By 超神经
内容提要:把影视剧变成漫画 , 是怎样的一种神操作?来自大连理工大学和香港城市大学的团队 , 最新提出的 AI 框架 , 可自动将影视剧转换为漫画 。 从此 , 观影追剧又多了一种打开方式 。
关键词:漫画生成系统 CNN 情感分析
如今 , 电影、电视剧以及各类视频 , 已经成为我们生活中不可缺少的一部分 。 据报告 , 每天上传到 YouTube 的视频总时长 , 就需要一个人花费超过 82 年的时间才能看完 。
为了节省追剧时间 , 2 倍速播放已经成为刷剧标配 。 除了倍速、跳跃式观看 , 以及看影评人讲解 , 还有一种快速追剧的方式 , 就是——把影视剧改成漫画 。
近日 , 大连理工大学和香港城市大学的研究人员 , 发布了一个有趣的研究 , 可以自动将电视剧、电影或其他视频的画面生成为漫画形式 , 并配上文字气泡 。
本文图片
本文图片
左右滑动查看《泰坦尼克号》、《风声》
《老友记》和《在云端》的漫画版本
研究人员在论文中表示:与最新的漫画生成系统相比 , 我们的系统可以合成更具表现力和吸引力的漫画 。 未来会将这一技术扩展到 , 利用文本信息生成漫画 。
看过漫改 , 但你看过改漫吗?
此前 , 业内已有一些类似的研究成果 , 提出将影片转换为漫画的自动化系统 , 但其在自动化和视觉效果、可读性等方面还有待提高 , 因此 , 这一研究方向仍然充满挑战 。
来自大连理工大学和香港城市大学的团队 , 则在最近发表的论文《Automatic Comic Generation with Stylistic Multi-page Layouts and Emotion-driven Text Balloon Generation》中 , 提出了更优的方法 。
本文图片
论文地址:https://arxiv.org/abs/2101.11111
