机器之心报道
编辑:蛋酱
多模态理解领域的权威排行榜纪录 , 又被来自国内的技术团队刷新了 。近日 , 多模态理解领域国际权威榜单 VCR(视觉常识推理 , Visual Commonsense Reasoning)刷新了排名 , 来自国内短视频平台快手研究团队MMU(Multimedia understanding)自研的 VLUA 多模态模型以两个单项成绩「82.3、87.0」和总成绩「72.0」的分数登上榜首 。
文章图片
快手自研 VLUA 多模态模型登顶 VCR 榜单 。
近年来 , 多模态理解技术在视频内容社区、电商等领域有着广泛的应用场景 , VCR 榜单由华盛顿大学等研究机构于 2018 年发起 , 基于大规模图文多模态数据集 , 旨在将图像和自然语言理解二者结合 , 验证多模态模型高阶认知和常识推理的能力 , 让机器拥有「看图说话」的能力 , 是多模态理解领域最权威的排行榜之一 。
VCR 任务设置了问答 (question answering) 和解释 (rationale) 两个子任务 。 具体而言 , 在问答任务中 , 给定一张图片 , 计算机要回答一个用自然语言描述的和图片相关的问题;在解释任务中 , 计算机将在给出答案的基础上 , 给出为什么选择这个答案的原因 。

文章图片
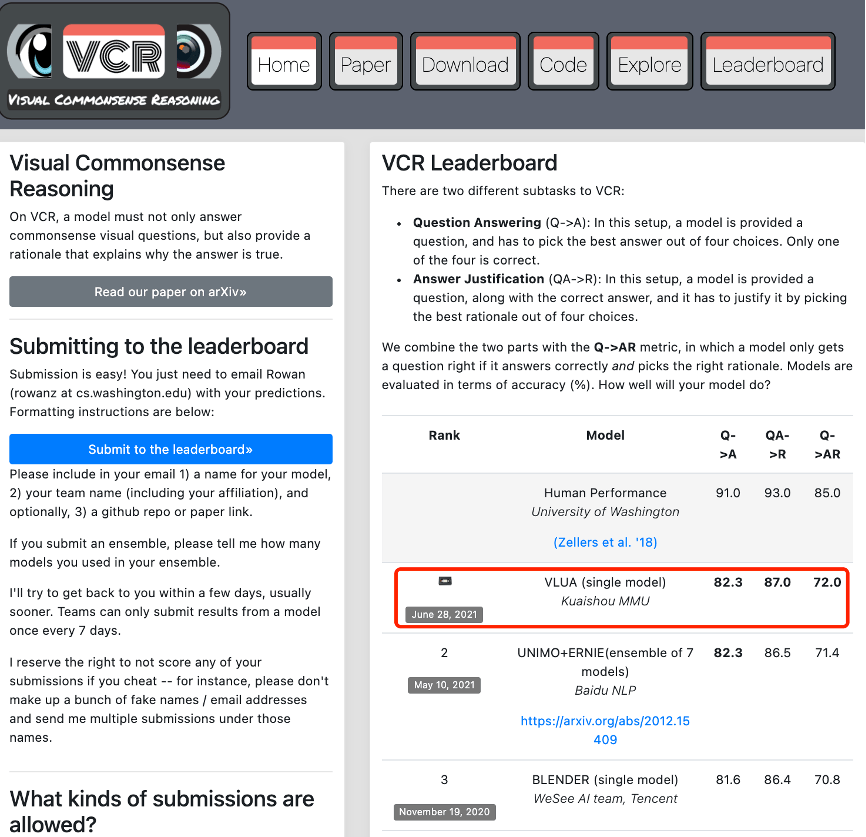
比如在上图示例中 , 第一轮需要选出「person 4 为什么指着 person 1」的答案 , 第二轮则需要解释选择的理由 。
一直以来 , 国内外众多企业和学术机构都围绕这一领域开展了深入的研究工作 。 因此 , 榜单自发布起成绩不断被刷新 , 来自百度、腾讯、英特尔、卡内基梅隆大学、加州大学伯克利分校等企业和研究机构都在围绕榜单做技术探索 。
文章图片
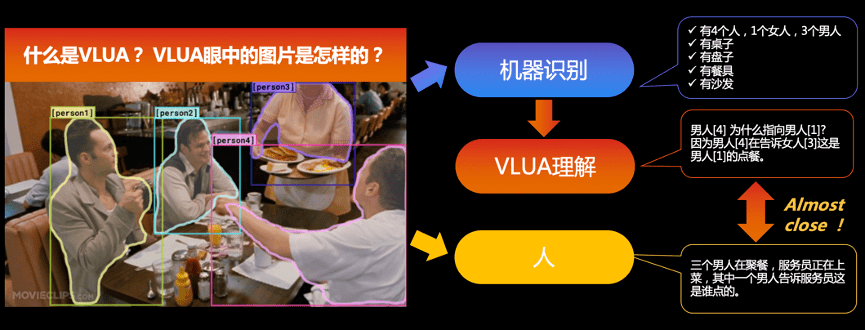
如图所示 , 分别为机器眼中的世界、人眼中的世界 , 以及通过 VLUA 后机器眼中世界的变化 。
快手自研 VLUA , 有何过人之处?
