另外一个与该研究较相关的是 MPI(Multiplane Image)[1, 2, 3] 。 MPI 包含了多个平面的 RGB-alpha 图片 , 其中每个平面表达场景在某个深度中的内容 , 它的主要缺点在于深度是固定及离散的 , 这个缺点限制了它对三维空间的表达能力 。 [1, 2, 3] 都能方便地泛化到不同的场景 , 然而 MPI 各个平面的深度是固定且离散的 , 这个缺点严重限制了它的效果 。

文章图片
方法综述
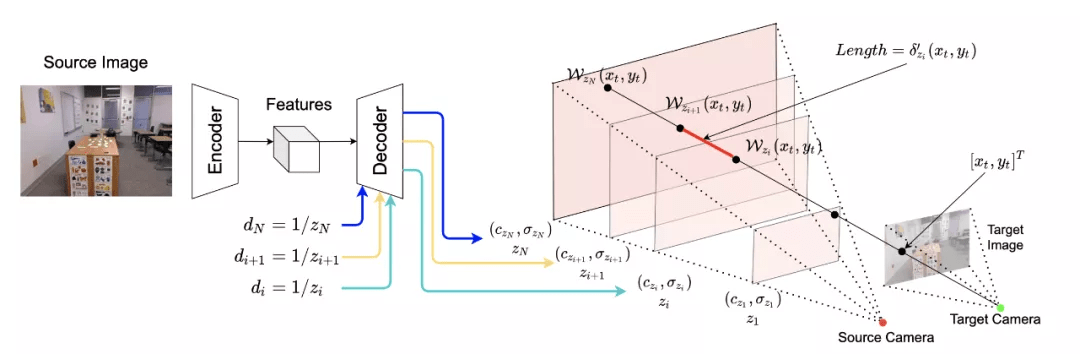
该团队采用一个 encoder-decoder 的结构来生成三维表达:
- Encoder 是一个全卷积网络 , 输入为单个 RGB 图片 , 输出为 feature maps;
- Decoder 也是一个全卷积网络 , 输入为 encoder 输出的 feature map , 以及任意深度值(repeat + concat) , 输出该深度下的 RGB-sigma 图片;
- 最终的三维表达由多个平面组成 , 也就是说在一次完整的 forward 中 , encoder 需要 inference 一次 , 而 decoder 需要 inference N 次获得个 N 平面 。
文章图片
获得三维表达后 , 不再需要任何的网络 inference , 渲染任意 target 相机 pose 下的视角只需要两步:
- 利用 homography wrapping 建立像素点间的 correspondence 。 可以想象 , 从 target 相机射出一条光线 , 这条光线与 target 图片的一个像素点相交 , 然后 , 研究者延长这条射线 , 让它与 source 相机视锥的各个平面相交 。 相交点的 RGB-sigma 值可以通过 bilinear sampling 获得;
- 利用 volume rendering 将光线上的点渲染到目标图片像素点上 , 获得该像素点的 RGB 值与深度 。

文章图片
MINE 可以利用 structure-from-motion 计算的相机参数与点云进行场景的学习 , 在这种情况下 , 深度是 ambiguous 的 。 由于在这个方法中 , 深度采样的范围是固定的 。 所以需要计算一个 scale factor , 使网络预测的 scale 与 structure-from-motion 的 scale 进行对齐 。 团队利用通过 Structure from Motion 获得的每个图片的可见 3D 点 P 以及网络预测的深度图 Z 计算 scale factor:

文章图片
获得 scale factor 后 , 对相机的位移进行 scale:

文章图片
需要注意的是 , 由于需要和 ground truth 比较 , 所以在训练和测试时需要做 scale calibration 。 而在部署时不需要做这一步 。
推荐阅读







- bleu|字节跳动火山翻译上新 38 个稀有语种,翻译能力再升级
- Baidu|百度抢跑元宇宙 却默认“输给”字节?
- 字节跳动|抖音上线学习频道,为知识内容增加一级入口
- 字节跳动|抖音正测试“通讯录”功能:神似朋友圈
- 产品|字节入局音乐流媒体,“算法推荐”会带来新“鲶鱼效应”吗?
- 字节跳动|今日头条规范MCN运营 情节恶劣将被拉入黑名单
- 字节跳动|抖音盒子正式上线 盘一盘字节跳动的电商之路
- 字节跳动|新预测称TikTok有望在2022年成为全球第三大社交网络平台
- 最新消息|胡润发布《2021全球独角兽榜》,字节跳动2.3万亿估值跃升榜首
- 字节跳动|电商领域迎来头号玩家 抖音盒子App上线:主打时尚潮品