论文中提出了一个全自动漫画生成系统 , 无需用户任何手动调整 , 就可以将任意类型的视频(电视连续剧、电影、卡通) , 生成高质量的漫画页面 , 将角色对话转化为气泡文字 。 而且该系统生成的漫画具有丰富的视觉效果 , 且可读性强 。
三大模块 , 让影视剧变漫画书
该论文中提出的关键思想是 , 在没有任何手动指定的参数或约束的情况下 , 以全自动的方式设计系统 。 同时 , 团队有选择地引入用户交互 , 使设计更加个性化和多样化 。
总体来看 , 该系统主要有三个模块 , 分别是:关键帧选择和漫画风格化、多页面布局生成、文字气泡生成和放置 。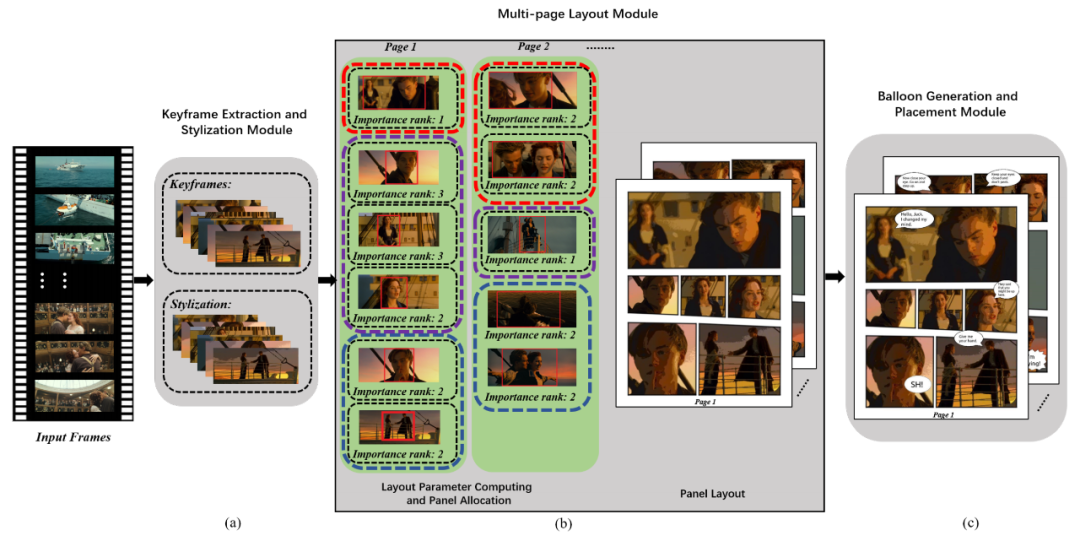
本文图片
系统整体的工作流程示意图
模块一:关键帧的提取和风格化
系统的输入是一段视频及其字幕 , 其中包含对话和相应的开始和结束时间戳信息 。
他们首先每 0.5 秒钟从原始视频中选择一帧 , 然后 , 利用字幕中的时间信息和两个连续帧之间的相似性 , 来选择信息关键帧 。 最后对关键帧进行风格化 , 也就是将普通图像转换为漫画风格的图像 。
关键帧提取
关键帧的选择是尤为重要且难度比较高的一项任务 , 该团队主要利用时间信息来进行选择 。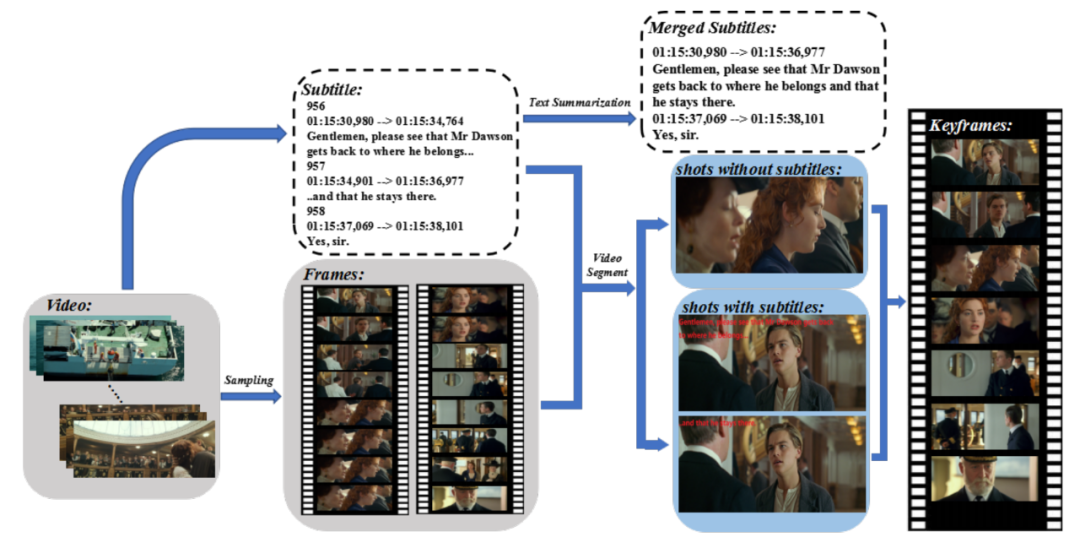
本文图片
关键帧选择流程
如上图所示 , 团队首先利用每个字幕的开始和结束时间将视频分割成多个镜头 , 这些镜头分两种:对话镜头(有字幕的镜头)和非对话镜头(无字幕的镜头) 。
对于对话镜头:系统会计算之前获得的两个连续帧之间的 GIST 相似度(如果 GIST 相似度较小 , 则两帧之间差异较大) 。
在执行过程中 , 如果相似度小于预先设置的阈值 ??1 , 那么后一帧将被选为关键帧 。 如果一组字幕对应的帧都没有被选中 , 就选取中间一帧作为关键帧 。