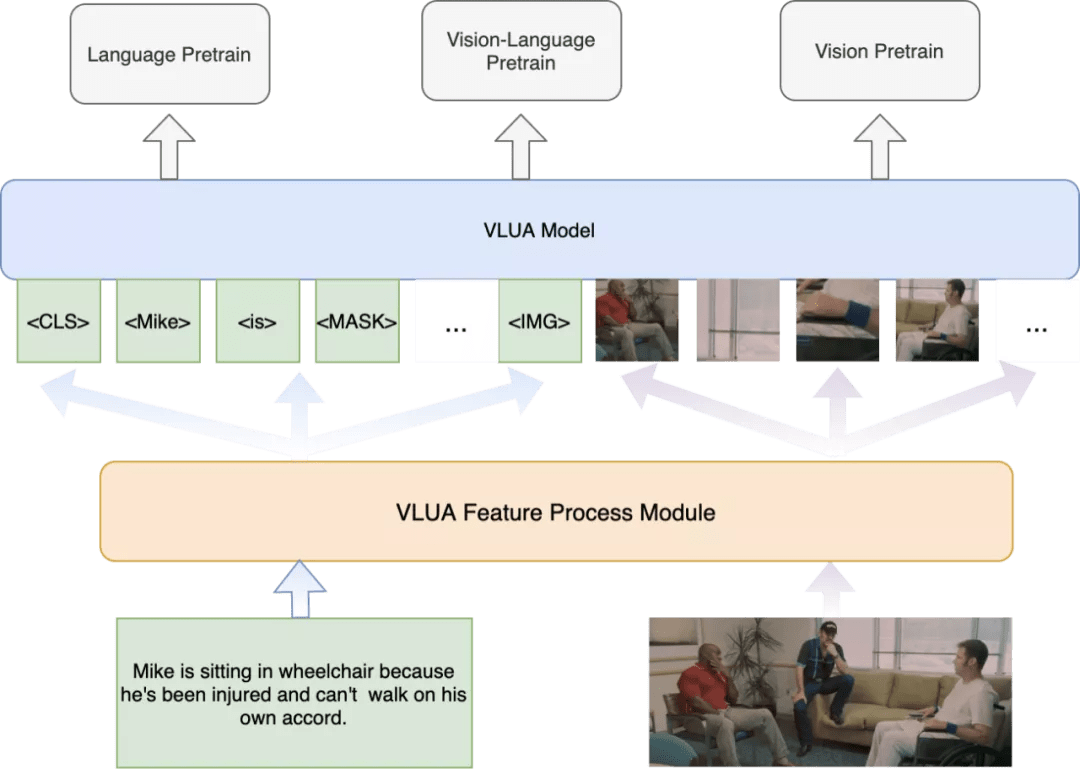
快手团队自主研发的 VLUA(Vision and Language Understanding via a Unified Architecture)多模态算法模型采用单流的 transformer 结构 , 针对视觉特征和文本特征输入的多样性 , 设计了统一的多模态特征处理模块 , 构建了图像背景和前景的信息互补策略 , 支持局部、全局、浅层、高层等各个维度的特征抽取 。
文章图片
相比目前主流的多模态算法模型 , VLUA 设计了自适应的预训练任务范式单元 , 不仅能够支持多模态混合训练 , 也能够支持单模态的独立训练 。 预训练任务上包含文本预训练任务、视觉预训练任务及跨模态对比学习 , VLUA 改进了模型的训练流程 , 通过隐性地引入代表图像全局的抽象信息以及多任务学习 , 使得模型可以从不同视角学习数据的特征 , 从而避免模型陷入局部最优解和过拟合 。 在训练方式上 , VLUA 使用了噪声对抗学习 , 进一步提高了模型的鲁棒性 。
快手研究团队将基于大规模图文多模态和单模态数据训练得到的 VLUA 预训练模型在 VCR 数据集上进行迁移学习 。 现有的 VCR 方法均使用 BUTD 算法提取的前景特征作为视觉特征 , 除了前景信息 , 快手的研究者们认为背景信息对于理解图片内容也具有至关重要的作用 。 在实践中 , VLUA 使用网格特征对图片的整体信息进行提取 , 让模型可以更好地理解图片内容 。
VLUA 通过统一化的输入特征及模型架构设计 , 不仅能够支持视觉、文本模态的融合 , 也支持音频、用户行为等更多跨域的模态特征融合 。 除了能够应用在视觉常识推理的任务上 , VLUA 在视觉问答 , 跨模态检索、caption 生成等任务上都能够快速的迁移及获得效果的提升 , 最终以「82.3,87.0,72.0」的成绩登顶 VCR 榜单 。
世界纪录背后 , 是一支什么样的队伍?
