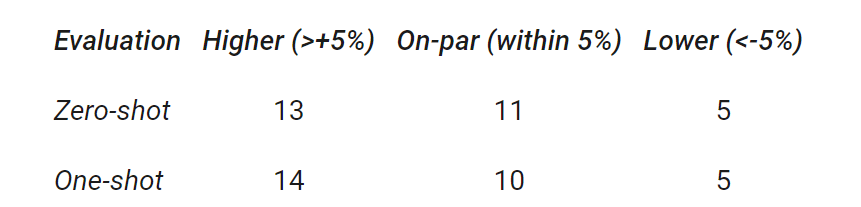
文章图片
此外 , 虽然完整版 GLaM 有 1.2T 的总参数 , 但在推理过程中每个 token 仅激活 97B 参数(1.2T 的 8%)的子网 。
文章图片
扩展
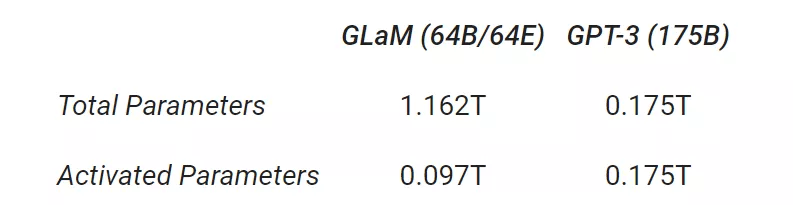
GLaM 有两种扩展方式:1) 扩展每层的专家数量 , 其中每个专家都托管在一个计算设备中;2) 扩展每个专家的大小以超出单个设备的限制 。 为了评估扩展属性 , 该研究在推理时比较每个 token 的 FLOPS 相似的相应密集模型 。
文章图片
通过增加每个专家的大小 , zero-shot 和 one-shot 的平均性能 。 随着专家大小的增长 , 推理时每个 token 预测的 FLOPS 也会增加 。
如上图所示 , 跨任务的性能与专家的大小成比例 。 在生成任务的推理过程中 , GLaM 稀疏激活模型的性能也优于 FLOP 类似的密集模型 。 对于理解任务 , 研究者观察到它们在较小的规模上性能相似 , 但稀疏激活模型在较大的规模上性能更好 。
数据效率
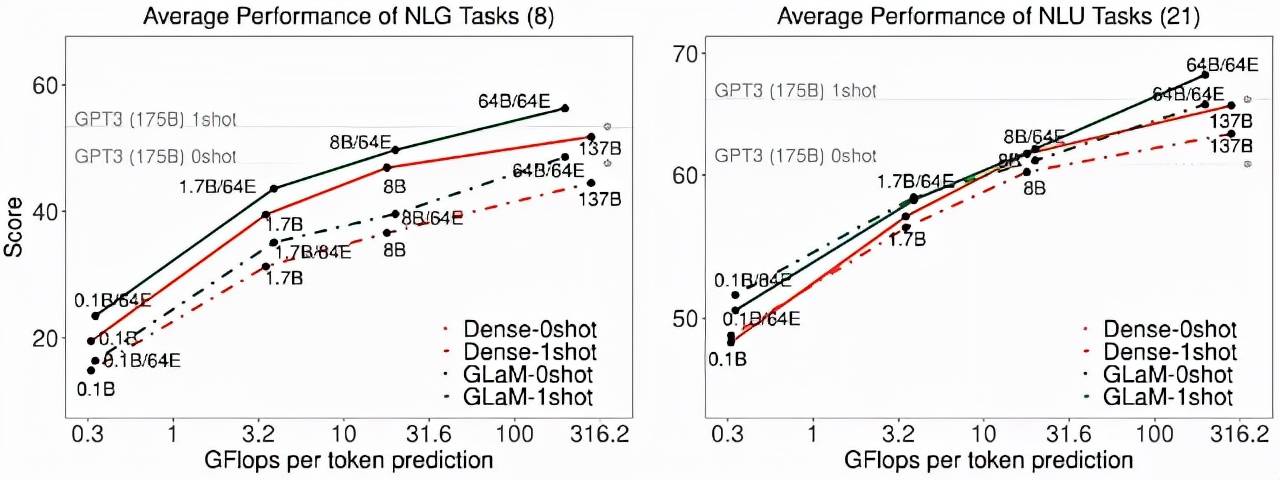