考虑到一个连续的对话和同一个场景可能对应多个字幕 , 因此团队会计算之前得到的连续关键帧之间的 GIST 相似度 。 如果相似度大于设置的阈值 ??2 , 就认为它们属于同一个场景 。 那么 , 就只保留其中一个关键帧 , 然后合并字幕 。
另外 , 在同一组字幕中 , 系统有可能选择多个关键帧 , 因为计算之后 , 可能发现这些关键帧具有语义关系 , 这些关键帧将用于多页布局 。
对于非对话的镜头:系统会首先选择与当前镜头中的帧最不相同的帧 。 为了减少选取帧的冗余 , 系统会计算这个镜头与之前选择的关键帧的 GIST 相似度 , 只有小于之前设定的阈值 , 才会被选为关键帧 。
最后 , 通过比较开始时间戳和关键帧的时间戳 , 将字幕集分组 。 在关键帧的开始和结束时间戳范围内的任何字幕 , 都将被收集在一起 。
画面风格化
团队采用了扩展的高斯差法 , 将源图像转换为黑白图像 。 饭后执行 128 级颜色量化 , 得到量化后的图像 , 实现彩色风格化 。 就是这样 , 一组组真人电影镜头 , 变成了漫画风格 。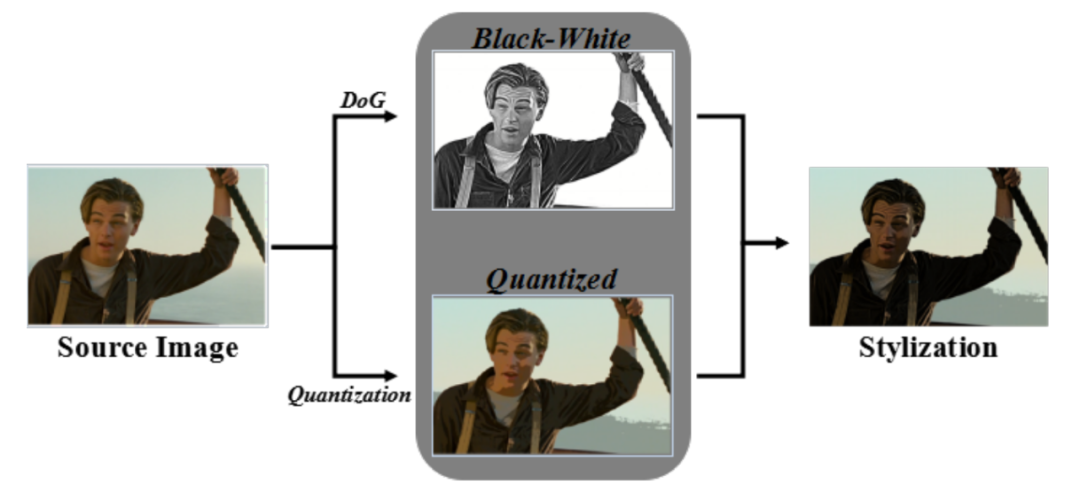
本文图片
模块二:多页面布局
团队提出了一个多页布局框架 , 用来自动分配和组织页面的布局 , 同时能够呈现出更加丰富的视觉效果 。
在这一模块中 , 首先需要计算出四个用于指导多页面布局生成的关键因素 , 包括:关键帧的兴趣区域(ROI)、关键帧的重要性等级、关键帧之间的语义关系和一个页面上的面板数量 。
然后 , 团队提出了一种基于优化的面板分配方法 , 将关键帧分配到一个页面序列中 , 并使用数据驱动的漫画式布局合成方法 , 来生成每个页面的布局 。
追漫的小伙伴都知道 , 漫画书中每一页的分格数量都是不固定的 , 为了让读者有更好的阅读体验 , 漫画家都会根据剧情来安排分格数量 。
在此项研究中 , 团队将这一问题作为全局的优化问题 , 来完成每个镜头在漫画页面中的分配 。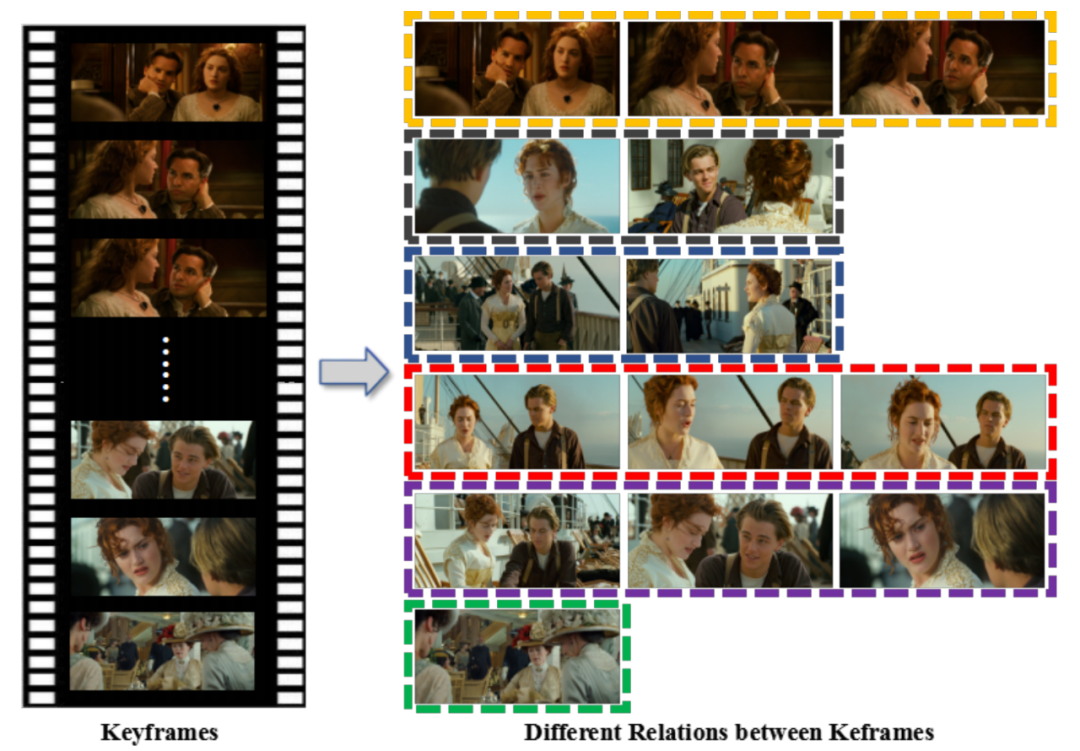