VLUA 来自快手的 MMU(Multimedia understanding)团队 。 作为国民级的短视频社区平台 , 快手每天有海量的短视频上传、直播开播 , MMU 是快手的核心的 AI 技术团队 , 使命是通过多模态内容理解技术 , 让机器像人类一样理解视频内容及用户生产的各种内容 , 理解内容后会应用在搜索、推荐、广告、垂类运营、生态分析、内容安全等多个场景 。

文章图片
面向快手生态下内容的规模庞大、多模态、高实时性、形式丰富等多种特点 , MMU 在多个技术领域广泛布局 , 比如视觉方向 , 在视频、直播、图像的分析和理解、视觉检索、视频生成等技术上有成熟应用和投入;音频方向 , 在语音识别 & 合成、音乐理解与生成、音频前端与分类等技术上达到行业先进水平 , 同时也有知识图谱、NLP、智能创作、内容商业价值理解等多种能力 , 为实现跨模态内容理解奠定坚实基础 。
目前 , VLUA 已应用于快手视频审核、推荐、搜索、创作等多个业务场景 , 能够根据应用场景的不同灵活的产出子模型及不同维度的多模态特征 。
- 在视频审核业务中 , 基于 VLUA 产出的视频内容质量理解模型将视频内容质量进行分层 , 精确的识别了劣质视频和优质视频 , 极大了提升了视频审核的效率和社区内优质内容的供给;
- 在视频推荐业务中 , 以冷启动场景为例 , 基于 VLUA 产出的多模态内容理解特征 , 大幅提升了冷启动的效率 , 帮助更多的优质内容及优质作者在社区内获得更好的成长;
- 在视频搜索场景 , 通过 VLUA 提供的视觉文本对齐的多模态特征 , 大幅提升了搜索召回的相关性;
- 在视频创作方面 , 通过 VLUA 对视频多模态信息实现高层次的理解 , 为智能创作过程提供更加精准的素材检索能力 , 提升生成内容的流畅性及可读性 。 例如在直播场景 , 定位直播中的精彩片段 , 混剪形成有趣、高密度的短视频;在商业化场景 , 通过分析广告主广告素材或者挖掘站内优质素材 , 混剪形成新的创意广告 , 丰富广告数量 。
如果你也希望和这些业内顶尖的技术人才共事 , 并且向往简单、开放、追求卓越的技术氛围 , 欢迎加入快手MMU团队 , 成为人工智能领域的探索者和先行者 。
【视频|再次刷新单模型纪录!快手登顶多模态理解权威榜单VCR】招聘邮箱:zhangyelingmei@kuaishou.com
推荐阅读







- 手机|一加10 Pro宣传视频曝光:将于1月11日14点发布
- 语境|B站2021个人年度报告发布:你共计看了多少个视频
- 部落|excel固定显示行列视频:应用冻结窗格同时固定标题行和列
- 入口|微信迎来新变革:保护隐私,增加视频号入口
- 果君|华为Mate X2 典藏版竟逼疯整个摄制组?拯救手滑的神器终于来了(视频)
- 模拟|(图文+视频)C4D野教程:Windows11的壁纸动效是如何制作的?
- IT|美FAA正在调查一段有争议的坠机视频
- 文化|“视频会员”的意义,藏在腾讯视频VIP九周年里
- IT|TuSimple半挂卡车道路全无人驾驶视频公布:全长130千米
- 视频网站|会员费涨价后还呼吁电影票要涨价 爱奇艺股价大跌创新低