机器之心专栏
机器之心编辑部
近年来 , 互联网环境中的多媒体内容大量增加 , 如何通过视频文本相互检索 , 提升用户获取信息的效率 , 满足不同的用户对多媒体内容的消费需求变得异常重要 。 随着短视频内容社区的兴起 , 多媒体内容的创作门槛变低 , UGC 内容成为主流 , 视频文本检索任务面临更加复杂和困难的挑战 。 本文针对视频文本检索任务提出层次化对比学习的跨模态检索思路 , 实现了更加高效且精准的视频文本检索方法 , 目前该论文已经被 ICCV2021 接收 。

文章图片
【编码|ICCV2021 | 快手联合北大提出多层次对比学习的跨模态检索方法】论文链接:https://arxiv.org/abs/2103.15049
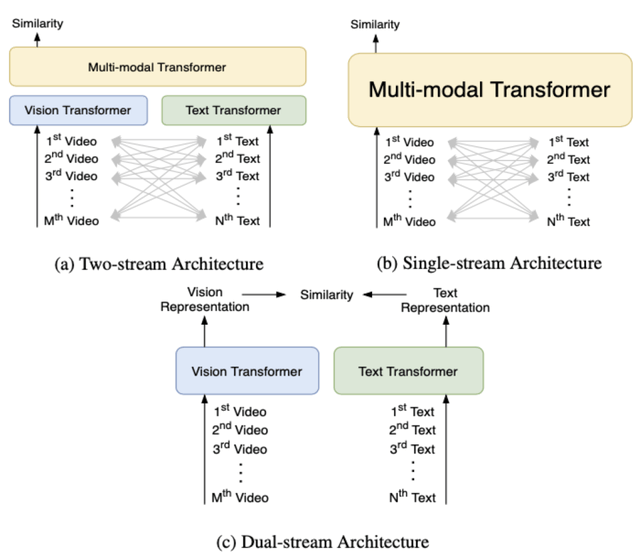
当前主流的视频文本检索模型基本上都采用了基于 Transformer[1] 的多模态学习框架 , 主要可以分成 3 类:
- Two-stream , 文本和视觉信息分别通过独立的 Vision Transformer 和 Text Transformer , 然后在多模态 Transformer 中融合 , 代表方法例如 ViLBERT[2]、LXMERT[3] 等 。
- Single-stream , 文本和视觉信息只通过一个多模态 Transformer 进行融合 , 代表方法例如 VisualBERT[4]、Unicoder-VL[5] 等 。
- Dual-stream , 文本和视觉信息仅仅分别通过独立的 Vision Transformer 和 Text Transformer , 代表方法例如 COOT[6]、T2VLAD[7] 等 。
文章图片
由于类别 1 和类别 2 方法在时间开销上的限制 , 本文提出的 HiT( Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval)[8] 模型采用了类别 3 Dual-stream 的 Transformer 框架 , 以满足大规模视频文本检索的需求 。 然而现有基于 Transformer 的多模态学习方法会有两个局限性:
- Transformer 不同网络层的输出具有不同层次的特性 , 而现有方法并没有充分利用这一特性;
- 端到端模型受到显存容量的限制 , 无法在一个 batch 内利用较多的负样本 。
HiT 模型主要有两个创新点:
推荐阅读







- 最新消息|快手调整员工福利:减少房补、取消免费三餐 新增生育奖金
- 编码|飞利浦发布 Fidelio T1 真无线降噪耳机:圈铁三单元,1699 元起
- 平台|快手:开展“清朗?打击流量造假、黑公关、网络水军”专项行动
- 浏览器|抖音快手去水印在线解析
- 宿华|7年前,快手就注意到视频媒体流在记录和表达上的优势
- 索尼|2021 全球MIPI网络编码控制板首发完美对接索尼fcb-ev9500M摄像头机芯
- 电子商务|辛选回应辛巴起诉快手:只是侵权纠纷 不是真的要“告平台”
- 人物|辛巴起诉快手平台:此前曾吐槽被平台限流、一度账号被封
- 编码|Java on Visual Studio Code的更新 – 2021年11月
- 运营|互联网医疗远未成熟 慢赛道跑不出“快手”