本文图片
关键帧之间的关系分析:
同一颜色虚线框内的关键帧具有语义关系 , 反之则不具有
模块三:文字气泡的生成和放置
文字气泡的生成
通常在漫画中 , 对于不同情境与情感下的对话 , 作者也会选择不同的气泡形状 , 这对于漫画内容的表达非常重要 。 而现有的相关研究一般都是只使用基本的椭圆式气泡形状 , 这对于情感表达来说显得不够丰富 。
本文则提出的一项重要成果 , 即一种基于情感感知的气泡生成方法 , 可利用含有情感的视频音频和字幕信息 , 生成与之相适应的文字气泡形状 。
本文图片
系统根据输入视频对应音频和字幕 , 分析其中包含的情感
然后生成对应气泡形状
在该系统中 , 作者采用了三种常见的气泡形状:椭圆形气泡、思想气泡和锯齿状气泡 。 这三种气泡适用的感情分别为:情绪平静、想法(不说出来)、感情强烈 。
对于气泡分类器的训练 , 团队主要利用一些动漫视频和相应的漫画书 , 来收集音频情感、字幕情感和气泡类型的数据 。
气泡定位与放置
与之前方法类似 , 本文也采用了发言人检测和唇动检测 , 来获取说话的人在一帧中的位置 , 然后将气球放置在其所属的人物附近 。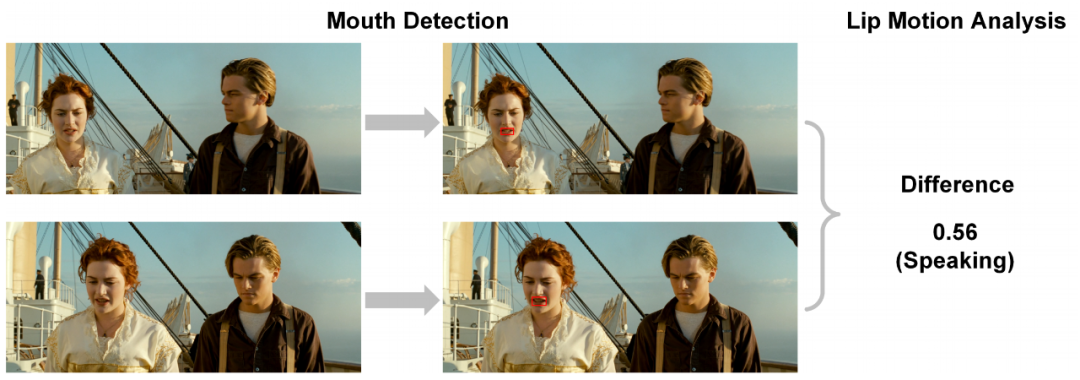
本文图片
嘴部检测+唇动检测 , 定位讲话者
具体执行流程为:
首先使用Dlib人脸检测 Python 库 , 来检测一帧中每个人物的嘴部;
然后利用唇动分析 , 计算连续两帧帧间嘴部区域像素值的均方差 , 该差值是在当前帧中嘴巴区域周围的搜索区域上计算的 , 以确定其嘴唇是否有动作;
最后 , 设置一个阈值来确定某角色是否在说话 。
在得到发言者的位置后 , 将文字气泡放在其附近 , 并将气泡的尾部指向讲话者的嘴巴 。
用四部经典影片 , 评估系统效果
为测试模型效果 , 团队输入了 4 部不同影片的共 16 个片段 , 包括:《泰坦尼克号》、《风声》、《老友记》和《在云端》 。
