参数|AI大模型还能走多远?( 二 )
8月 , 实验室已经宣布,将自研深度学习框架“河图”融入Angel生态,北京大学与腾讯团队将联合共建 Angel4.0 ——新一代分布式深度学习平台,面向拥有海量训练数据、超大模型参数的深度学习训练场景,为产业界带来新的大规模深度学习破局之策 。
9月 , 浪潮发布巨量模型“源1.0” , 参数量达2457亿 , 训练采用的中文数据集达5000GB , 相比于美国的 GPT-3 模型相比 , 源1.0参数规模领先40% , 训练数据集规模领先近10倍 。
11月 , 英伟达与微软联合发布了5300亿参数的“MT-NLG” 。
近日 , 阿里达摩院宣布其多模态大模型M6最新参数已从万亿跃迁至10万亿 , 规模超过了谷歌、微软此前发布的万亿级模型 , 成为全球最大的AI预训练模型 。
如果说参数的直观对比类似外行看热闹 , 那么 , 落地能力才是大模型实力的真正较量 。 目前 , 在落地层面 , 各大科技巨头都在进行了相关的落地探索 。
华为云盘古大模型在各行业应用方面 , 已经在能源、零售、金融、工业、医疗、环境、物流等行业的 100 多个场景实际应用, 让企业的 AI 应用开发效率平均提升了 90% 。
另外 , 阿里达摩院研发的 M6 , 拥有多模态、多任务能力 , 其认知和创造能力超越传统 AI ,目前已应用在支付宝、淘宝、天猫业务上 , 尤其擅长设计、写作、问答 , 在电商、制造业、文学艺术、科学研究等领域有广泛应用前景 。
值得注意的是 , 目前大模型更多的是离线应用 , 在线应用上 , 还需要考虑知识蒸馏和低精度量化等模型压缩技术、项目实时性等一系列复杂的项目难题 。
大模型的分类 1、按照模型架构划分:单体模型和混合模型 。 单体模型中比较出名的有:其中 OpenAI 推出的「GPT-3」、微软-英伟达推出的「MT-NLG」模型、浪潮推出的「源1.0」等 。 混合模型包括谷歌的「Switch Transformer」、智源研究院的「悟道」、阿里的「M6」、华为云的「盘古」等 。
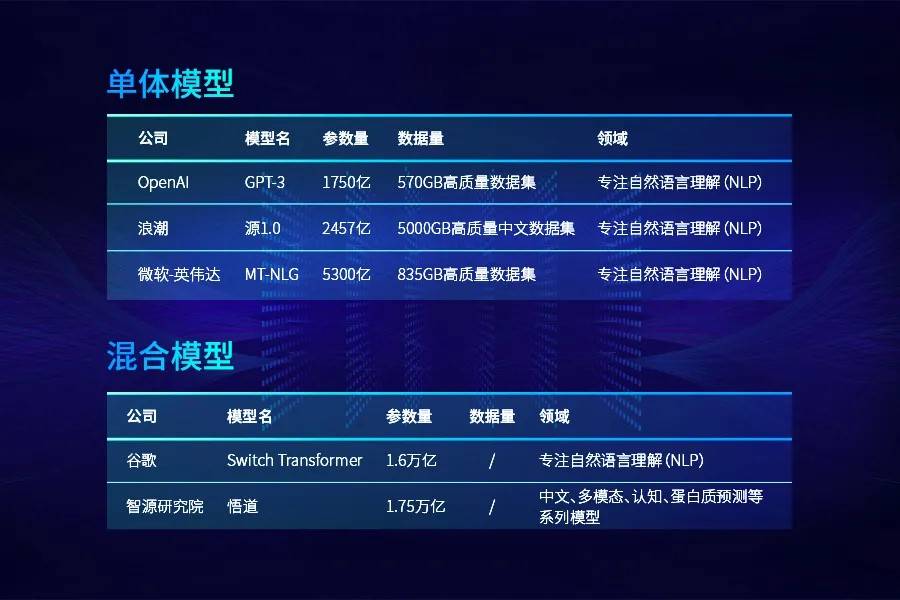
文章图片
其中 , 谷歌「Switch Transformer」采用 Mixture of Experts (MoE , 混合专家) 模式 , 将模型进行切分 , 其结果是得到的是一个稀疏激活模型 , 大大节省了计算资源 。
而智源「悟道2.0」1.75万亿参数再次刷新万亿参数规模的记录 , 值得关注的是它不再关注单一领域的模型开发 , 而是各种领域的融合系统 。
2、按照应用领域划分:目前 , 大模型的热门方向包括 NLP(中文语言)大模型、CV(视觉)大模型、多模态大模型和科学计算大模型等 。
目前 , 自然语言处理领域内热门单体大模型有:「GPT-3」、「MT-NLG」以及「源 1.0」等 。 惊喜的是 , 有研究表明 , 将 NLP 领域大获成功的自监督预训练模式同样也可以用在 CV 任务上 , 效果十分拔群 。
推荐阅读







- 苹果|关机后你的手机还能被定位,是真的咩?
- |电脑杀毒,原来还能“望闻问切”?
- 青少年|短视频外,科普还能怎么“普”?
- 功能|索尼公布了PSVR 2的技术参数,HTC将推出一款腕式追踪器 | VR一周要闻
- 直播|创作激励“姗姗来迟”,视频号“还能饭否”?
- AI|日本动漫AI让草图实时变身二次元人物 还有512种参数可调
- 参数|【相机】一亿两亿大像素方向错了吗?曝安卓机皇还会用
- 视点·观察|王老吉“改姓”:李老吉售价涨了1.5倍,凉茶还能变热?
- 媒体滚动|王老吉“改姓”:李老吉售价涨了1.5倍,凉茶还能变热?
- 微博|红米K50系列参数曝光,“祖传神U”又被抬出来了?!