文章图片
论文内容介绍
该论文介绍了如何通过具有单个实值参数的标量函数(连续、可微...)来近似化任何不同模态(时间序列、图像、声音...)的数据集 。 基于混沌理论的基本概念 , 研究者采用教学(pedagogical)方法来演示如何调整这个实值参数 , 以实现对所有数据样本的任意精度拟合 。
现实世界的数据有各种各样的形状和大小 , 其模式包括从传统的结构化数据库模式到非结构化媒体源 , 如视频源和录音 。 然而 , 任何数据集最终都可以被认为是一个数值列表 X = [x_0, · · · , x_n], 该列表描述了数据内容而忽略了数据底层模态 。 并且该论文旨在证明任何数据集 X 的所有样本都可以通过一个简单的微分方程重现:

文章图片
其中 α ? R 是要从数据中学习的实值参数 , x ? [0, · · · , n] 取整数值 。 (τ ? N 是一个常数 , 可有效控制所需的准确率) 。 按照「拟合大象」的传统 , 该研究首先展示了如何通过选择合适的α值生成不同的动物形状 , 如图 1 所示 。

文章图片
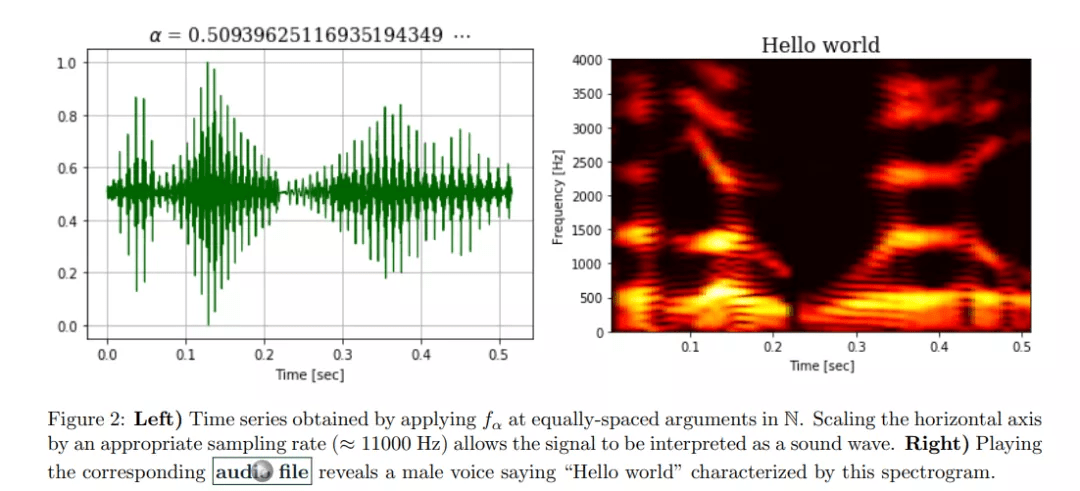
在演示完 f_α 可以生成任何类型的上述涂鸦绘图之后 , 该论文继续使用文字「Hello world」进行了展示 , 以进一步说明该方法的功能 。 下图 2 展示了如何使用精心选择的 α 值来生成复杂的高维声学信号 , 编码实际表达的是「Hello world」 。
文章图片
在图像这种数据模态上 , 随着专用硬件和新型神经网络架构的不断涌现 , 人们普遍认为可用的大规模标记训练数据已成为促使计算机视觉「成熟」的最重要因素之一 。
在这种情况下 , CIFAR-10 数据集被认为是衡量新学习算法性能的有力标准 。 该研究表明:如下图 3 所示 , 总是能够找到一个α值 , 使得 f_α能够构建出反映 CIFAR-10 类别的人工图像 。

文章图片
基于上述几个模态的例子 , 该论文得出结论:一个具有简单且可微公式的模型 f_α能够产生任何类型的语义相关散点图、音频或视觉数据(文本也类似) , 而只需要单个实值参数 。 这一点就引起了研究者们的质疑 。
此外 , 该论文中阐述了该方法无法实现泛化的事实 。 这是因为该方法中所有信息都是被直接编码的 , 没有任何的压缩或「学习」 。 从数学的角度看 , 实数有无限多个 , 因此不应与编程语言实现的有限精度的数据类型混淆 。 基于此 , f_α不可能实现真正的泛化 , 下图 9 就是一个例子 。
推荐阅读







- MateBook|深度解析:华为MateBook X Pro 2022的七大独家创新技术
- 问答|紧追B站加码知识类内容,抖音上线“学习频道”
- Siamese|一个框架统一Siamese自监督学习,清华、商汤提出简洁、有效梯度形式,
- 技术|探秘AI智慧之旅,科大讯飞AI学习机研学游第一期圆满落幕
- 人物|最有深度的8个公众号,你关注了吗
- 材料|别在玩吃鸡,小学生都开始学习3d打印技术了
- 字节跳动|抖音上线学习频道,为知识内容增加一级入口
- 数据|抖音上线学习频道,位于一级入口
- 国际|特奖得主任队长,清华夺冠NeurIPS 2021国际深度元学习挑战赛
- 深度|小米真无线降噪耳机 3 Pro 新年特别版即将发布,带来全新配色等