输入视频的持续时间从 2 分钟到 6 分钟不等 , 每一段剪辑都包含有台词的部分 。
对于每个剪辑 , 团队记录使用该系统生成一本漫画书所消耗的时间 , 并计算平均消耗的时间 , 来评估系统性能 。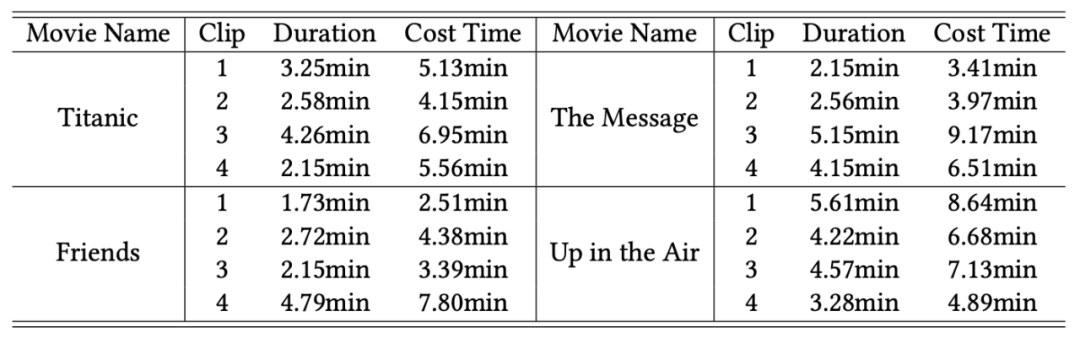
本文图片
每段视频生成漫画时间不超过 10 分钟
作者总结道 , 与之前方法相比 , 本研究的方法优于其它方法 。 主要体现在以下三个方面:
首先 , 该系统可以为对话生成更丰富的气泡形状 , 而现有的方法只使用单纯的椭圆词气球;
其次 , 利用文本总结的方法 , 将一些相关的字幕进行合并 , 这样可确保文字气泡中的句子不会太长 , 增强可读性;
第三 , 通过自动获取四个重要参数 , 来实现全自动多页布局(此前方法多为半自动 , 需人工干预) , 且布局结果合理、丰富 。
本文图片
效果展示与对比 。 其中 , (a)-(d) 为该团队的系统生成效果;(e)-(h) 为另一团队在 2015 年发表的成果
对应电影依次为:《泰坦尼克号》、《风声》、《老友记》和《在云端》
为了避免主观因素干扰 , 团队还通过 Amazon Mechanical Turk 招募了 40 名志愿者 , 对团队的生成结果和其他同类系统生成的结果进行比较 。
志愿者首先会观看原视频 , 然后阅读各种不同方法生成的漫画 , 给出效果评级 。 为了避免主观偏见 , 视频和相应的漫画都是随机排列的 。
最终结果是 , 无论志愿者之前是否看过视频 , 该系统获得的评价都比其他方法更好 。
一键生成漫画 , 还能怎么玩?
虽然已经取得用户好评 , 但该系统当然称不上完美 , 仍有一些问题待解决 。
比如 , 对于关键帧的选择 , 仍然可能有相似度过高的情况出现 , 这会带来画面的冗余 。
