user_id|滴滴 x StarRocks:极速多维分析创造更大的业务价值( 四 )
5、创建bitmap_union物化视图提升查询速度 , 实现count(distinct)精确去重:
由于用户想要在漏斗模型上查看一些城市用户转化情况 。
查询一般为:
select city_id, count(distinct new_user_id) as countDistinctByID from fact_log_user_doris_table where `dt` >= '2021-08-01' AND `dt` <= '2021-08-07' AND `city_id` in (11, 12, 13) group by city_id
针对这种根据城市求精确用户数量的场景 , 我们可以在明细表fact_log_user_doris_table上创建一个带 bitmap_union 的物化视图从而达到一个预先精确去重的效果 , 查询时StarRocks会自动将原始查询路由到物化视图表上 , 提升查询性能 。 针对这个case创建的根据城市分组 , 对user_id进行精确去重的物化视图如下:
create materialized view city_user_count as select city_id,bitmap_union(to_bitmap(new_user_id)) from fact_log_user_doris_table group by city_id;
在StarRocks中 , count(distinct)聚合的结果和bitmap_union_count聚合的结果是完全一致的 。 而bitmap_union_count等于bitmap_union的结果求 count , 所以如果查询中涉及到count(distinct) 则通过创建带bitmap_union聚合的物化视图方可加快查询 。 因为new_user_id本身是一个INT类型 , 所以在 StarRocks 中需要先将字段通过函数to_bitmap转换为bitmap类型然后才可以进行bitmap_union聚合 。
采用这种构建全局字典的方式 , 我们通过每日凌晨跑Spark离线同步任务实现全局字典的更新 , 以及对原始表中 Value 列的替换 , 同时对Spark任务配置基线和数据质量报警 , 保障任务的正常运行和数据的准确性 , 确保次日运营和市场同学能看到之前的运营活动对用户转化率产生的影响 , 以便他们及时调整运营策略 , 保证日常运营活动效果 。
最终效果及收益
经过产品和研发同学的共同努力 , 我们从需要查询的城市数量、时间跨度、数据量三个维度对精确去重功能进行优化 , 亿级数据量下150个城市ID精确去重查询整体耗时3秒以内 , 以下是漏斗分析的最终效果:
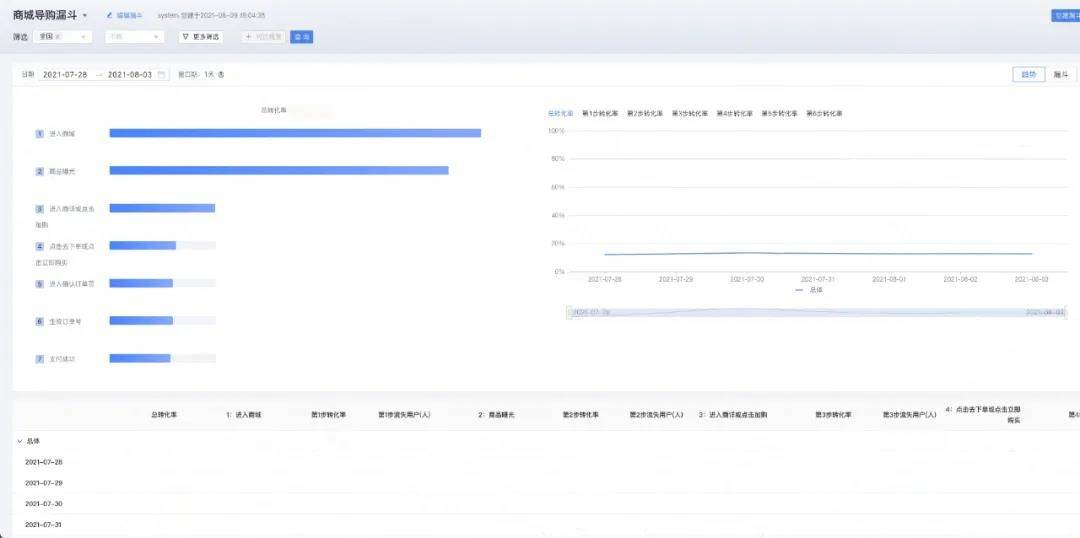
文章图片
未来规划
1.完善StarRocks内部工具链的开发 , 同滴滴大数据调度平台和数据开发平台整合 , 实现MySQL、ES、Hive等数据表一键接入StarRocks 。
2.StarRocks流批一体建设 , 由于StarRocks提供了丰富的数据模型 , 我们可以基于更新模型和明细模型以及物化视图构建流批一体的数据计算与存储模型 , 目前正在方案落地阶段 , 完善后会推广到橙心各个方向的数据产品上 。
3.基于StarRocks On ElasticSearch的能力 , 实现异构数据源的统一OLAP查询 , 赋能不同场景的业务需求 , 加速数据价值产出 。
后续我们也会持续关注StarRocks , 在内部不断的升级迭代 。 期待StarRocks能提供更丰富的功能 , 和更开放的生态 。 StarRocks后续也会作为OLAP平台的重要组件 , 实现OLAP层的统一存储 , 统一分析 , 统一管理 。
推荐阅读







- 警告!|华为联想卷入滴滴高管千万受贿案 判决书曝光浪潮曾向其输送720多万
- IT|滴滴被“围剿”三个月:Q3经调整EBITA由盈转亏 订单量、交易额均下滑
- IT|滴滴三季度收入427亿元环比降13%,投资亏损208亿元
- 注销|中消协点名推荐退订"问题" APP 含曹操出行翼支付滴滴
- join|ClickHouse vs StarRocks选型对比
- 视点·观察|仅156天!滴滴股价腰斩,再赴港上市之路怎么走?
- the|美股周五:特斯拉跌逾6% 滴滴大跌超22%
- 视点·观察|美股退市上港股 滴滴还有劲折腾么?
- IT|投资者割肉止损 滴滴股价跌超22%
- app|滴滴旗下滴滴加油、DiDi-Rider恢复上架?两款App并未下架过