训练大型语言模型计算密集 , 因此提高效率有助于降低能耗 。 该研究展示了完整版 GLaM 的计算成本 。
文章图片
模型推理(左)和训练(右)的计算成本(GFLOPS) 。
这些计算成本表明 GLaM 在训练期间使用了更多的计算 , 因为它在更多的 token 上训练 , 但在推理期间使用的计算却少得多 。 下图展示了使用不同数量的 token 进行训练的比较结果 , 并评估了该模型的学习曲线 。
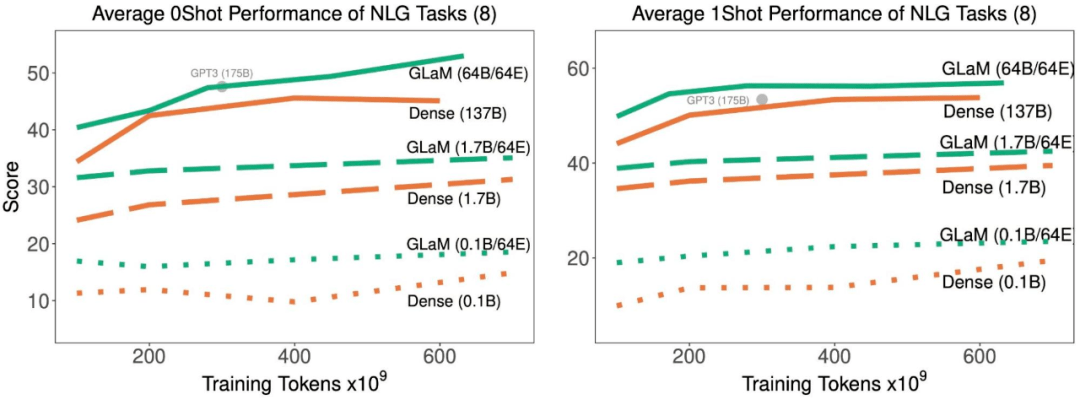
文章图片
随着训练中处理了更多的 token , 稀疏激活型和密集模型在 8 项生成任务上的平均 zero-shot 和 one-shot 性能 。
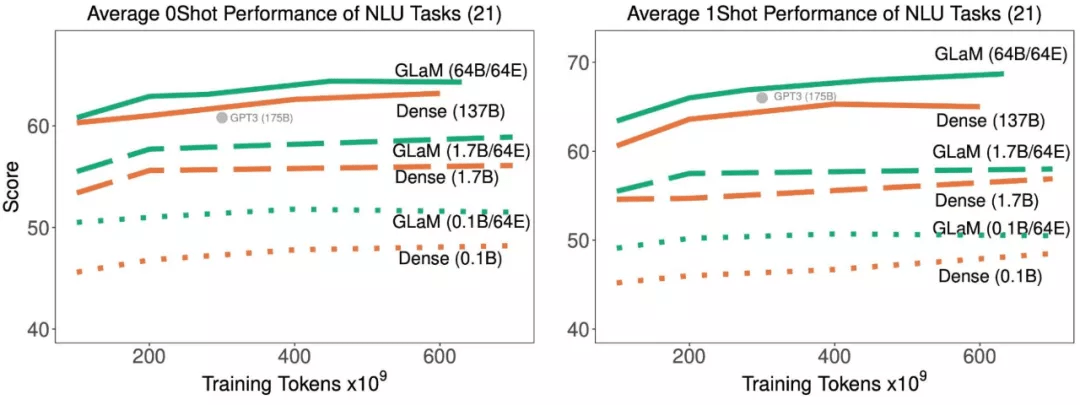
文章图片
随着训练中处理了更多的 token , 稀疏激活型和密集模型在 21 项理解任务上的平均 zero-shot 和 one-shot 性能 。
结果表明 , 稀疏激活模型在达到与密集模型相似的 zero-shot 和 one-shot 性能时 , 训练时使用的数据显著减少 。 并且 , 如果适用的数据量相同 , 稀疏型模型的表现明显更好 。
