参数|AI大模型还能走多远?
51CTO.com原创稿件
编辑 | 51CTO技术栈·云昭
2021年是大模型层出不穷的一年 。 从去年 OpenAI GPT-3 发布开始 , 今年华为、谷歌、智源、快手、阿里、英伟达等厂商先后推出自己的大模型 , 人工智能产业开始了新一轮的激烈角逐 , 而且有愈演愈烈之势 。 作为探索通用人工智能的路径之一 , AI大模型不仅本身是一个可能产生原始创新与长期影响的领域 , 还将成为一个平台 , 催生更多世界级的成果 。
概述 自 2018 年 Bert 大模型 的横空问世以来 , 华为、阿里、腾讯、谷歌、微软、英伟达等国内外各巨头纷纷重兵投入打造自己的大模型 , 将其视为下一个 AI 领域的必争的高地 。
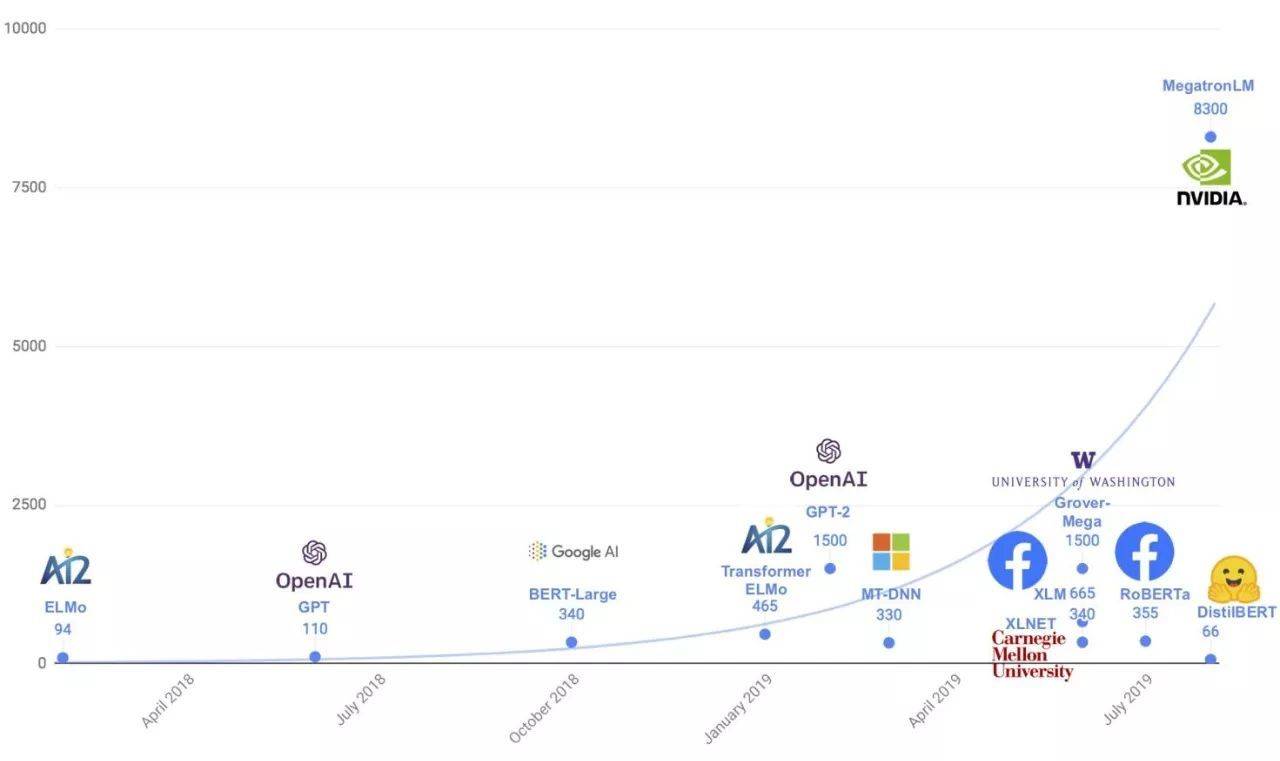
文章图片
如此百家争鸣 , 这背后一定有着深层次且必然的原因 。
众所周知 , “难以落地”已成为制约人工智能“技术上水平” , “应用上规模”,“产业上台阶”的最大瓶颈 。 而进一步深究 , 则是高昂的开发成本和技术门槛形成了一道无形的壁垒 , 使得技术链与产业链严重脱节 。
【参数|AI大模型还能走多远?】这种生态上的脱节 , 必然导致“小作坊式”的 AI 开发模式 。 这就意味着耗时耗力、复杂繁琐的数据的收集、标注和训练工作需要重新来过 , 无疑加重了开发者的负担 , 企业的应用成本也随之增高 。
而大模型的出现 , 意味着“工业化”开发模式的到来 。
得益于大模型的高泛化能力和高通用性 , 它能把 AI 开发重新整合建立起一套通用的“预训练大模型+下游任务微调”流水线 。 面对不同的应用场景 , 这套流水线可以得到有效复用 。 开发者只需要少量行业数据就可以快速开发出精度更高、泛化能力更强的AI模型 。
大模型发展现状 某种程度上看 , 大模型的规模发展速度似乎超过了摩尔定律 。 据统计 , 每年其参数规模至少提升 10 倍 。 2021 年 , 我们可以看到各大学术机构、科技企业都在投入重兵打造自己的大模型 , 并且对其能力边界、技术路径进行了极大拓展 。
1 月 , 谷歌发布人类历史首个万亿级模型 Switch Transformer 。
3月 , 北京智源研究院发布悟道1.0 , 6月发布悟道2.0 , 参数规模已经超过百亿 。
4月 , 华为云盘古大模型发布 , 这是业界首个千亿参数中文语言预训练模型 , 且并不仅仅局限于人工智能的某一个单独的领域比如自然语言处理NLP , 而是海纳百川 , 集AI多个热门方向于一身的全能型人工智能 。
7月 , 中科院自动化所也推出了全球首个三模态大模型:紫东·太初 。 其兼具跨模态理解和生成能力 , 可以同时应对文本、视觉、语音三个方向的问题 。
推荐阅读







- 苹果|关机后你的手机还能被定位,是真的咩?
- |电脑杀毒,原来还能“望闻问切”?
- 青少年|短视频外,科普还能怎么“普”?
- 功能|索尼公布了PSVR 2的技术参数,HTC将推出一款腕式追踪器 | VR一周要闻
- 直播|创作激励“姗姗来迟”,视频号“还能饭否”?
- AI|日本动漫AI让草图实时变身二次元人物 还有512种参数可调
- 参数|【相机】一亿两亿大像素方向错了吗?曝安卓机皇还会用
- 视点·观察|王老吉“改姓”:李老吉售价涨了1.5倍,凉茶还能变热?
- 媒体滚动|王老吉“改姓”:李老吉售价涨了1.5倍,凉茶还能变热?
- 微博|红米K50系列参数曝光,“祖传神U”又被抬出来了?!