另外 , 如果输入的视频没有字幕 , 那么在生成漫画之前 , 系统还要首先通过语音识别来提取台词 , 但是语音识别的结果往往容易出现错误 , 因此这也是该系统面临的一个挑战 。 不过 , 团队表示 , 相信随着语音识别技术的不断进步 , 这一问题未来也将迎刃而解 。
未来 , 当这一技术足够成熟 , 很多视频作品都会多一种打开方式 , 用漫画的形式来观看一部影片 , 对于读者来说 , 或许会带来更丰富的想象空间 。
本文图片
不同于视频 , 漫画的画面都为静态 , 且文字较少
但正因如此 , 读者得以加入更多个人情感与想象
【漫画|没时间看电影追剧,AI 一键让影视变漫画】此外 , 对于普通人来说 , 不需具备绘画功底 , 就能轻松将视频转换为漫画 , 这或许也会像此前能将照片转换为绘画风格图像的 Prisma App 一样 , 成为新的大众娱乐工具 。
而团队还计划 , 下一步将这一方法扩展到利用文本信息来生成漫画 。 也就是说 , 只要给出漫画剧本 , 系统就能够自动生成漫画 , 为漫画师节省大量时间 。
本文图片
漫画追剧 , 岂止是 2 倍速
编辑:CHANchan
推荐阅读







- AMD|AMD 350亿美元收购赛灵思交易完成时间推迟 预计明年一季度完成
- Apple|摩根大通分析师:交货时间来看iPhone 13系列已达供需平衡
- Microsoft|微软推Viva Insights插件 定时邮件可根据时区推荐发送时间
- 能力|有了长续航的独立通信手表,就不必为出门没带手机而焦虑了
- 认识论|管理好时间,是最有价值的投资
- 地球|没有了人类,地球气候环境会怎样|澎湃问吧年度盘点(上)
- 新闻|(暂不发)2021新闻年历|你不停翻着新闻,寻找时间的故事
- Foxconn|印度富士康工人条件有多恶劣?工资九百、没有马桶、食物有虫
- 马斯克|星链卫星乱窜致中国空间站紧急避险!马斯克:没阻止任何人
- 视点·观察|起底张庭夫妇公司:两个月办一次“洗脑”活动 有人5年没挣钱