最后 , 谷歌对 GLam 的能效进行了评估:
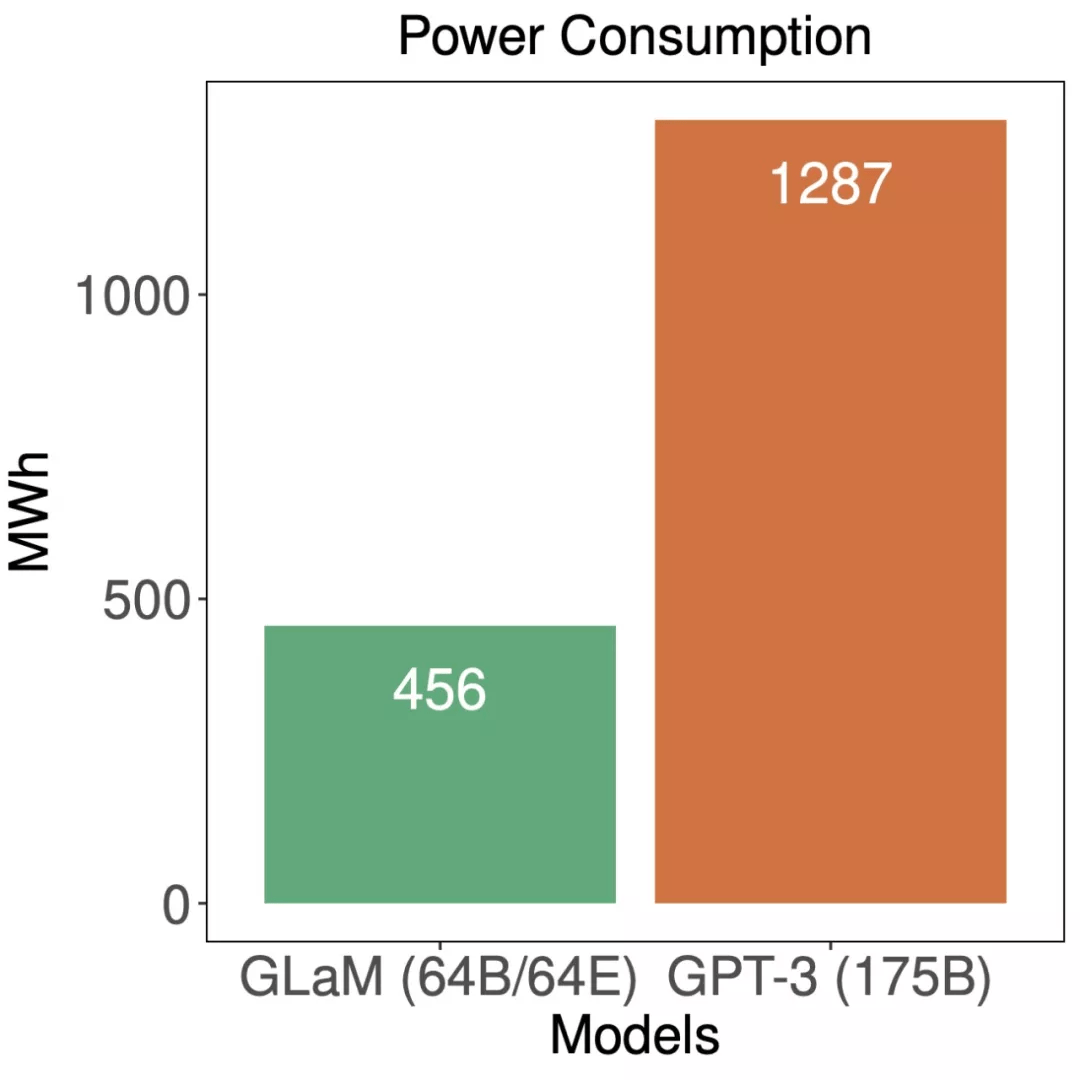
文章图片
训练期间 , GLaM 与 GPT-3 的能耗比较 。
虽然 GLaM 在训练期间使用了更多算力 , 但得益于 GSPMD(谷歌 5 月推出的用于常见机器学习计算图的基于编译器的自动化并行系统)赋能的更高效软件实现和 TPUv4 的优势 , 它在训练时耗能要少于其他模型 。
推荐阅读







- IT|全球汽车行业价值两年突增至3万亿美元 中国电动车企立大功
- 水管|柔性泄水管概述、性能参数
- IT|配1.2L三缸发动机 百公里耗油仅3.9升:日产轩逸e-POWER正式交付
- the|反垄断下狂“敛财”?美国五大科技公司年营收有望达到9万亿
- 国计民生|25万亿级新蓝海!百度、华为、腾讯重磅出击,抢食智慧城市"大蛋糕",AI巨头如何赋能?来看真实案例
- 参数|CELL+100 细胞制备隔离器,欢迎咨询
- TSMC|万亿元投资 台积电要在台湾中科建厂
- 单元|深耕万亿城市AIoT市场,旷视如何发力城市大空间?
- 太阳能发电|我国新能源发电量年内首超一万亿千瓦时
- 方面|小米12 Pro将于12月28日发布,主要参数已确认,价格很感人!