尽管 MoE 层有很多参数 , 但专家是稀疏激活的 , 这意味着对于给定的输入 token , 只使用两个专家 , 这样做的优势是在限制计算的同时给模型提供更多的容量 。 在训练期间 , 每个 MoE 层门控网络都经过训练 , 使用它的输入来激活每个 token 的最佳两位专家 , 然后将其用于推理 。 对于 MoE 层的 E 专家来说 , 这本质上提供了 E×(E-1) 个不同前馈网络组合的集合 , 而不是经典 Transformer 中的一个组合 , 从而带来更大的计算灵活性 。
最终学习到的 token 表示来自两个专家输出的加权组合 , 这使得不同的专家可以激活不同类型的输入 。 为了能够扩展到更大的模型 , GLaM 架构中的每个专家都可以跨越多个计算设备 。 谷歌使用 GSPMD 编译器后端来解决扩展专家的挑战 , 并训练了多个变体(基于专家规模和专家数量)来了解稀疏激活语言模型的扩展效果 。
评估设置
谷歌使用 zero-shot 和 one-shot 两种设置 , 其中训练中使用的是未见过的任务 。 评估基准包括如下:
- 完形填空和完成任务;
- 开放域问答;
- Winograd-style 任务;
- 常识推理;
- 上下文阅读理解;
- SuperGLUE 任务;
- 自然语言推理 。
实验结果
当每个 MoE 层只有一个专家时 , GLaM 缩减为一个基于 Transformer 的基础密集模型架构 。 在所有试验中 , 谷歌使用「基础密集模型大小 / 每个 MoE 层的专家数量」来描述 GLaM 模型 。 比如 , 1B/64E 表示是 1B 参数的密集模型架构 , 每隔一层由 64 个专家 MoE 层代替 。
谷歌测试了 GLaM 的性能和扩展属性 , 包括在相同数据集上训练的基线密集模型 。 与最近微软联合英伟达推出的 Megatron-Turing 相比 , GLaM 使用 5% margin 时在 7 项不同的任务上实现了不相上下的性能 , 同时推理过程中使用的算力减少了 4/5 。
此外 , 在推理过程中使用算力更少的情况下 , 1.2T 参数的稀疏激活模型(GLaM)在更多任务上实现了比 1.75B 参数的密集 GPT-3 模型更好的平均结果 。
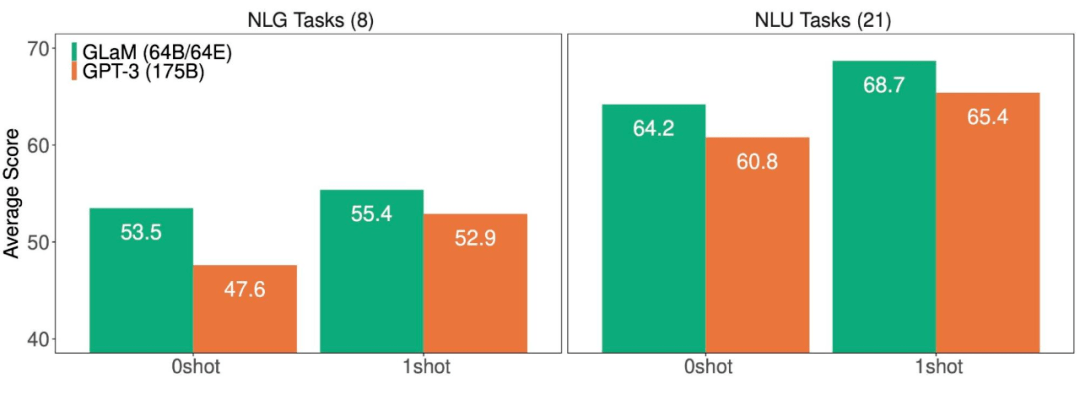
文章图片
NLG(左)和 NLU(右)任务上 , GLaM 和 GPT-3 的平均得分(越高越好) 。
谷歌总结了 29 个基准上 , GLaM 与 GPT-3 的性能比较结果 。 结果显示 , GLaM 在 80% 左右的 zero-shot 任务和 90% 左右的 one-shot 任务上超越或持平 GPT-3 的性能 。
推荐阅读







- IT|全球汽车行业价值两年突增至3万亿美元 中国电动车企立大功
- 水管|柔性泄水管概述、性能参数
- IT|配1.2L三缸发动机 百公里耗油仅3.9升:日产轩逸e-POWER正式交付
- the|反垄断下狂“敛财”?美国五大科技公司年营收有望达到9万亿
- 国计民生|25万亿级新蓝海!百度、华为、腾讯重磅出击,抢食智慧城市"大蛋糕",AI巨头如何赋能?来看真实案例
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- TSMC|万亿元投资 台积电要在台湾中科建厂
- 单元|深耕万亿城市AIoT市场,旷视如何发力城市大空间?
- 太阳能发电|我国新能源发电量年内首超一万亿千瓦时
- 方面|小米12 Pro将于12月28日发布,主要参数已确认,价格很感人!