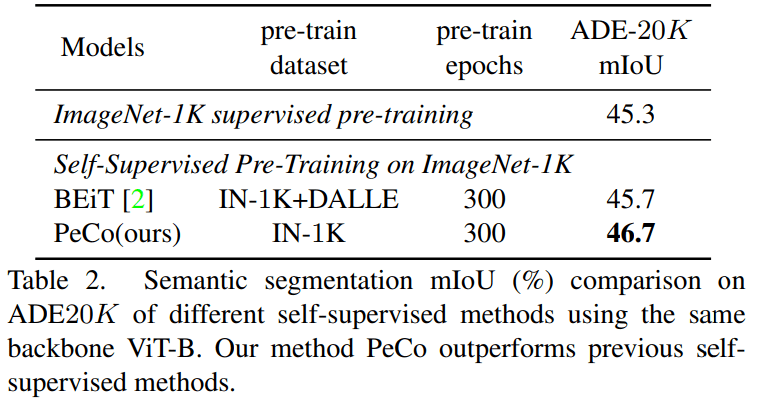
语义分割任务:该研究将 PeCo 与 1)在 ImageNet-1K 上进行监督预训练和 2)BEiT(SOTA 性能自监督学习模型)进行比较 , 评估指标是 mIoU , 结果如表 2 所示 。 由结果可得 , PeCo 在预训练期间不涉及任何标签信息 , 却取得了比监督预训练更好的性能 。 此外 , 与自监督 BEiT 相比 , PeCo 模型也获得了较好的性能 , 这进一步验证了 PeCo 的有效性 。
文章图片
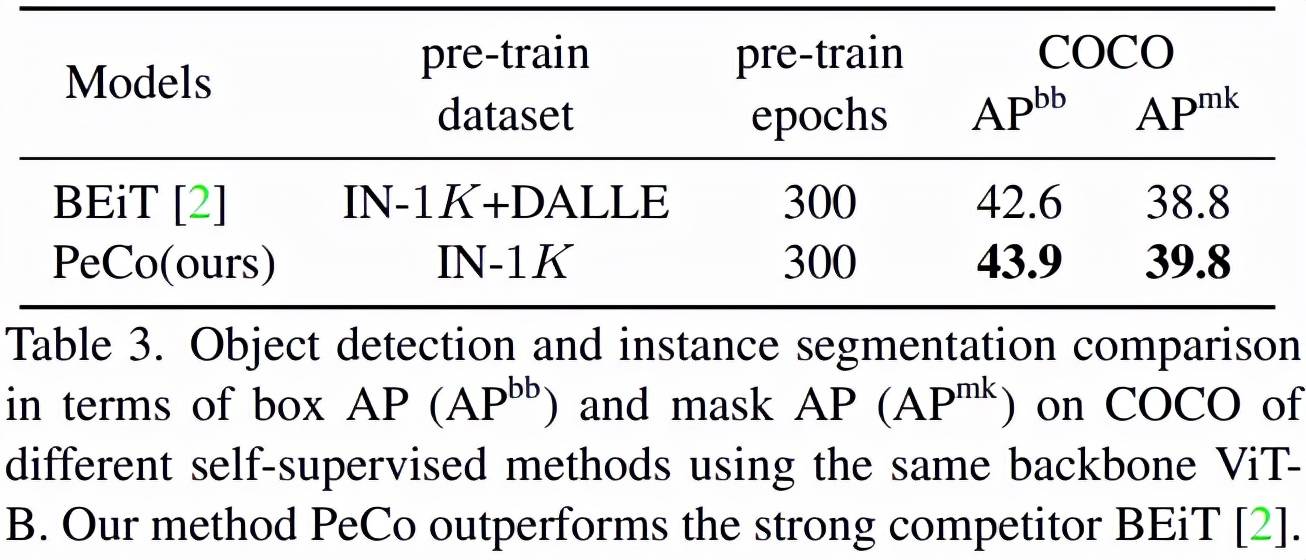
目标检测与分割:如表 3 所示 , 在这一任务上 , PeCo 获得了最好的性能:
文章图片
感知 Codebook 分析
码字语义:学习的感知码字是否具有(更多)语义含义?为了回答这个问题 , 该研究设计实验以提供视觉和定量结果 。
首先 , 该研究将对应于相同码字的图像 patch 进行可视化 , 并与两个基线进行比较:在 2.5 亿私有数据上训练而成的 DALL-E codebook;不使用感知相似性的 PeCo 模型的一个变体 。 结果如图 3 所示 , 我们可以看到该研究码字与语义高度相关 , 如图中所示的轮子 , 来自基线的码字通常与低级信息(如纹理、颜色、边缘)相关 。
推荐阅读







- 视觉|超高色准打破行业天花板,创维S82还原真实世界
- 训练|华为运动健康 Beta 新版本测试:新增健身课程分享、血压挑战计划
- 视觉|下瓦房“钻石壹号”品牌区 ——全新升级 耀世登场
- 模型|经逆向工程,Transformer「翻译」成数学框架 | 25位学者撰文
- Windows|微软正为Windows 11开发新Mica视觉效果
- 模型|神经辐射场去掉「神经」,训练速度提升100多倍,3D效果质量不减
- 硬件|瑞芯微智能视觉芯片RV1126荣获CPSE安博会最高殊荣:金鼎奖
- 检测|基于双目视觉的目标检测与追踪方案详解
- 训练|腾讯云副总裁吴运生:AI落地出现新变化,对细分行业需要深入理解
- 最新消息|视觉中国成立元视觉拍卖公司 注册资本5000万